

数据库作为核心的基础组件,是需要重点保护的对象。任何一个线上的不慎操作,都有可能给数据库带来严重的故障,从而给业务造成巨大的损失。为了避免这种损失,一般会在管理上下功夫。比如为研发人员制定数据库开发规范;新上线的 SQL,需要 DBA 进行审核;维护操作需要经过领导审批等等。而且如果希望能够有效地管理这些措施,需要有效的数据库培训,还需要 DBA 细心的进行 SQL 审核。很多中小型创业公司,可以通过设定规范、进行培训、完善审核流程来管理数据库。
随着美团的业务不断发展和壮大,上述措施的实施成本越来越高。如何更多的依赖技术手段,来提高效率,越来越受到重视。业界已有不少基于 MySQL 源码开发的 SQL 审核、优化建议等工具,极大的减轻了 DBA 的 SQL 审核负担。那么我们能否继续扩展 MySQL 的源码,来辅助 DBA 和研发人员来进一步提高效率呢?比如,更全面的 SQL 优化功能;多维度的慢查询分析;辅助故障分析等。要实现上述功能,其中最核心的技术之一就是 SQL 解析。
现状与场景
SQL 解析是一项复杂的技术,一般都是由数据库厂商来掌握,当然也有公司专门提供SQL解析的API。由于这几年 MySQL 数据库中间件的兴起,需要支持读写分离、分库分表等功能,就必须从 SQL 中抽出表名、库名以及相关字段的值。因此像 Java 语言编写的 Druid,C 语言编写的 MaxScale,Go 语言编写的 Kingshard 等,都会对 SQL 进行部分解析。而真正把 SQL 解析技术用于数据库维护的产品较少,主要有如下几个:
美团开源的SQLAdvisor。它基于 MySQL 原生态词法解析,结合分析 SQL 中的 where 条件、聚合条件、多表 Join 关系给出索引优化建议。
去哪儿开源的Inception。侧重于根据内置的规则,对 SQL 进行审核。
阿里的Cloud DBA。根据官方文档介绍,其也是提供 SQL 优化建议和改写。
上述产品都有非常合适的应用场景,在业界也被广泛使用。但是 SQL 解析的应用场景远远没有被充分发掘,比如:
基于表粒度的慢查询报表。比如,一个 Schema 中包含了属于不同业务线的数据表,那么从业务线的角度来说,其希望提供表粒度的慢查询报表。
生成 SQL 特征。将 SQL 语句中的值替换成问号,方便 SQL 归类。虽然可以使用正则表达式实现相同的功能,但是其 Bug 较多,可以参考 pt-query-digest。比如 pt-query-digest 中,会把遇到的数字都替换成“?”,导致无法区别不同数字后缀的表。
高危操作确认与规避。比如,DBA 不小心 Drop 数据表,而此类操作,目前还无有效的工具进行回滚,尤其是大表,其后果将是灾难性的。
SQL 合法性判断。为了安全、审计、控制等方面的原因,美团不会让研发人员直接操作数据库,而是提供 RDS 服务。尤其是对于数据变更,需要研发人员的上级主管进行业务上的审批。如果研发人员,写了一条语法错误的 SQL,而 RDS 无法判断该 SQL 是否合法,就会造成不必要的沟通成本。
因此为了让所有有需要的业务都能方便的使用 SQL 解析功能,我们认为应该具有如下特性。
直接暴露 SQL 解析接口,使用尽量简单。比如,输入 SQL,则输出表名、特征和优化建议。
接口的使用不依赖于特定的语言,否则维护和使用的代价太高。比如,以 HTTP 等方式提供服务。
千里之行,始于足下。下面我先介绍下 SQL 的解析原理。
原理
SQL 解析与优化是属于编译器范畴,和 C 等其他语言的解析没有本质的区别。其中分为,词法分析、语法和语义分析、优化、执行代码生成。对应到 MySQL 的部分,如下图
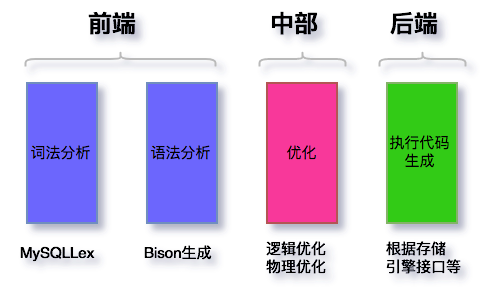
图 1 SQL 解析原理
词法分析
SQL 解析由词法分析和语法/语义分析两个部分组成。词法分析主要是把输入转化成一个个 Token。其中 Token 中包含 Keyword(也称 symbol)和非 Keyword。例如,SQL 语句 select username from userinfo,在分析之后,会得到 4 个 Token,其中有 2 个 Keyword,分别为 select 和 from:
通常情况下,词法分析可以使用Flex来生成,但是 MySQL 并未使用该工具,而是手写了词法分析部分(据说是为了效率和灵活性,参考此文)。具体代码在 sql/lex.h 和 sql/sql_lex.cc 文件中。
MySQL 中的 Keyword 定义在 sql/lex.h 中,如下为部分 Keyword:
词法分析的核心代码在 sql/sql_lex.c 文件中的,MySQLLex→lex_one_Token,有兴趣的同学可以下载源码研究。
语法分析
语法分析就是生成语法树的过程。这是整个解析过程中最精华,最复杂的部分,不过这部分 MySQL 使用了 Bison 来完成。即使如此,如何设计合适的数据结构以及相关算法,去存储和遍历所有的信息,也是值得在这里研究的。
语法分析树
SQL 语句:
会生成如下语法树。
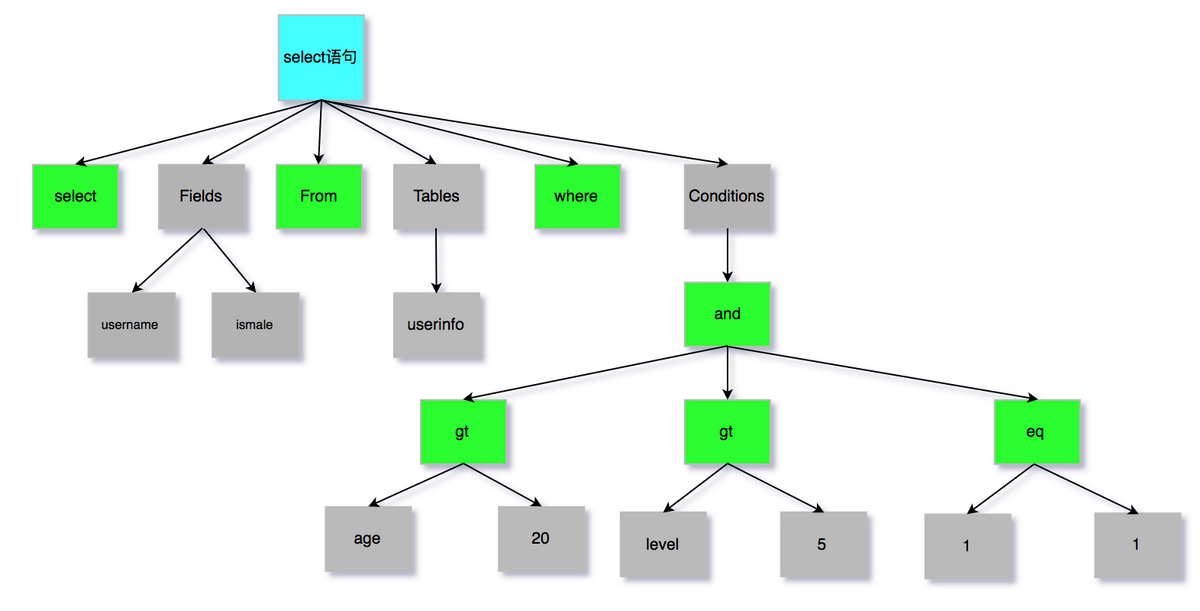
图 2 语法树
对于未接触过编译器实现的同学,肯定会好奇如何才能生成这样的语法树。其背后的原理都是编译器的范畴,可以参考维基百科的一篇文章,以及该链接中的参考书籍。本人也是在学习 MySQL 源码过程中,阅读了部分内容。由于编译器涉及的内容过多,本人精力和时间有限,不做过多探究。从工程的角度来说,学会如何使用 Bison 去构建语法树,来解决实际问题,对我们的工作也许有更大帮助。下面我就以 Bison 为基础,探讨该过程。
MySQL 语法分析树生成过程
全部的源码在 sql/sql_yacc.yy 中,在 MySQL5.6 中有 17K 行左右代码。这里列出涉及到 SQL:
解析过程的部分代码摘录出来。其实有了 Bison 之后,SQL 解析的难度也没有想象的那么大。特别是这里给出了解析的脉络之后。
在大家浏览上述代码的过程,会发现 Bison 中嵌入了 C++的代码。通过 C++代码,把解析到的信息存储到相关对象中。例如表信息会存储到 TABLE_LIST 中,order_list 存储 order by 子句里的信息,where 字句存储在 Item 中。有了这些信息,再辅助以相应的算法就可以对 SQL 进行更进一步的处理了。
核心数据结构及其关系
在 SQL 解析中,最核心的结构是 SELECT_LEX,其定义在 sql/sql_lex.h 中。下面仅列出与上述例子相关的部分。

图 3 SQL 解析树结构
上面图示中,列名 username、ismale 存储在 item_list 中,表名存储在 table_list 中,条件存储在 where 中。其中以 where 条件中的 Item 层次结构最深,表达也较为复杂,如下图所示。
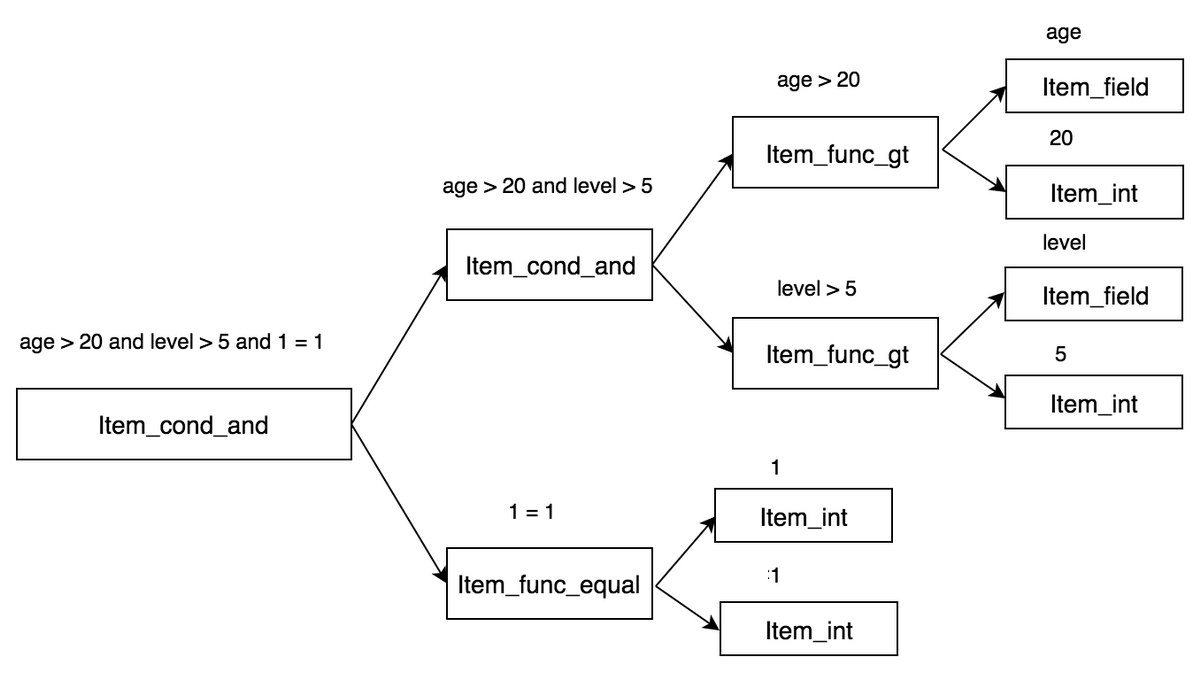
图 4 where 条件
SQL 解析的应用
为了更深入的了解 SQL 解析器,这里给出 2 个应用 SQL 解析的例子。
无用条件去除
无用条件去除属于优化器的逻辑优化范畴,可以仅仅根据 SQL 本身以及表结构即可完成,其优化的情况也是较多的,代码在 sql/sql_optimizer.cc 文件中的 remove_eq_conds 函数。为了避免过于繁琐的描述,以及大段代码的粘贴,这里通过图来分析以下四种情况。
a)1=1 and (m > 3 and n > 4)
b)1=2 and (m > 3 and n > 4)
c)1=1 or (m > 3 and n > 4)
d)1=2 or (m > 3 and n > 4)
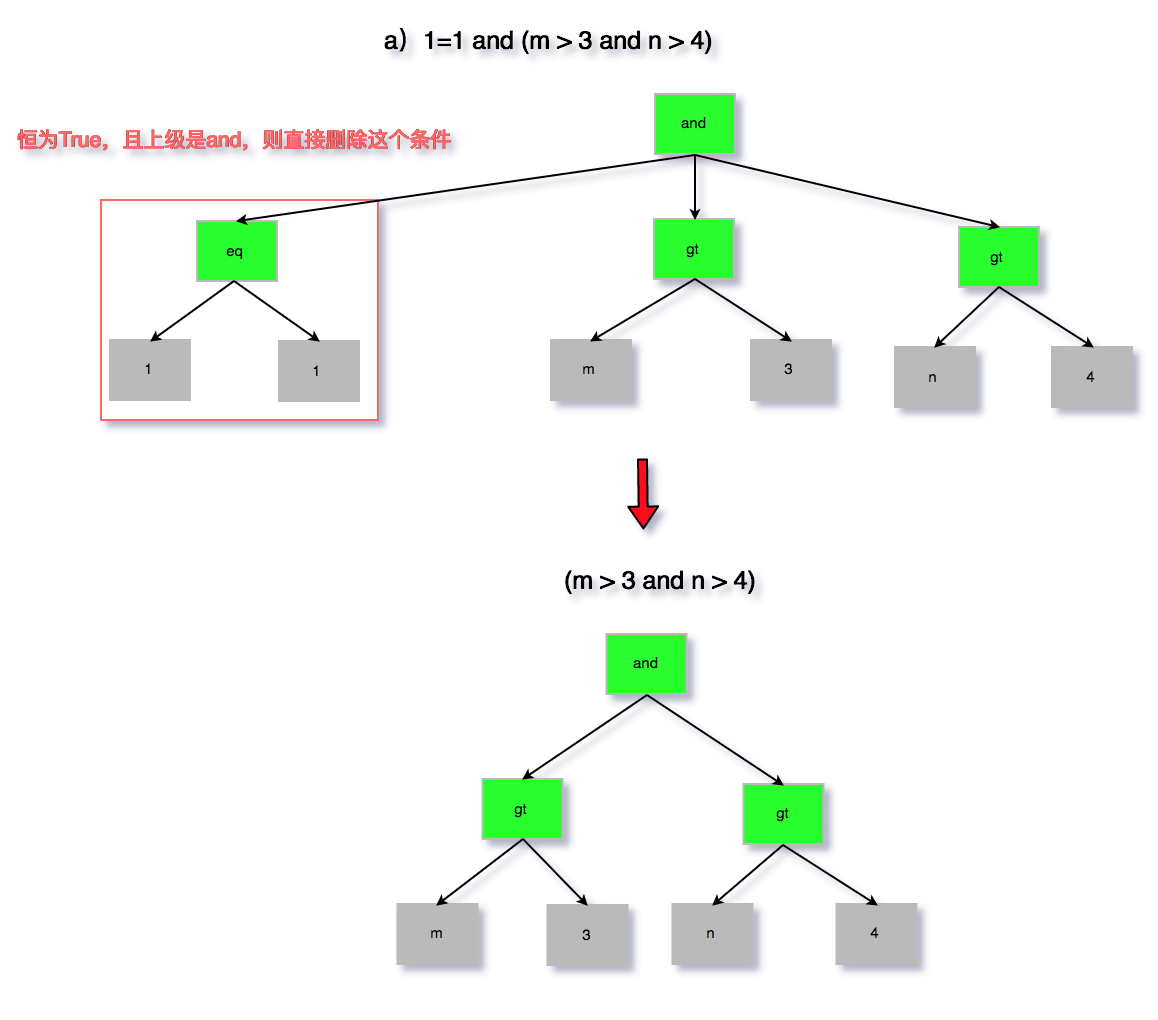
图 5 无用条件去除 a
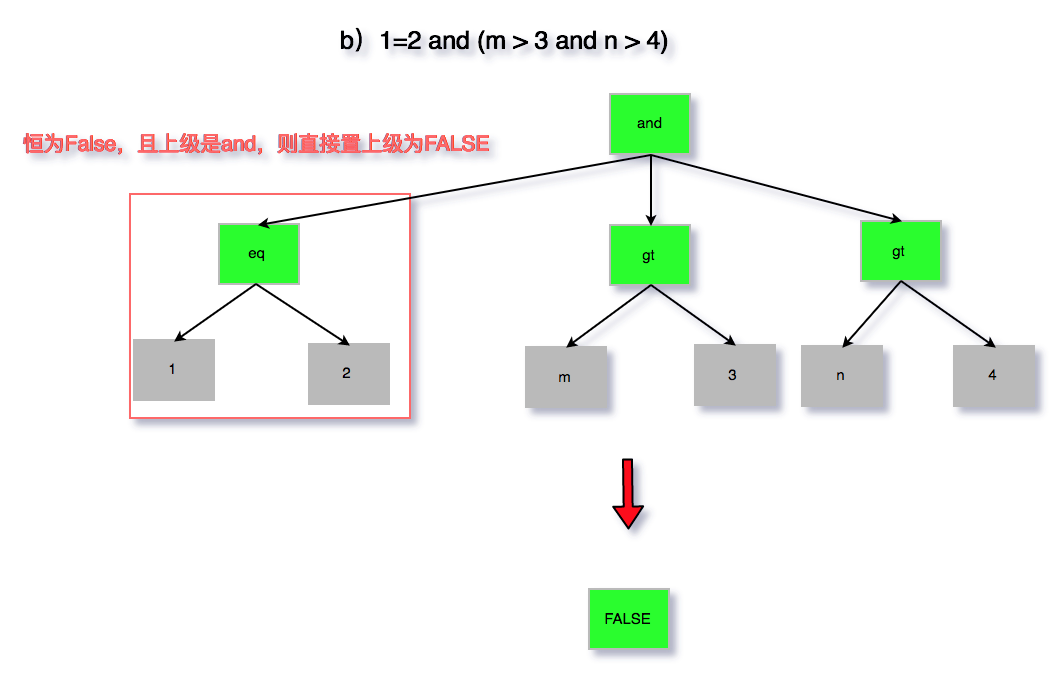
图 6 无用条件去除 b
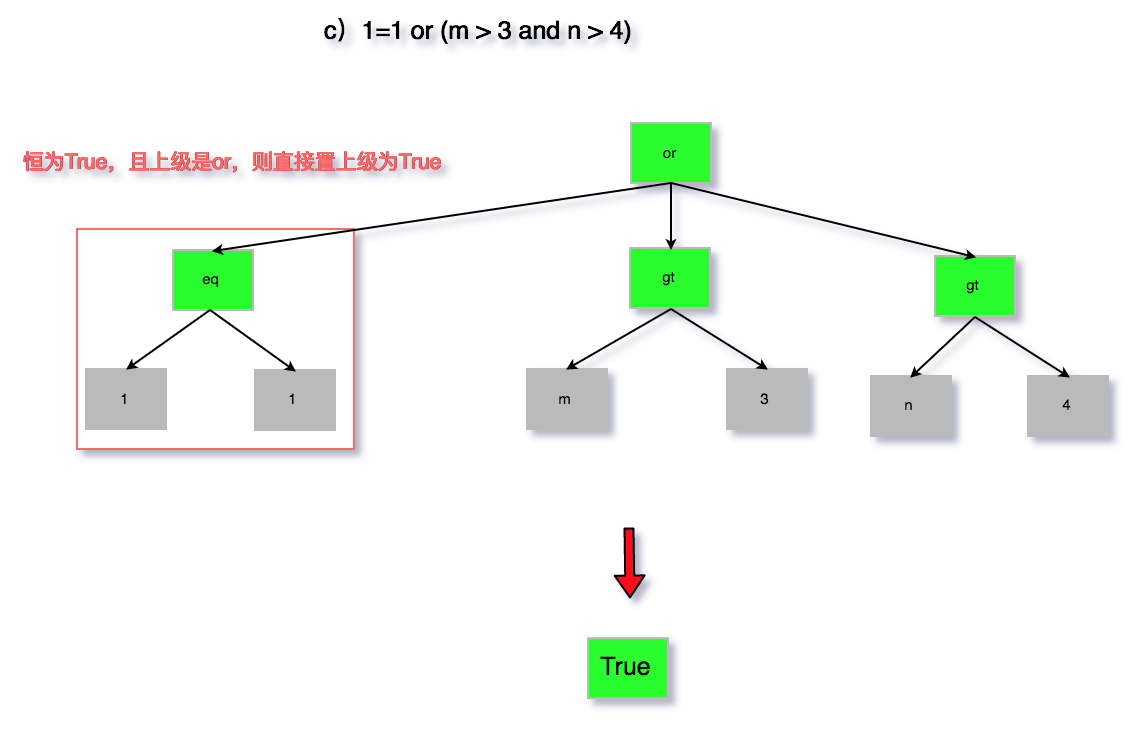
图 7 无用条件去除 c
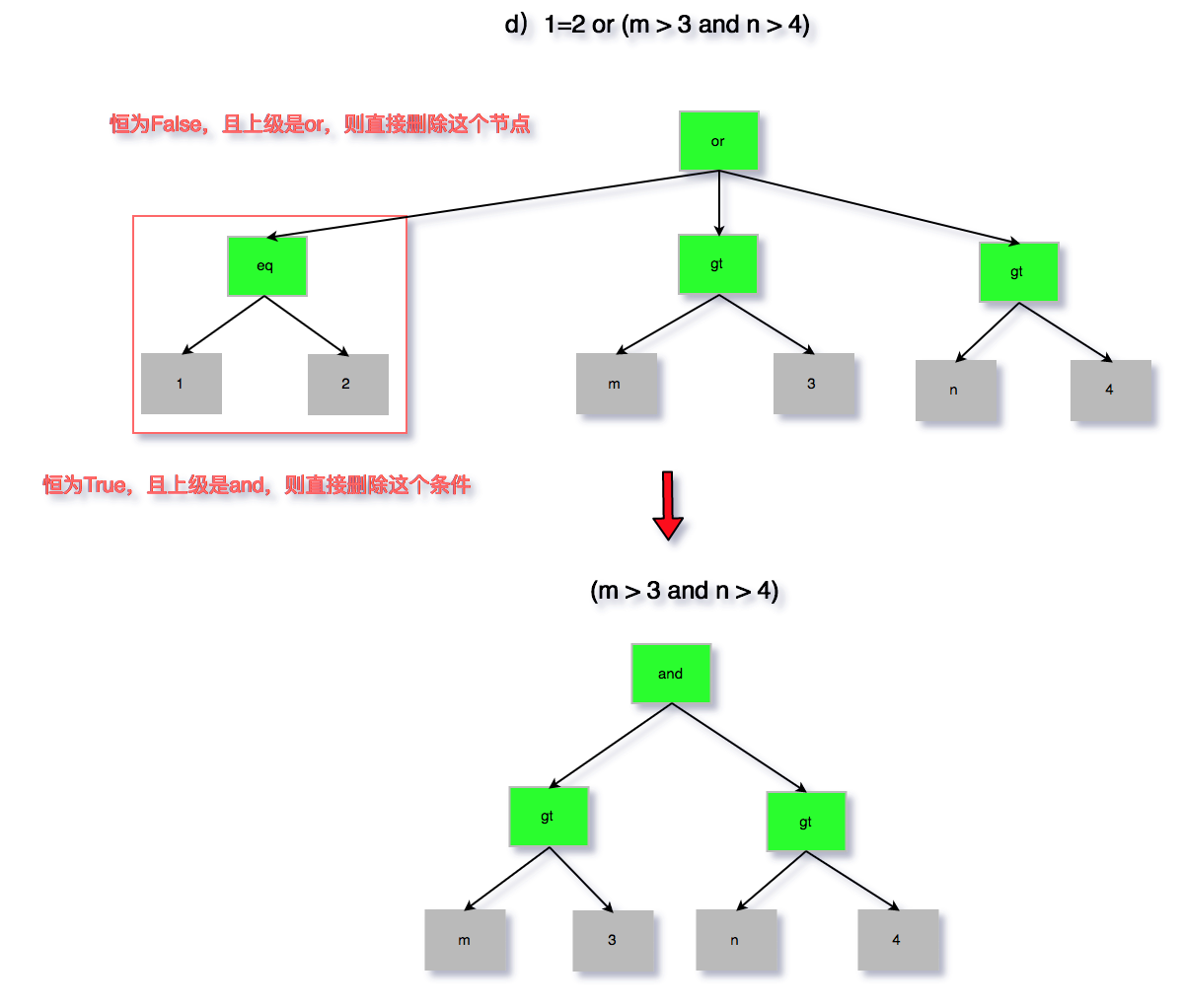
图 8 无用条件去除 d
如果对其代码实现有兴趣的同学,需要对 MySQL 中的一个重要数据结构 Item 类有所了解。因为其比较复杂,所以 MySQL 官方文档,专门介绍了Item类。阿里的 MySQL 小组,也有类似的文章。如需更详细的了解,就需要去查看源码中 sql/item_*等文件。
SQL 特征生成
为了确保数据库,这一系统基础组件稳定、高效运行,业界有很多辅助系统。比如慢查询系统、中间件系统。这些系统采集、收到 SQL 之后,需要对 SQL 进行归类,以便统计信息或者应用相关策略。归类时,通常需要获取 SQL 特征。比如 SQL:
业界著名的慢查询分析工具 pt-query-digest,通过正则表达式实现这个功能但是这类处理办法 Bug 较多。接下来就介绍如何使用 SQL 解析,完成 SQL 特征的生成。
SQL 特征生成分两部分组成。
a) 生成 Token 数组
b) 根据 Token 数组,生成 SQL 特征
首先回顾在词法解析章节,我们介绍了 SQL 中的关键字,并且每个关键字都有一个 16 位的整数对应,而非关键字统一用 ident 表示,其也对应了一个 16 位整数。如下表:
将一个 SQL 转换成特征的过程:
在 SQL 解析过程中,可以很方便的完成 Token 数组的生成。而一旦完成 Token 数组的生成,就可以很简单的完成 SQL 特征的生成。SQL 特征被广泛用于各个系统中,比如 pt-query-digest 需要根据特征对 SQL 归类,然而其基于正则表达式的实现有诸多 bug。下面列举几个已知 Bug:
因此可以看出 SQL 解析的优势是很明显的。
学习建议
最近,在对 SQL 解析器和优化器探索的过程中,从一开始的茫然无措到有章可循,也总结了一些心得体会,在这里跟大家分享一下。
首先,阅读相关图书书籍。图书能给我们系统认识解析器和优化器的角度。但是针对 MySQL 的此类图书市面上很少,目前中文作品可以看一看《数据库查询优化器的艺术:原理解析与 SQL 性能优化》。
其次,要阅读源码,但是最好以某个版本为基础,比如 MySQL5.6.23,因为 SQL 解析、优化部分的代码在不断变化。尤其是在跨越大的版本时,改动力度大。
再次,多使用 GDB 调试,验证自己的猜测,检验阅读质量。
最后,需要写相关代码验证,只有写出来了才能算真正的掌握。
作者简介
广友,美团到店综合事业群 MySQL DBA 专家,2012 年毕业于中国科学技术大学,2017 年加入美团,长期致力于 MySQL 及周边工具的研究。
金龙,2014 年加入美团,主要从事相关的数据库运维、高可用和相关的运维平台建设。对运维高可用与架构相关感兴趣的同学可以关注个人微信公众号“自己的设计师”,定期推送运维相关原创内容。
邢帆,美团到店综合事业群 MySQL DBA,2017 年研究生毕业后加入美团,目前已经对 MySQL 运维有一定经验,并编写了一些自动化脚本。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论