
“AI 教母”李飞飞的创业公司,刚刚放出了一个大招。
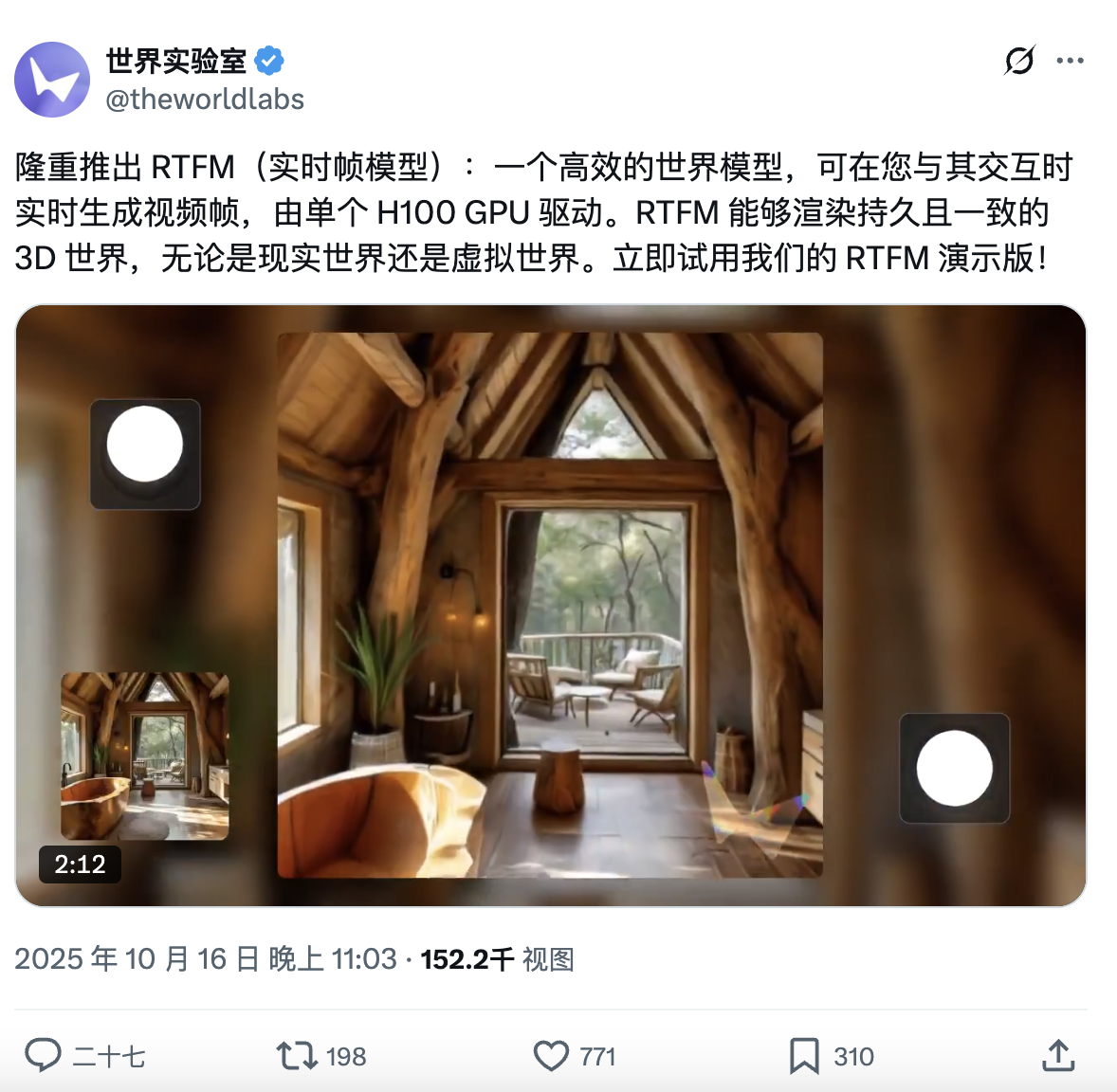
World Labs 在 X 上隆重介绍了一个新鲜的高效世界模型:RTFM(Real-Time Frame Model,实时帧模型)。
有多高效?——只要一个 H100 GPU,即可一边和用户交互,一边实时渲染出 3D 世界。
要知道,现在世界模型的一大挑战,就是对算力的需求很高。据 World Labs 介绍,生成式世界模型的计算需求,远超如今的大语言模型。
也就是说,李飞飞团队的这个新成果,把世界模型的对 H100 的需求锐减了好几个量级,显著降低了硬件成本和部署难度。
而且据 World Labs 介绍,虽然 RTFM 背后的算力大幅减少,但其渲染效果依旧不俗,构建的 3D 世界可达到持久一致,所有场景将永久留存。该系统构建的持久化 3D 世界不会因视角转换而消失。

RTFM 可以处理各种场景类型、视觉风格和效果,包括反射、光滑表面、阴影和镜头眩光;

此外,该架构具备随数据量与算力增长而持续扩展的能力。它通过端到端的通用架构从海量视频数据中自主学习,无需依赖显式 3D 表征即可构建三维世界模型。
RTFM:突破世界模型的算力限制
世界模型,是 AI 根据自己与环境的交互建立的预测模型,它不需要人工创建完整的虚拟世界,而是通过与环境的互动,推测和构建出一个虚拟世界的“内部地图”。
那么,与仿真和一般的视频生成模型相比,世界模型有什么不同和优势?
世界模型与仿真和视频生成模型的主要区别在于,前者是通过 AI 与环境的互动自动学习和构建的,它不需要人工创建完整的虚拟世界,而是根据交互推测出环境的规律和变化。
与仿真不同,仿真依赖于人工设计的虚拟环境和规则,而世界模型具备自主学习和适应能力。
相比视频生成模型,世界模型不仅生成图像或视频,还能够理解和预测环境的动态,支持智能体做出决策。
简而言之,世界模型能更真实地反映动态变化,并为 Agent 提供决策支持;而仿真和视频生成模型更多是静态的或单向生成的内容。
世界模型如果发展成熟,能够深刻改变从媒体到机器人等各个行业,因为它能够实时生成“持久、交互、精准”的模拟世界,进一步推进 AI 在现实世界产生实际作用。
然而,据 World Labs 介绍,生成式世界模型的计算需求非常高,远超如今的大语言模型。
他们了打个比喻,以 60fps 的速度生成交互式 4K 视频流需要每秒生成超过 10 万个 token(大约相当于第一部《哈利·波特》的长度),那让这些 token 持续生成一小时或更长时间,需要关注超过 1 亿个 token 的上下文。
再举个例子,OpenAI 的 Sora 还不算完整的世界模型,只是具备一定的世界建模能力。而据 Factorial 基金会估计,OpenAI 的 Sora 在峰值运行时,需要 72 万块 H100 GPU。
这些也让李飞飞的 World Labs 开始思考:生成式世界模型是否受到当今硬件限制的阻碍?或者,目前是否有办法预览这项技术?
指出,AI 领域有个教训:就是过去很多研究者试图把人类的知识和经验直接嵌入到 AI 系统中,虽然这种方法在短期内有效,但从长远来看,它会阻碍进步。
而随着计算能力的提升,像搜索和学习这样的技术可以变得越来越强大,越来越好,反而是最有前景的方法。
也就是说,从长远来看,人类知识的嵌入并不是一个很好的解决办法,计算能力的扩展和智能的自主学习,才是推动 AI 进步的真正动力。
仅靠一个 H100 跑世界模型,怎么做到的?
据 World Labs 官方博客,RTFM 能够仅依靠一个 H100 GPU 进行高效的实时推理,主要得益于其高效的神经网络架构、创新的自回归扩散 Transformer、空间记忆技术和上下文切换机制。
这些设计使得 RTFM 能够减少计算资源的消耗,并实现大规模 3D 世界的持久建模,确保其可以在单一硬件上长期运行。
首先,研发团队对 RTFM 在推理过程中的各个环节进行了精细优化,他们运用了架构设计、模型提炼和推理优化方面的最新进展,以保证模型在硬件上能够高效运行。
为了同时确保它生成的世界模型质量够高,RTFM 需要依赖优化的神经网络架构和推理技术,保证它在计算资源有限的情况下仍能提供高质量的输出;这些技术能让它在计算资源有限的情况下仍然提供好的表现。
至于自回归扩散 Transformer(Autoregressive Diffusion Transformer),是近年来新兴的神经网络架构之一,它在视频生成和时间序列预测方面表现优异。使用这种先进架构,能够有效优化模型的计算效率,并生成高质量的帧,支持实时推理。
另外,RTFM 采用空间记忆机制,通过为每一帧建模其在三维空间中的姿态,能够在保持高效的同时,在大场景中保留住几何结构,实现真正意义上的世界持久性;还采用了上下文切换机制,优化了计算资源的使用,提高了模型的效率。
总而言之,RTFM 只需要一个 H100 GPU 就能运行世界模型,主要得益于以下几个方面:
高效的架构设计,确保模型在单个 GPU 上运行并维持交互帧率和世界持久性。
使用自回归扩散变换器进行帧序列预测,优化了推理过程。
空间记忆和上下文切换技术,使得模型能够从历史帧中检索数据,避免重复计算。
采用端到端学习的方法,减少对复杂 3D 建模的需求,从而降低计算负担。
可扩展性设计,使得模型能够在计算资源提升时有效扩展其功能。
参考链接:




