
无限横向扩展
借助并行副本(parallel replicas),ClickHouse 可以让一台拥有 90 个核心的机器与一百台共 9000 核心的集群,执行查询时表现一致。
在云端扩展查询,就像拧动一个旋钮:加节点,速度立刻提升。这就是按需的虚拟分片。
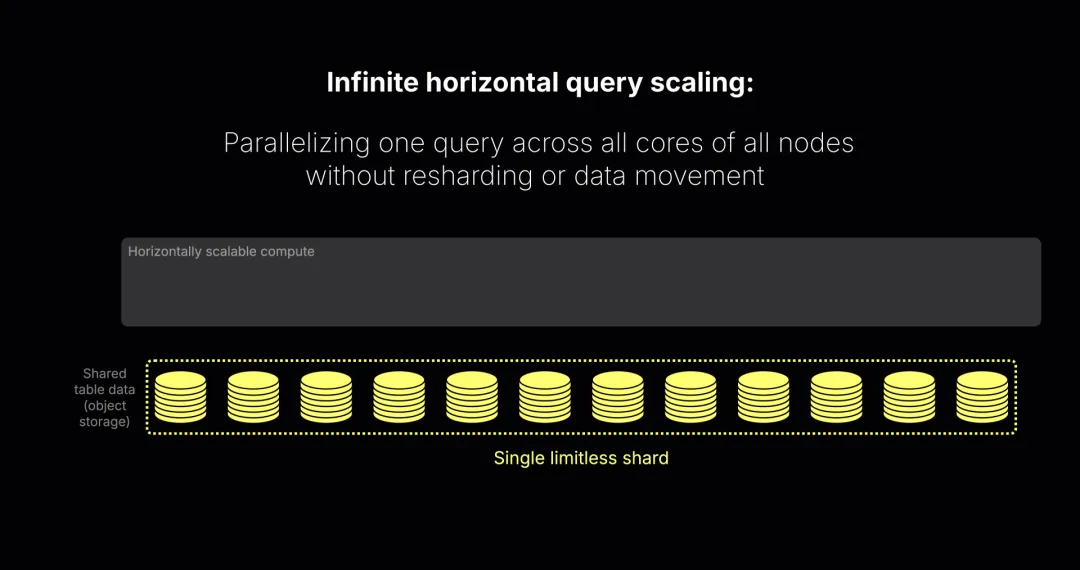
并行副本是开源版中的一个功能,目前处于 beta 阶段(很快将在云端 GA)。有了它,ClickHouse Cloud 获得了零运维开销的水平查询扩展:一个查询不再受限于单个计算节点,而是可以运行在集群中所有节点的所有核心上。这意味着:
弹性 —— 节点一加,查询立刻加速;
简洁 —— 无需数据重分布,只要开启一个选项;
交互速度 —— 即使是 1000 亿行数据,也能在 1 秒内完成。
如果你熟悉 Spark 或传统的云数仓(如 BigQuery、Snowflake),这听起来很像 MPP(大规模并行处理),但 ClickHouse 更轻量。ClickHouse Cloud 会把查询拆分为跨节点的流,避免了传统 MPP 系统常见的重分布和批处理开销。
我们稍后会拆解其工作原理。现在只需记住:并行副本能加速所有可并行化的查询,从简单的 SELECT 到 SUM、AVG 这样的标量聚合。而真正定义分析性能、设定规模基准的核心操作是 GROUP BY。
GROUP BY:分析的心脏
最优雅的系统往往只把一件事做到极致。钢笔的使命就是优雅地把墨迹落在纸上,Unix 工具如 grep 就是完美地完成搜索。ClickHouse 的起点也是如此:让 GROUP BY 比任何系统都快。

“它的设计目标就是解决一个任务:尽可能快地过滤和聚合数据。换句话说,就是把 GROUP BY 做到极致。” —— ClickHouse 发明人 Alexey Milovidov,BDTC 2019
想象一下在数百万、数十亿行数据上运行聚合,快到让你怀疑系统是不是出故障了。这就是我第一次使用 ClickHouse 时的感觉:“肯定出问题了,不可能有这么快,对吗?”
GROUP BY 几乎是所有分析查询的核心。它驱动着可观测性仪表盘,支持把自然语言转为 SQL 的对话式 AI,为客服或代理提供实时分析,以及几乎所有其他分析场景。只要让 GROUP BY 足够快,几乎所有分析任务都会跟着变快。
一项 VLDB 2025 的研究基于真实 BI 工作负载发现:超过一半的查询包含 GROUP BY,再次印证了它在分析中的核心地位。
ClickHouse 正是为此而生。但随着数据规模增长、查询复杂度提升,用户的期望也越来越高。引擎必须确保即使在数百节点的大规模集群中,GROUP BY 依然保持高速。
本文将带你了解 ClickHouse 如何应对这一挑战:先通过一个快速演示,然后深入剖析其执行模型,展示 GROUP BY 如何从单核平滑扩展到上千核心。
ClickHouse 驱动的 GROUP BY 速度
性能讨论常常陷入毫秒和图表。不如换个方式,直接感受“快”意味着什么。我们会在不同规模的数据集上运行同样的 GROUP BY,从单节点的几百万行到跨集群的数千亿行。
从小规模开始:数百万行依然重要
我四年前第一次在 ClickHouse 里跑聚合时,数百万行在我还没反应过来时就完成了,当时真的以为系统出错了。
数百万行在实际工作负载中依然很常见。所以我们先从一个简单的案例开始:对英国房价数据集(截至 2025 年 8 月约 3000 万行,由英国政府持续更新)做一个聚合查询,计算各城镇的销售总额并返回排名前三的结果。
USE uk_base; -- ~30M rowsSELECT town, formatReadableQuantity(sum(price)) AS total_revenueFROM uk_price_paidGROUP BY townORDER BY sum(price) DESCLIMIT 3SETTINGS enable_parallel_replicas = false;单节点(89 核)下的 3000 万行
我们通过 clickhouse-client 在 ClickHouse Cloud 上运行查询,并关闭了并行副本(enable_parallel_replicas = 0)。
说明:这是相同的查询被循环执行。第一次运行速度快到几乎看不见,所以动画会反复播放相同的查询,让你更直观地感受到速度。
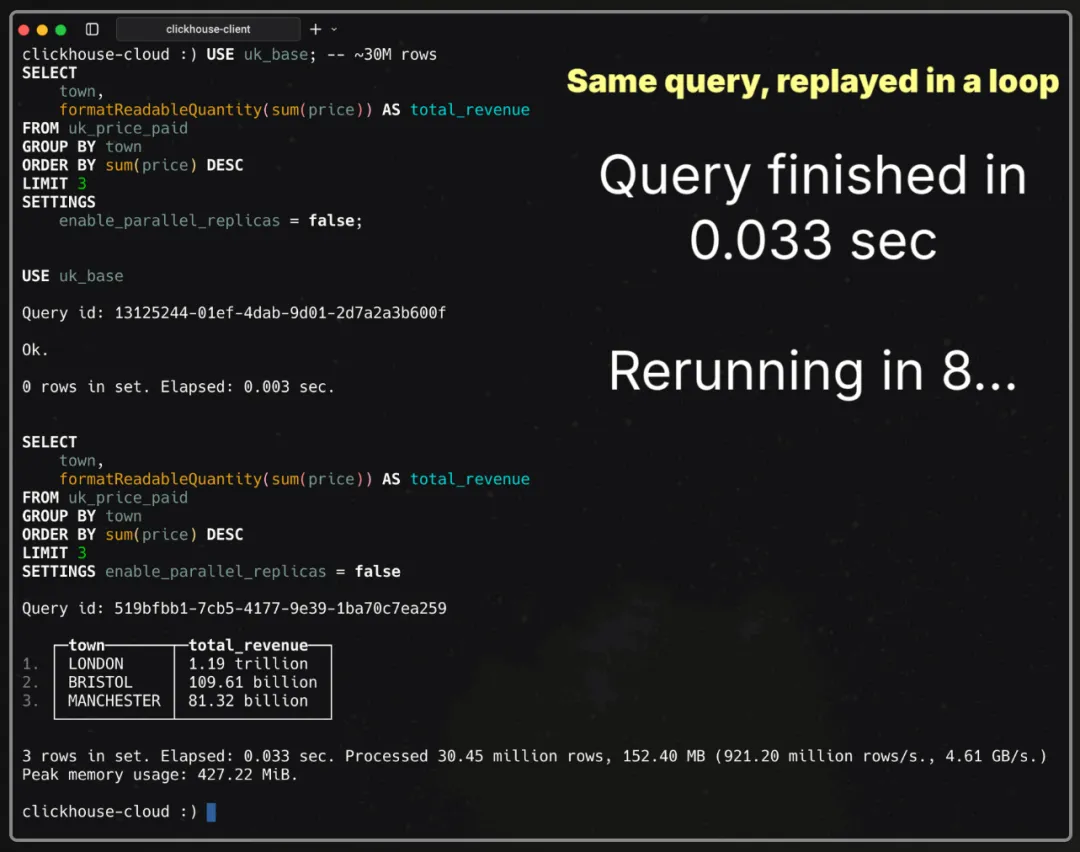
运行时间:33 毫秒
处理行数:3045 万
吞吐量:9.21 亿行/秒,4.61 GB/秒
一次眨眼大约需要 100–150 毫秒。而 33 毫秒的运行时间,相当于眨眼的四分之一,差不多就是相机快门的瞬间。
扩展:十亿级数据已成常态
如今的数据集规模常常以十亿、万亿,甚至千万亿行计。Tesla 在一次负载测试中,曾向 ClickHouse 导入超过一千万亿行数据。
所以我们继续扩展。
10 亿行:眨两次眼
我们在 10 亿行数据集上运行了同样的查询,仍然是单节点 89 核环境:
USE uk_b1; -- 1B rows datasetSELECT town, formatReadableQuantity(sum(price)) AS total_revenueFROM uk_price_paidGROUP BY townORDER BY sum(price) DESCLIMIT 3SETTINGS enable_parallel_replicas = false;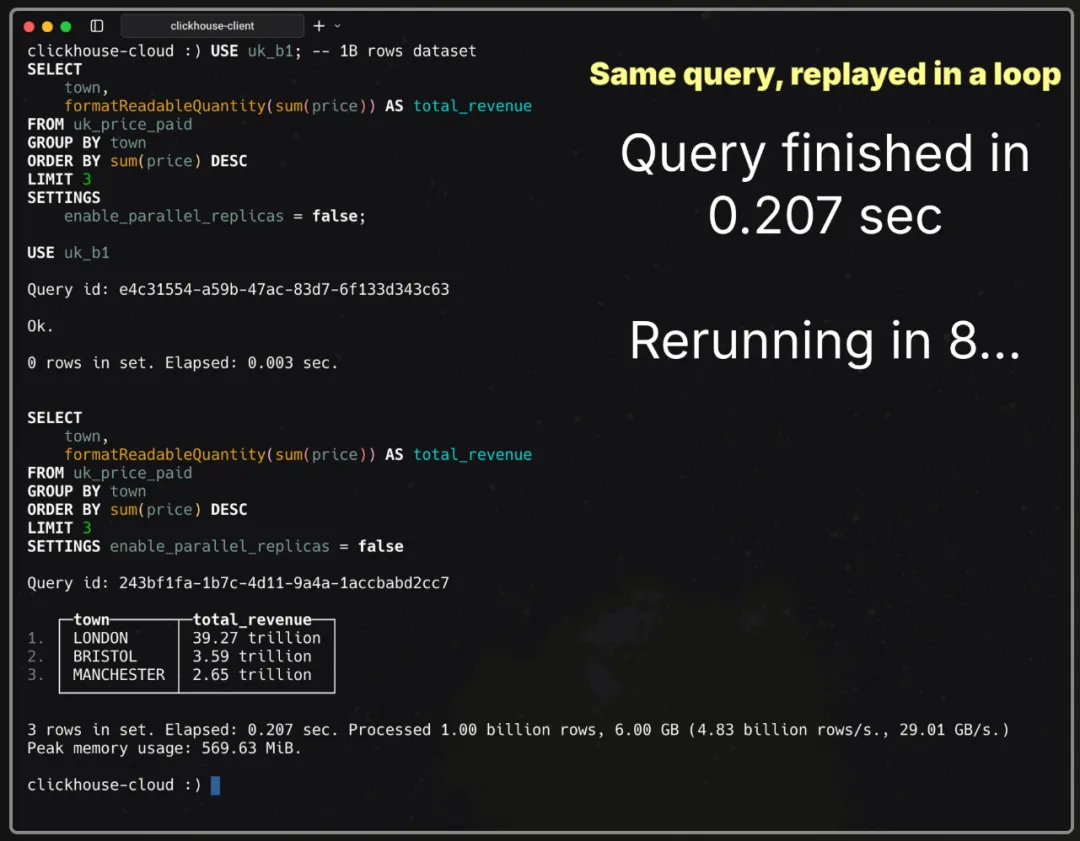
运行时间:207 毫秒
处理行数:10 亿
吞吐量:48.3 亿行/秒,29.01 GB/秒
眨两次眼的时间,就能完成 10 亿行的分组。
1000 亿行:一瞬完成
我们把规模提升到 1000 亿行,在一台 89 核的节点上再次运行同样的查询:
USE uk_b100; -- 100B rows datasetSELECT town, formatReadableQuantity(sum(price)) AS total_revenueFROM uk_price_paidGROUP BY townORDER BY sum(price) DESCLIMIT 3SETTINGS enable_parallel_replicas = false;┌─town───────┬─total_revenue────┐│ LONDON │ 3.92 quadrillion ││ BRISTOL │ 359.61 trillion ││ MANCHESTER │ 266.83 trillion │└────────────┴──────────────────┘3 rows in set. Elapsed: 16.581 sec. Processed 100.00 billion rows, 600.00 GB (6.03 billion rows/s., 36.19 GB/s.)Peak memory usage: 572.19 MiB.结果耗时约 17 秒 🐌。
吞吐量达 60.3 亿行/秒(36.19 GB/秒),表现不错,但运行时间太长,不适合用动画演示。
是时候启动加速模式了 🏎️。
启用并行副本后,相同的查询会在服务中所有节点的所有核心上并行展开:
USE uk_b100; -- 100B rows datasetSELECT town, formatReadableQuantity(sum(price)) AS total_revenueFROM uk_price_paidGROUP BY townORDER BY sum(price) DESCLIMIT 3SETTINGS enable_parallel_replicas = true;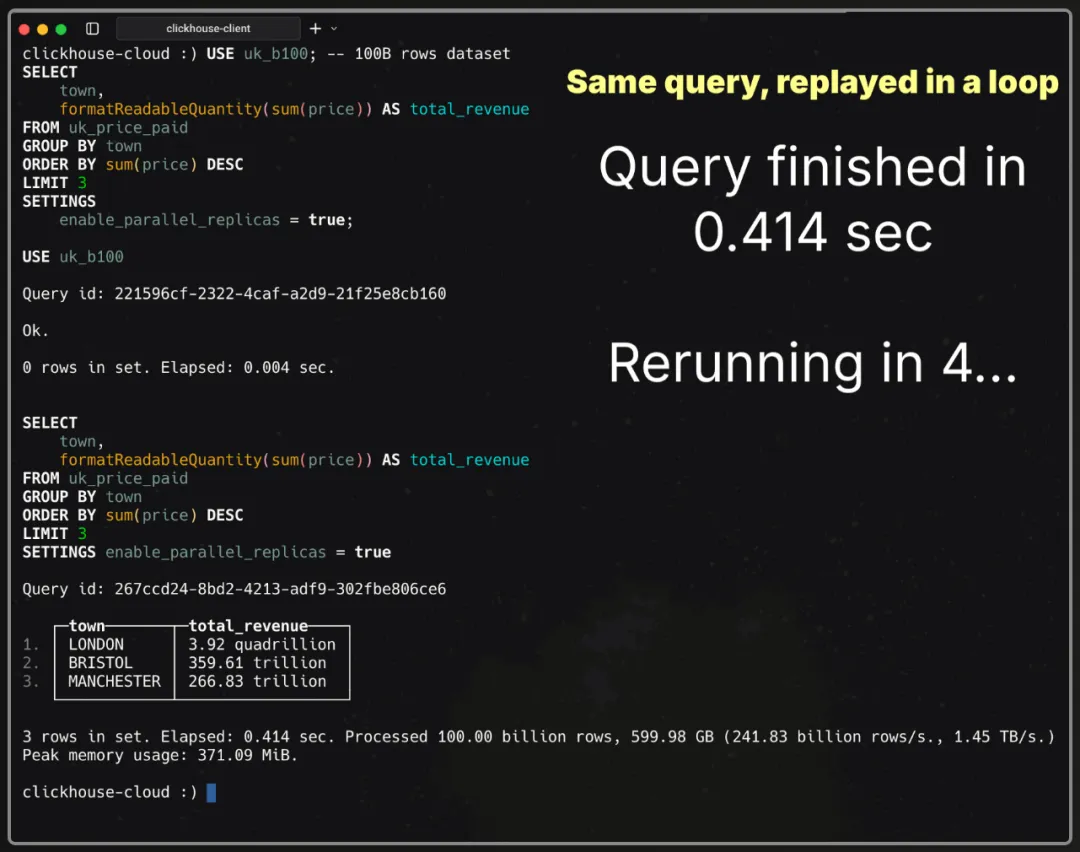
运行时间:414 毫秒
处理行数:1000 亿
吞吐量:2418.3 亿行/秒,1.45 TB/秒
414 毫秒,相当于打个响指或拍一下手的时间。在这短短的瞬间,ClickHouse 已经以超过 1 TB/秒的速度完成了 1000 亿行的聚合。
这就是“亚秒级聚合,TB/秒吞吐”的威力。
那么 ClickHouse 是如何做到的呢?接下来我们从单节点出发,拆解 GROUP BY 为什么能如此之快。
ClickHouse 如何加速 GROUP BY
ClickHouse 的速度秘诀在于:它会将查询并行化到所有 CPU 核心。在查询流水线(物理执行计划)中,每个核心都有一条并行流,就像高速公路上的车道,每条流都负责构建部分聚合状态。
列式存储打下基础
ClickHouse 采用列式存储:查询只读取需要的列,通过高压缩比减少扫描数据量,并在连续数据上执行向量化(SIMD)运算。结果就是 I/O 极低、计算密度极高,为每个核心运行一条并行流提供了理想环境。
每个核心一条流
ClickHouse 会在每个 CPU 核心上启动一条并行流水线流。每条流负责扫描行、应用过滤,并构建部分聚合状态。
查询引擎内部的执行流程如下:
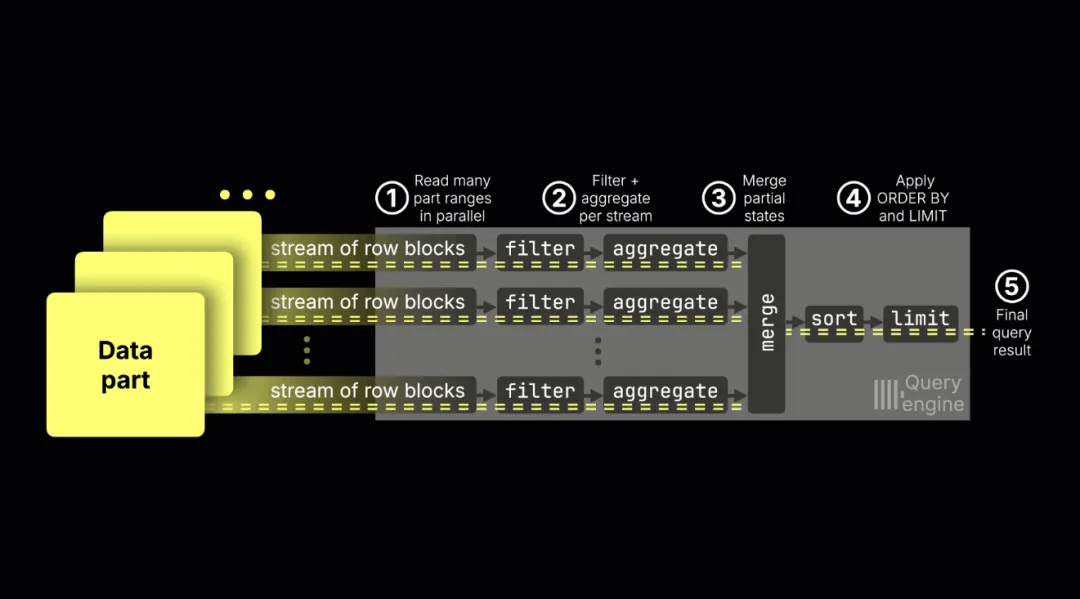
① 同时扫描多个数据分片
通过索引分析选择的连续行块,会被分配到不同的流同时扫描。
② 并行过滤与聚合
每条流处理自己独立的数据范围,利用 SIMD 进行过滤和更新聚合状态。
③ 合并中间结果
所有流生成的部分状态会被汇总为最终结果。这一步不支持流间并行,因此看似是瓶颈,但通常开销较小,因为大部分计算已在聚合阶段完成。如果查询包含多个聚合函数(如 COUNT、SUM、MAX),这些合并会并行执行。
④ 排序与限制
将结果排序,并应用 LIMIT 子句(如果有)。
⑤ 返回结果
最终结果被返回给客户端。
这种架构之所以高效,是因为流水线流并不会直接算出最终结果,而是生成可合并的中间状态,最后汇总为正确答案。
为什么部分状态如此关键
正是部分状态让并行成为可能。
如果没有它们,GROUP BY 就无法高效地在多个核心或多个节点之间拆分。每个核心(或节点)都必须处理某个分组的所有行。而有了部分状态,任何核心(或节点)都可以独立处理任意子集的数据,并输出可合并的中间结果,最终合并为正确答案。
这种机制带来了两大好处:
流水线调度更灵活:数据不需要事先按分组键切分,流可以扫描任意范围;
动态负载均衡:如果某个流遇到数据倾斜,数据行可以被重新分配到其他流,从而保持整体吞吐量;关键在于每个流都能产生可合并的结果。
ClickHouse 支持将 170 多个聚合函数(及其组合器)并行化,不仅在核心内,还能跨节点。
接下来,我们进一步深入查询流水线的聚合阶段。
GROUP BY 执行流水线内部
GROUP BY 查询由每个流水线流独立处理,采用哈希聚合算法:每个流维护一个内存哈希表,每个分组键(例如城镇)对应一个部分聚合状态。
ClickHouse 的哈希表
ClickHouse 并不是只用一种哈希表,而是实现了 30 多种专门的变体,并根据分组键类型、基数、工作负载等条件自动选择。
正如 CMU 的 Andy Pavlo 所说:“ClickHouse 是个非常独特的系统 —— 你们居然实现了 30 种哈希表!” 也正是对底层细节的这种极致追求,让 GROUP BY 的性能如此出众。
以下演示了一个“按城镇计算平均价格并排序”的查询过程:
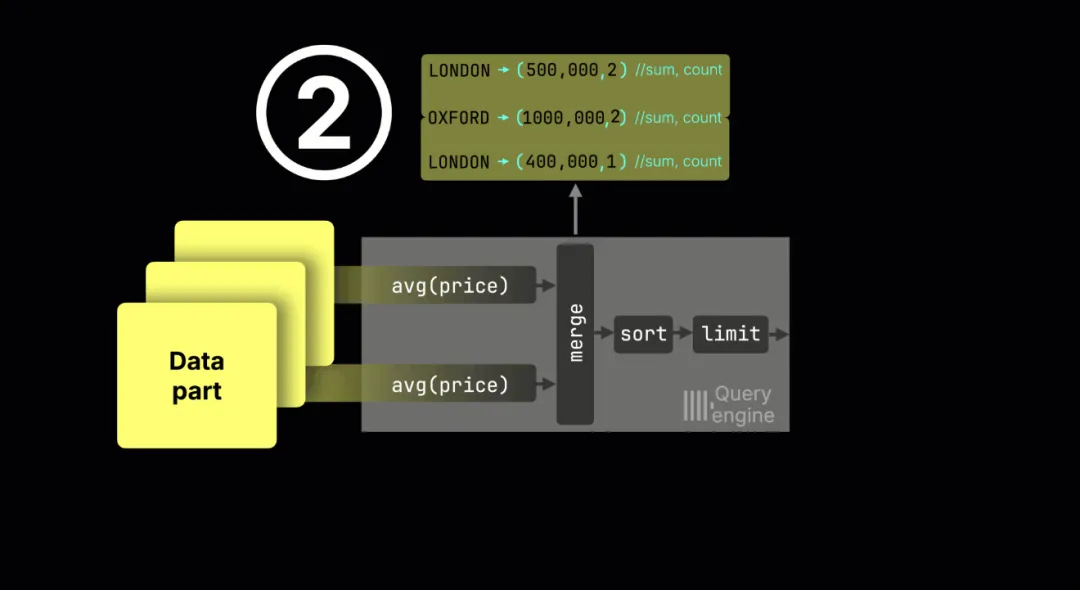
① 各流独立聚合
流 1: London → (sum=500k, count=2); Oxford → (sum=600k, count=1)
流 2: Oxford → (sum=400k, count=1); London → (sum=400k, count=1)
(实际上流是并行运行的,这里顺序展示只是为了说明。实际中,哈希表会存储指针,指向共享内存区域中的聚合状态。)
② 合并部分结果
求和和技术合并的全局结果如下:
Oxford: (600k+400k) / (1+1) = 500k
London: (500k+400k) / (2+1) = 300k
为什么不能直接把均值再平均?
例如流 1 里 London=250k,流 2 里 London=400k,简单平均=325k,这是错误的。正确方法是合并总和和计数,得到 300k。
③ 排序 + 限制
合并后的分组被排序、应用 LIMIT,并返回最终结果。
优雅的并行
总结来说,部分状态既保证了独立性,也保证了正确性:
独立性:任意流水线流都能处理任意数据行;
正确性:合并后的结果每次都保证是正确的。
这就是 ClickHouse GROUP BY 的核心:既高效又正确的并行。
GROUP BY 部分状态的内存
分组键的基数(如城镇数量)决定了内存峰值:唯一值越多,哈希表就越大。
ClickHouse 提供了多种优化手段:
如果分组键是表排序键的前缀,数据可以顺序扫描并聚合,每个流一次只处理少量分组,完成后将结果推送到后续阶段。这能显著降低内存消耗,但会限制并行性,因此默认关闭;
如果内存不足,ClickHouse 会把部分状态溢写到磁盘。
内存占用还与聚合函数相关:
很小的状态:sum, count, min, max, avg(仅一两个数字);
中等状态:groupArray(有限数组);
较大的状态:uniqExact(存储所有唯一值或其哈希,通过并集合并)。
这些差异既影响内存占用,也影响跨节点的扩展效率,这是后续会重点讨论的主题。
这些优化叠加在一起,使 GROUP BY 的性能既能随着核心数的增加而提升,也能随着节点规模的扩展而增强。接下来,我们对这一点进行测量。
测试方法
为了保证结果清晰、可复现,我们在所有基准测试中采用了统一的设置。测试覆盖了不同规模的 ClickHouse Cloud 服务,从单节点到启用并行副本的多节点集群。所有测试均使用相同的数据集和查询,以便单独观察扩展效果并进行公平对比。
这些基准测试完全可复现。相关代码已开源在公共 GitHub 仓库,可以针对任意数据集或查询集运行。该框架既支持纵向扩展(单节点增加核心数),也支持横向扩展(增加节点数),并内置了一个用于生成大规模英国房价数据集的工具。
生成器的原理是复制现有数据行。虽然看起来有些“人工”,但由于测试查询的 GROUP BY 键(县、城镇、区)保持不变,因此结果扩展与真实情况一致(例如 Oxford 即便有更多房屋交易,也仍然是同一个城镇)。
我们的测试环境包括:
一个运行 ClickHouse v25.6 的 ClickHouse Cloud 服务,部署在 AWS us-east-2 区域,节点数量可变;
一台专用的 EC2 m6i.8xlarge 实例(32 vCPU,128 GB 内存,位于同一区域),通过 clickhouse-client 执行基准测试。
在每种配置下,每个查询运行 10 次,我们记录三类结果:
cold —— 首次运行(缓存关闭);
hot —— 最快的一次暖运行;
hot_avg —— 多次暖运行的平均值。
为了简洁展示,本文仅呈现 hot 结果;完整数据(包含 cold、hot、hot_avg)以及并行副本的详细执行情况已在仓库提供。
环境准备好后,我们开始观察结果,首先是纵向扩展 —— 即 GROUP BY 在单节点上如何随着核心数增加而提升性能。
纵向扩展 GROUP BY(增加单节点核心数)
扩展其实很简单:在 ClickHouse Cloud 中,计算与存储是解耦的,这意味着你可以轻松调整节点的 CPU 配置。ClickHouse 会自动在所有核心上并行执行 GROUP BY。核心越多,查询越快。
单节点并行扩展是否有效?
下图展示了在单节点上运行 100 亿行 GROUP BY 查询时,核心数增加对性能的影响:
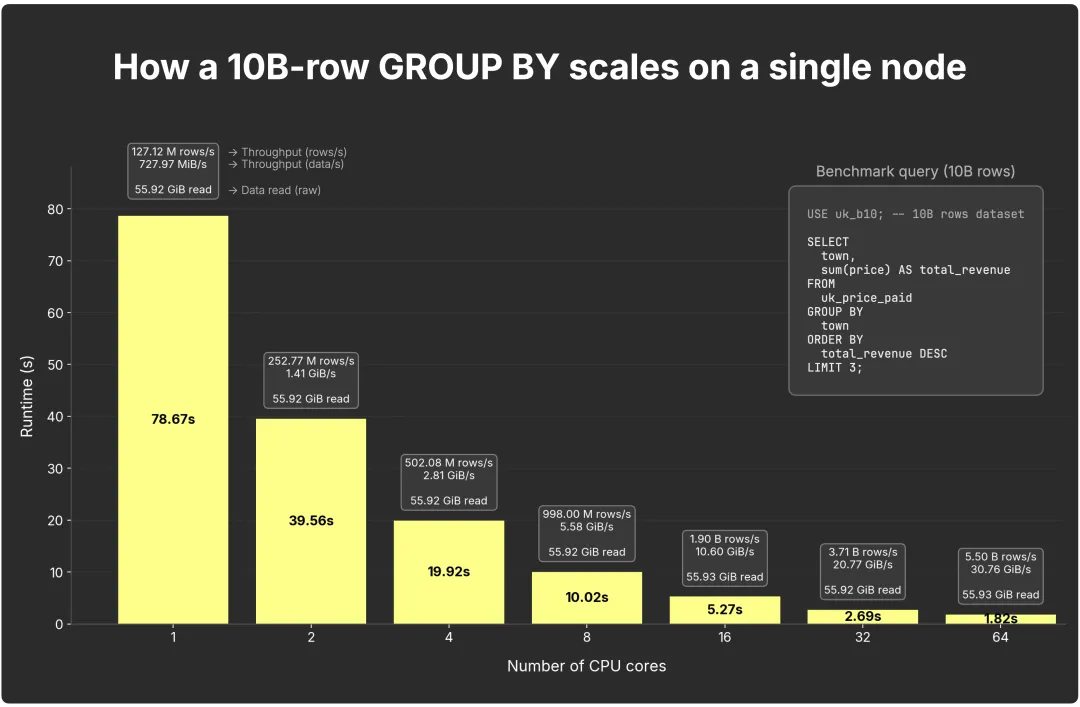
完整结果(包括行数、字节和耗时的详细分解)已发布在基准测试的 GitHub 仓库(https://github.com/ClickHouse/examples/blob/3b6da4b0d0607d4debe5783021ffd2019058637e/blog-examples/ParallelReplicasBench/results/2025-08-30_vert_uk_b10_n1_c1-2-4-8-16-32-64-89_r10_nocachedrop/summary_matrix-nodes-1_cores-1_2_4_8_16_32_64_89_2025-08-30_130631.json)。
在仅使用 1 个核心时,查询完成耗时 78.7 秒,整体速率约为 1.27 亿行/秒(约 728 MiB/秒)。当核心数翻倍时,运行时间几乎减半,吞吐量也随之提升:
2 核:39.6 秒,2.53 亿行/秒(1.4 GiB/秒)
4 核:19.9 秒,5.03 亿行/秒(2.8 GiB/秒)
8 核:10.0 秒,9.98 亿行/秒(5.3 GiB/秒)
16 核:5.3 秒,19 亿行/秒(10.6 GiB/秒)
32 核:2.6 秒,37 亿行/秒(20.7 GiB/秒)
64 核:1.9 秒,55 亿行/秒(30.6 GiB/秒)
总结:GROUP BY 的性能几乎随核心数线性提升。每个核心处理一部分数据,并构建对应的中间状态,ClickHouse 引擎会高效地将这些状态合并。
纵向扩展的瓶颈
接下来我们查询 100 亿行数据集里每个(县、镇、区)的聚合结果:
COUNT() —— 房产销售数量
SUM(price) —— 总销售额
AVG(price) —— 平均售价
查询结果按总销售额排序,返回前 10 个地区或最赚钱的区域。
USE uk_b10; -- 10B rows datasetSELECT county, town, district, formatReadableQuantity(count()) AS properties_sold, formatReadableQuantity(sum(price)) AS total_sales_value, formatReadableQuantity(avg(price)) AS average_sale_priceFROM uk_price_paidGROUP BY county, town, districtORDER BY sum(price) DESCLIMIT 10SETTINGSenable_parallel_replicas = false;
在一台 89 核的节点上,运行时间为 14.4 秒(约 6.92 亿行/秒)。虽然速度不算差,但对于仪表盘或临时分析场景,14 秒显得太久,不够交互式。
大约相当于你系鞋带、等红灯,或者用微波炉加热一片披萨的时间(向意大利读者致歉)。
对于这种基数固定的场景(英国的县或城镇数量不会增加),使用增量物化视图是最佳选择。按地理维度预聚合可以大幅减少数据量,并保证毫秒级响应。
物化视图:将中间状态存储到磁盘
ClickHouse 的增量物化视图进一步扩展了部分聚合状态的概念:不是在查询时重新计算,而是在数据写入时就捕获聚合状态,把它们存储在数据分片里,并通过后台合并任务持续更新。可以理解为聚合逻辑在后台流水线中持续运行。我们将在后续文章里详细介绍。
当然,预聚合并非适用于所有场景。在可观测性(observability)中,每一条日志都可能被分析,临时查询可能会跨越任意维度;当分组基数不固定时,也无法提前聚合。此时只能依靠算力:当一台“大家伙”,即使有 89 核,也不够用时,就只能选择横向扩展 —— 这正是并行副本发挥作用的地方。
横向扩展 GROUP BY(并行副本)
横向扩展在 ClickHouse Cloud 中同样非常容易。因为计算和存储解耦,你可以随时增加新的计算节点,它们会立即加入集群。
与传统的物理分片不同,ClickHouse Cloud 中所有节点都从对象存储中的同一个无限分片读取数据,相当于虚拟副本。启用并行副本功能后,这些节点会成为同一查询的额外并行处理流。节点越多,查询越快。一个协调器负责调度,在运行时将数据动态分片分配到各个节点 —— 就像一种“按需虚拟分片”。
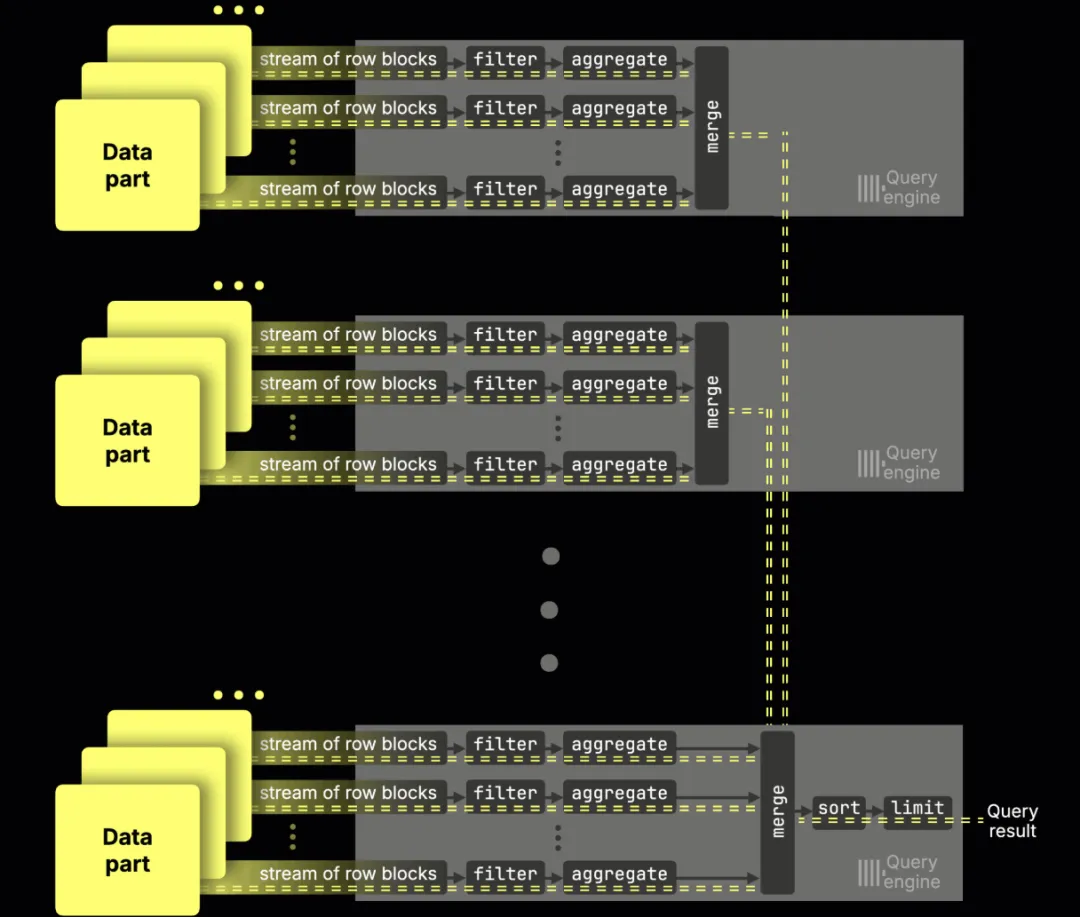
(该功能目前在 ClickHouse Cloud 中处于 beta 阶段;你现在就可以在部分工作负载中启用它,GA 很快就会上线。)
在没有并行副本(parallel replicas)的情况下,一个 GROUP BY 查询只能利用单个节点的核心数(本实验环境为 89 核)。启用并行副本后,所有节点的核心都会参与同一个查询:
默认 3 节点:从 89 核扩展到 267 核;
10 节点:890 核;
20 节点:1780 核;
100+ 节点:8900+ 核,35,600+ GiB 内存。
整个过程无需分片或数据迁移,只需增加无状态计算节点即可完成。只要点击一次,或调用一个 API,就能实现。
本文实验规模停在 100 节点;至于“能扩展到多远”,我们会在并行副本 GA 后发布单独的深度分析。
提示:并行副本不仅能加速 GROUP BY,还能加速标量聚合和普通 SELECT。对于标量聚合(如不带 GROUP BY 的 SUM/AVG),计算节点会构建、发送并合并相同的中间结果;对于非聚合的 SELECT,节点并行处理数据并返回子结果,协调器再完成最终的排序与 LIMIT。
工作在副本间如何拆分
下图展示了 100 亿行 GROUP BY 在多节点间的扩展情况(每个节点 89 核):
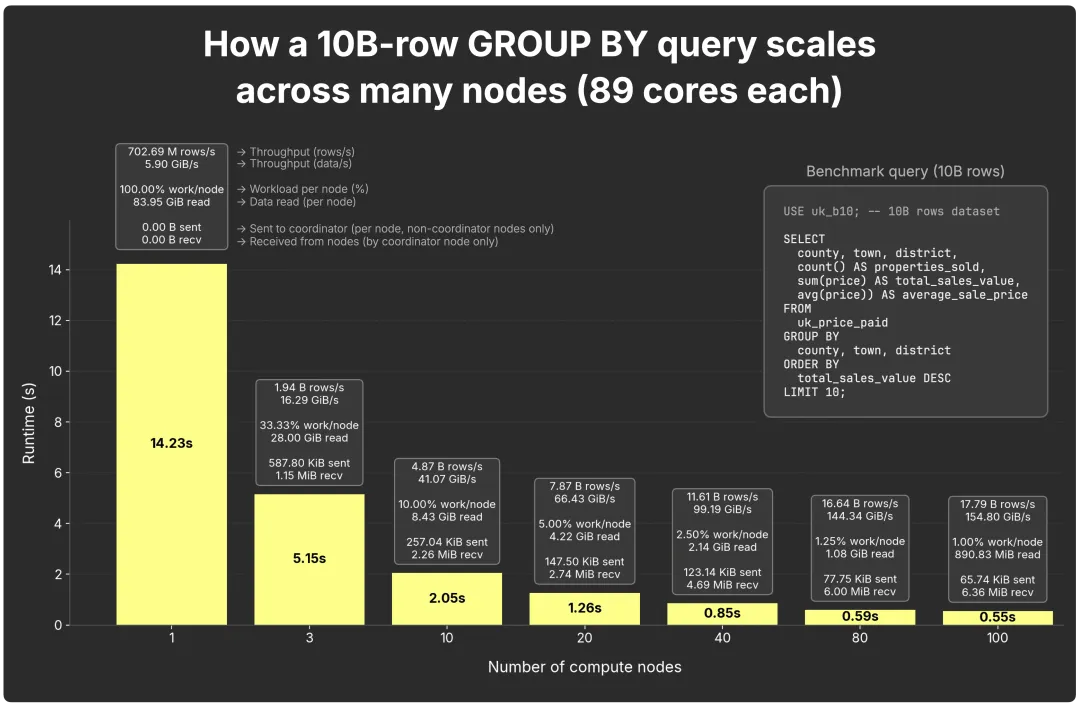
单节点:14.2 秒,约 7.03 亿行/秒(5.9 GiB/秒):
3 节点:5.2 秒;
10 节点:2.0 秒;
20 节点:1.3 秒;
40 节点:0.85 秒;
80 节点:0.56 秒;
100 节点:0.55 秒。
图表还展示了每个节点的参与度、每节点读取的未压缩数据量,以及网络流量(每个节点将中间结果发送给协调器,由协调器收集并合并)。
从更深入的指标来看:我们的基准测试还跟踪了更多细节,包括每个节点处理的行数、扫描的压缩/未压缩字节数、内存使用情况、扫描与聚合耗时,以及冷/暖/热状态。为了让图表更简洁,这里省略了这些细节,完整结果可在 GitHub 仓库查看。(https://github.com/ClickHouse/examples/tree/main/blog-examples/ParallelReplicasBench)
需要注意的是,扩展效果并非严格线性。节点数翻倍并不总能让运行时间减半,但表现接近。例如,单节点需扫描 ~84 GiB;3 节点时为 ~28 GiB;10 节点时为 ~8 GiB。当扩展到 80–100 节点时,每个副本仅需处理 ~1 GiB 或更少,此时协调开销(例如网络传输中间结果到协调器)开始占据主导,使得在小规模数据集上的扩展效率逐渐下降。
在 1 万亿行数据上的扩展
当单节点的任务量过小,无法抵消并行副本带来的协调开销时,扩展曲线就会开始变缓。为了验证这一点,我们在相同配置的计算节点(每个 89 核)上,使用放大 100 倍的数据集 —— 共 1 万亿行 —— 重新运行了相同的查询。

在节点数较少时,每个节点负载极高:单节点需要扫描和聚合 8.2 TiB 数据,即便是 3 个节点,每个节点仍需接近 3 TiB。
当节点数增加到 10 个时,每个节点的读取量降至约 910 GiB,扩展效果开始显现。之后节点数翻倍时,性能提升接近甚至超过线性预期:
10 → 20 节点:提速 2.02 倍
20 → 40 节点:提速 2.28 倍
40 → 80 节点:提速 2.17 倍
80 → 100 节点:提速 1.39 倍(优于线性预期的 1.25 倍)
即使在 100 节点规模下,每个副本仍需处理约 90 GiB 数据,工作量足以摊薄协调开销,因此整体扩展依旧保持强劲。
当然,在 1 万亿行数据集上,扩展规模完全可以继续突破 100 节点。但正如前文提到的,我们会把“究竟能扩展到多远”的深度测试留到并行副本 GA 后再展开。
同时需要注意,并行副本的效率还与部分聚合状态的大小密切相关 —— 我们将在下一节深入分析这一点。
当 GROUP BY 负载加重时
并不是所有的 GROUP BY 都一样。前面展示的 SUM、AVG 属于轻量聚合,中间计算状态很小。但当 GROUP BY 变得更复杂时,比如 COUNT DISTINCT,情况就不同了 —— 此时部分状态的大小开始变得关键。
为了说明这一点,我们在一个包含 100 亿行的数据集上做了实验,统计每个季度、每个县中有销售的不同街道数量。
USE uk_b10; -- 10B rows datasetSELECT county, toStartOfQuarter(date) AS qtr, uniq(street) AS distinct_streets_with_salesFROM uk_price_paidGROUP BY county, qtrORDER BY qtr, county;查询本身很简单,真正起决定作用的是聚合函数的选择。
说明:这个基准测试重点对比不同聚合函数产生的中间状态大小。由于这是一个全新的 GROUP BY 查询(不同于之前的测试),我们在 16 核节点上运行,而不是 89 核节点,借此也展示出无论核心数多少,并行副本都能保持高效扩展。
轻量场景:uniq
uniq 聚合函数是近似去重,但非常高效。它采用自适应采样(最多 65,536 个哈希),保证中间状态紧凑。

每个节点发送的状态:从约 58 MiB/节点(3 节点场景下 2 个发送节点)缩减到约 4.2 MiB/节点(100 节点时)。
协调器接收的总量:从约 115 MiB(2×58 MiB,3 节点)到约 416 MiB(99×4.2 MiB,100 节点)。
→ 随着节点增加,协调器的输入压力保持较小,每个节点的网络流量也逐渐降低。
重负载场景:uniqExact
uniqExact 聚合函数计算真实的 COUNT DISTINCT。中间状态明显更大,因为每个节点都必须保存它遇到的所有不同值,根据类型以原始值或哈希存储,最后再由协调器合并。
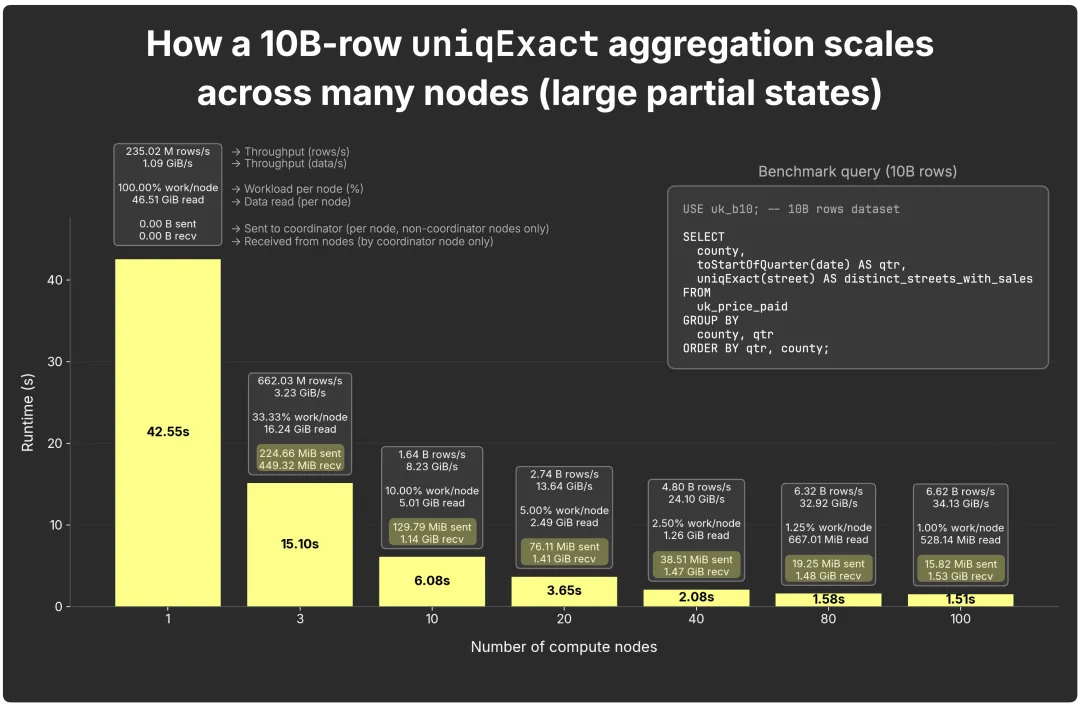
每个节点发送的状态:从约 225 MiB/节点(3 节点场景下 2 个发送节点)缩减到约 16 MiB/节点(100 节点时)。
协调器接收的总量:从约 450 MiB(2×225 MiB,3 节点)到约 1.5 GiB(99×16 MiB,100 节点)。
与 uniq 相比,状态体积大约增加了 4 倍,因此网络传输和合并时间更突出,尽管整体运行时间仍有所提升。
需要注意的是:uniqExact 的状态大小取决于基数。在我们的数据里,(县、季度)维度下的唯一街道数最多约 17k,并保持稳定,因此这个例子算是“温和”的情况。
基数挑战:如果唯一值数量急剧膨胀(例如对数十亿用户执行 uniqExact(user_id),或对全网执行 uniqExact(url)),那么状态体积可能比 uniq 大出几个数量级,网络开销也会随之急剧增加。
关于 distinct 的结论
并行副本可以扩展全部 170 多种聚合函数,但效率很大程度上取决于中间状态的大小:
轻量状态(如 sum、count、uniq):扩展效果良好。
重型状态(如 uniqExact):也能扩展,但需要更多网络带宽和合并时间。
折中方案(如 uniqHLL12):固定状态大小约 2.5 KB,在 1 万–1 亿去重值范围内误差约 1–2%;在小数据集上准确性不足,在超过 1 亿时性能下降,但在部分场景下是很实用的平衡方案。
复杂聚合依然可以扩展,但更大的中间状态意味着更高的网络和合并开销。是否值得做这种权衡,取决于每个节点需要处理的数据量。这也引出了 ClickHouse 为保持并行副本高效而设定的保护机制。
扩展的限制与安全机制
并不是说给查询增加更多节点,它就一定会更快。
在较小的数据集(例如 100 亿行)上,并行副本(parallel replicas)在节点数量较少时扩展良好,但当节点数增加过多时,部分节点可能没有足够的任务可做,反而让协调开销变成瓶颈。
在超大规模数据集(例如 1 万亿行)上,情况正好相反:节点数太少会导致单个节点压力过大,而当节点数增加时,每个节点仍然有大量数据要处理,因此协调成本是值得的,整体扩展效果反而更好。
为了让并行副本保持高效,ClickHouse 提供了两项关键的保护机制:
parallel_replicas_min_number_of_rows_per_replica —— 只有当分配到单个节点的行数超过一定阈值时,才会把该节点作为并行副本启用,以避免不必要的开销。
max_parallel_replicas —— 限制单次查询中可使用的并行副本节点的最大数量(默认值为 1000)。
在执行过程中,查询规划器会预估 rows_to_read(例如通过索引分析),即查询实际需要扫描和处理的行数。结合以上两个设置,系统会决定是否启用并行副本,以及最多使用多少节点:
启用规则:只有当满足最小行数阈值时,查询才会启用并行副本。
rows_to_read >= 2* parallel_replicas_min_number_of_rows_per_replica否则查询会在单节点上运行。
限制规则:即便启用了并行副本,实际使用的节点数量(number_of_replicas_to_use)仍会受到 max_parallel_replicas 的上限控制。
rows_to_read / parallel_replicas_min_number_of_rows_per_replica(still capped by min(cluster size, max_parallel_replicas))如果结果值 ≤ 1,并行副本同样不会启用,查询将回退为单节点执行。
换句话说:小数据集不会启用并行副本;大数据集会使用,但只会在保证每个节点都有足够工作时才扩展。
示例:假设某个查询需要读取 100 亿行数据,max_parallel_replicas = 100,而 parallel_replicas_min_number_of_rows_per_replica = 10 亿。
启用规则(Enable rule):仅当总行数 ≥ 2 × parallel_replicas_min_number_of_rows_per_replica,才会启用并行副本;
限制规则(Limit rule):允许参与的节点数 = rows_to_read ÷ parallel_replicas_min_number_of_rows_per_replica,最多不超过 max_parallel_replicas。
每个节点处理约 10 亿行,资源利用率良好,协调成本合理。
默认行为:默认情况下,parallel_replicas_min_number_of_rows_per_replica = 0,即禁用保护机制。此时所有查询默认启用并行副本,受 max_parallel_replicas 或集群规模约束。但这在小数据集场景下可能造成不必要的协调开销,因此建议在生产中根据实际任务配置合理阈值。也可通过 enable_parallel_replicas 选项在每条查询中显式控制其行为,并可覆盖查询级别的 max_parallel_replicas。
总结:这些机制共同确保并行副本仅在真正能加速查询的前提下启用,避免无效扩展带来的资源浪费。
接下来,我们将深入探讨:并行副本是如何在底层将查询任务动态分配到多个节点上的。
并行副本是如何分配任务的
(我们已发布过一份关于并行副本任务分配机制的详尽指南(https://clickhouse.com/docs/deployment-guides/parallel-replicas),这里仅对关键原理进行简要总结。)
在 ClickHouse Cloud 中,接收到查询的节点(由负载均衡器选择)将作为该查询的“协调器”。值得注意的是,协调器本身也会作为完整的并行副本参与执行,与其他节点无异,这一点在前文动画中已有展示。
当查询到达后,协调器会将查询拆分为多个 granule(ClickHouse 中的最小处理单元,默认为约 8,192 条连续行),这些 granule 是通过索引分析得出的。协调器将 granule 分配给所有参与节点,包括自身。
每个副本节点在本地扫描分配到的 granule,计算对应的部分聚合状态,并将这些状态通过流的形式返回给协调器。协调器随后对所有结果进行合并,最终返回查询结果。
这种 granule 机制实现了细粒度的负载均衡:
动态协调:副本完成当前任务后可继续请求下一个 granule,性能更高的副本自然会处理更多数据;
任务抢占(Task stealing):如果某个副本处理缓慢,其他副本可以接手其未完成任务 ;
缓存命中率优化:借助一致性哈希算法,相同的 granule 会在重复查询中由相同节点处理,从而复用缓存。该特性在节点总数 ≤ max_parallel_replicas 时效果最佳,否则节点分配将是随机的
介绍完底层机制,我们再从整体角度看看 GROUP BY 在 ClickHouse Cloud 中的扩展方式。
GROUP BY 的云端演进
在 ClickHouse Cloud 中,GROUP BY 现在可以通过两种互补方式在节点集群间实现弹性扩展:
跨查询扩展(Inter-query scaling):增加更多节点,就能同时运行更多查询。负载均衡器会将请求分发到更大的计算池中,因此随着集群规模的扩大,整体吞吐量也会相应提升;
查询内扩展(Intra-query scaling,本篇重点):通过把一个查询拆分到多个节点并行执行来提升速度。启用并行副本(parallel replicas)后,ClickHouse 会充分利用所有节点的所有 CPU 核心来加速查询。
在开源版 ClickHouse 中,单个查询同样可以通过分片(sharding)或并行副本来扩展。分片会把数据分布到多个节点,但如果要增加容量,就必须重新分片(resharding),可能耗时数小时甚至数天。并行副本也能发挥作用,但在无共享架构(每个节点独立存储数据)下,需要完整的物理副本。
而在云端,这个模式的优势更加明显:计算与存储彻底解耦,每个节点都像一个无状态的虚拟副本,从共享对象存储中读取数据。节点可以随时添加或移除,不需要复制或重新分布数据,而单个查询的提速只需轻轻启用一个功能即可。
云端还带来了更多优势。分布式缓存让热点数据紧贴计算节点,从而加速整个集群内的重复查询。共享目录(Shared Catalog)集中管理数据库元数据,使新节点能够在几秒内上线。同时,GROUP BY 还能无缝支持 Iceberg、Delta Lake 等开放表格式以及 ClickHouse 原生表。
对外部格式的查询同样采用本文介绍的部分聚合状态执行模型。在原生表中,并行副本会按照数据粒度划分任务;而在外部格式下,则需要使用这类 …Cluster 函数 —— 如 s3Cluster、azureBlobStorageCluster、deltaLakeCluster、icebergCluster 等 —— 它们会以文件为单位拆分任务(例如 Iceberg 中的 Parquet 文件)。
换句话说,无论数据位于原生表还是外部开放格式中,ClickHouse Cloud 都能将 GROUP BY 扩展到所有无状态计算节点,并依旧保证交互级别的查询速度。
从单机到云端的演化
本文记录了我从第一次使用 ClickHouse 查询时的震惊——“怎么可能这么快?”——到见证这一性能模型无缝扩展至整个云端集群的全过程。
GROUP BY 是分析型查询的核心,驱动着可观测性、对话式 AI、智能分析等各种场景。
ClickHouse 的核心目标就是高效执行 GROUP BY。在云端,这一设计进一步演进:借助并行副本(parallel replicas,ClickHouse Cloud 中的开源功能,目前处于 beta,很快将正式 GA),原本的“每核心一条处理流”架构被拓展为无限横向扩展,使单个查询能够在所有节点的全部核心上并行运行,而无需重新分片或数据迁移。其结果是,无论数据规模还是数据形态如何,ClickHouse Cloud 都能保持交互级别的查询速度。
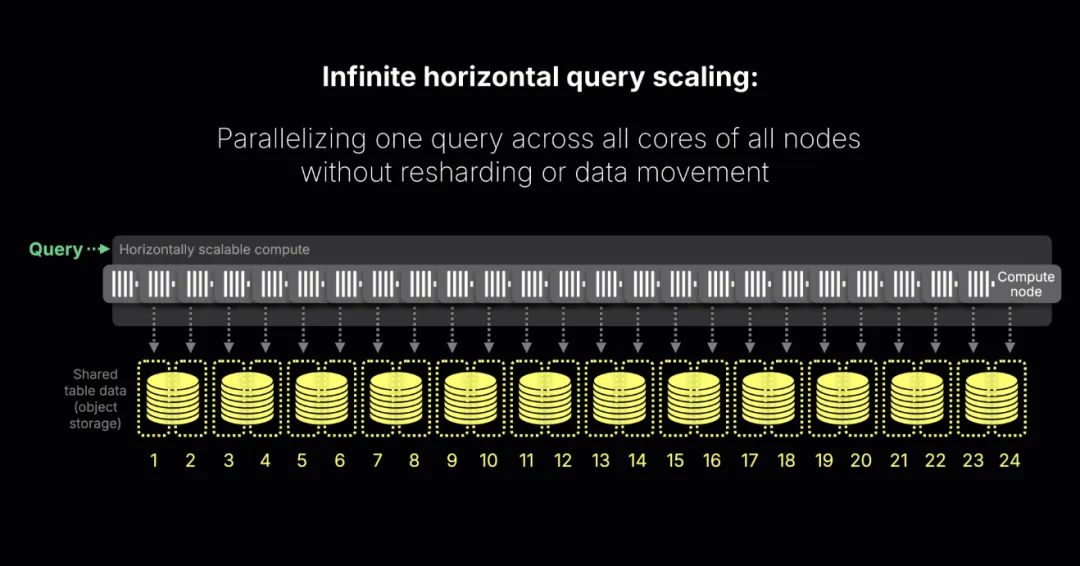
它的核心哲学仍然是简洁而高效:每个处理流负责构建可合并的部分状态,最后统一汇总为准确结果。
就像那支优雅的钢笔一样,ClickHouse 始终专注于将 GROUP BY 做到极致——如今,它不仅在本地飞快,在云端也同样表现出色,规模无上限。
目前,并行副本功能在 ClickHouse Cloud 中已进入 beta 阶段,即将全面 GA。你现在就可以在部分工作负载中启用它,亲自体验这种飞跃式的查询速度提升。
/END/

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出 &图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com。





