

在QCon广州2019大会上,孙晓光讲师做了《知乎首页已读数据万亿规模下高吞吐低时延查询系统架构设计》主题演讲,主要内容如下。
演讲简介:
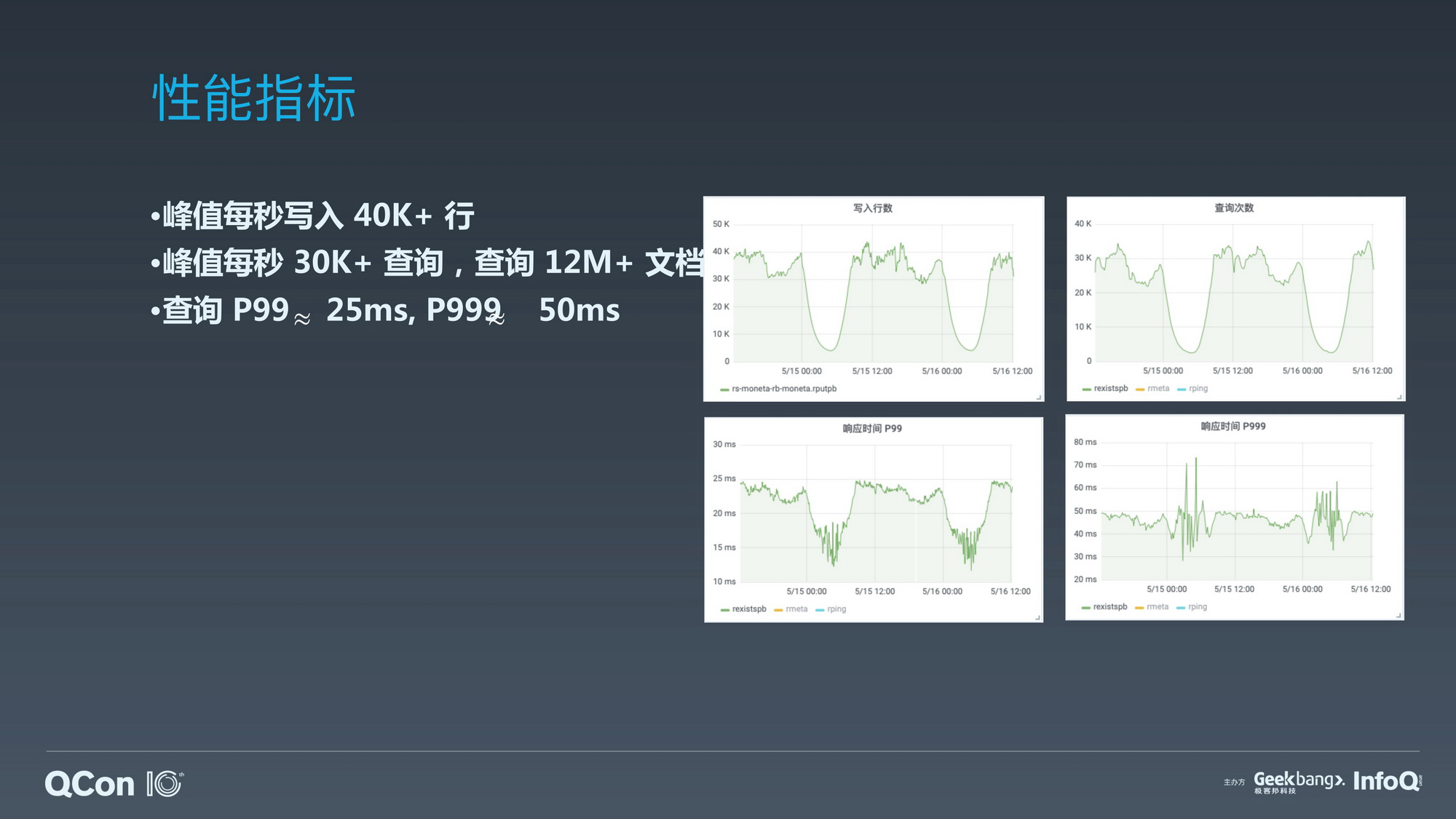
知乎从问答起步在过去的 8 年中逐步成长为一个大规模的综合性知识内容平台,今天在知乎站上有多达 38 万个话题,超过 2800 万个问题总共收获了超过 1.3 亿个回答,同时知乎还沉淀了数量众多的优质文章、电子书以及其他付费内容。知乎通过个性化首页推荐的方式在海量的信息中高效的分发用户感兴趣的优质内容。为了避免给用户推荐重复的内容,首页会记录下所有给用户推荐过的内容长期保存。直至今天知乎已读的数据规模已超过万亿并以每天接近 30 亿的速度持续增长,实时、可靠且高效的存储和查询已读数据存在着诸多挑战。在过去的一年多已读服务的架构在承载着 40000/s 新数据写入的同时还支撑着峰值每秒 30000 条独立请求和 1200 万文档已读状态的查询,并且在大流量的冲击下响应时间依旧稳定维持在 P99 24ms 以及 P999 45ms 的低水位线。在本次演讲中我们会分享目前知乎已读服务的整体架构以及我们如何在这个架构上应对各种挑战满足业务需求,希望这个分享能为大家开拓解决类似问题的思路。
内容大纲:
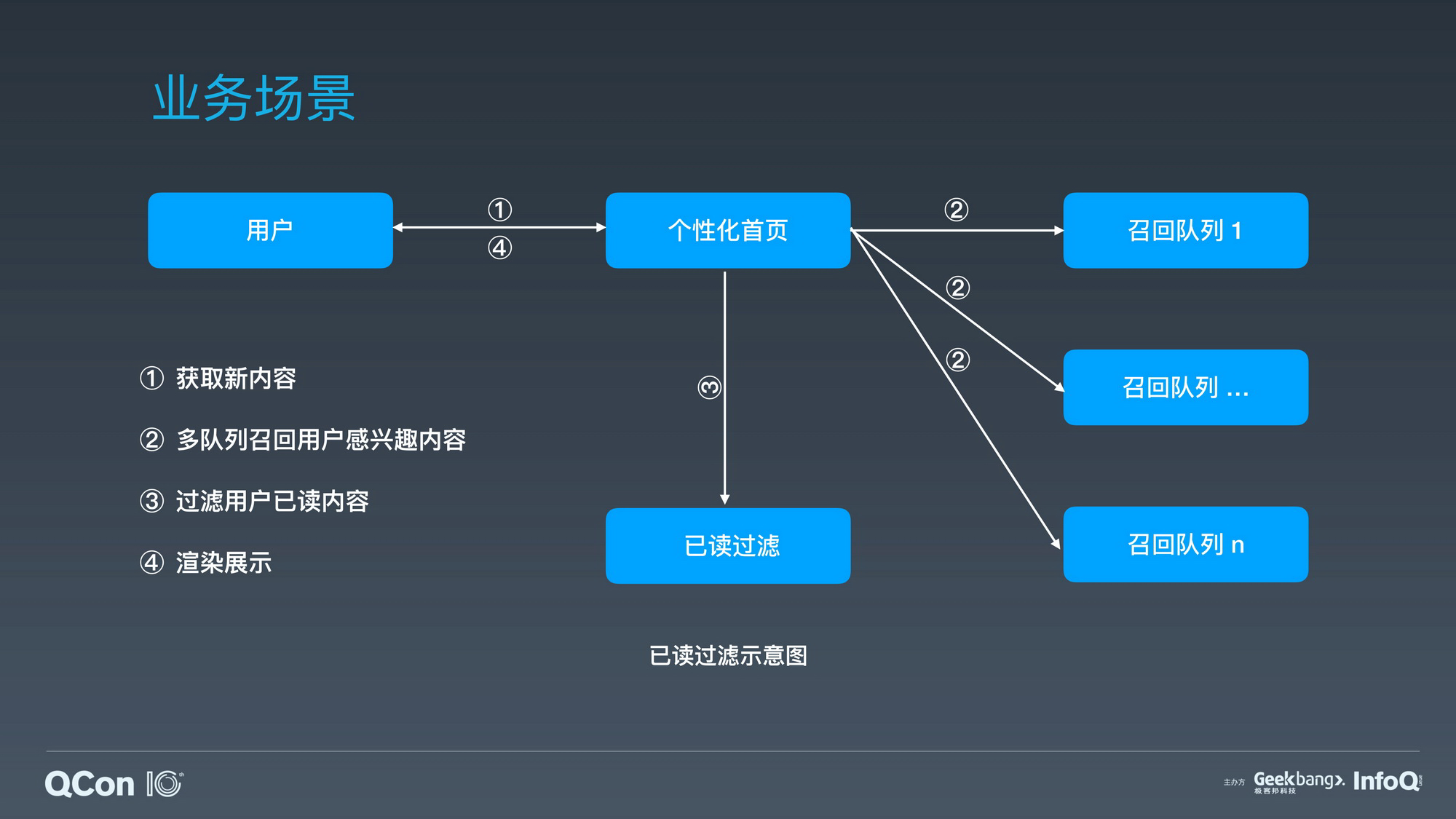
业务场景:知乎个性化首页利用已读过滤服务高效率分发用户未阅读过的优质内容 。
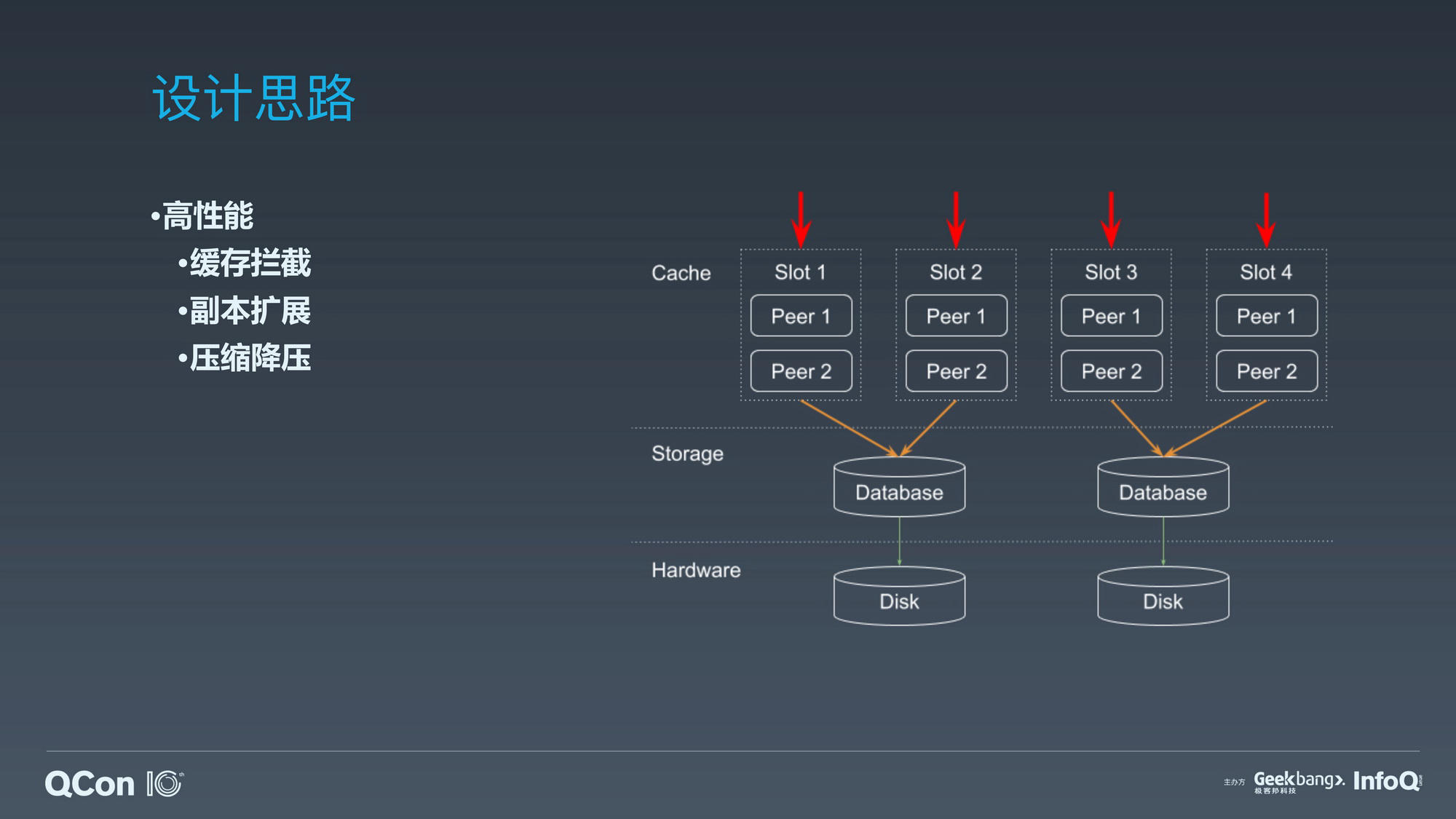
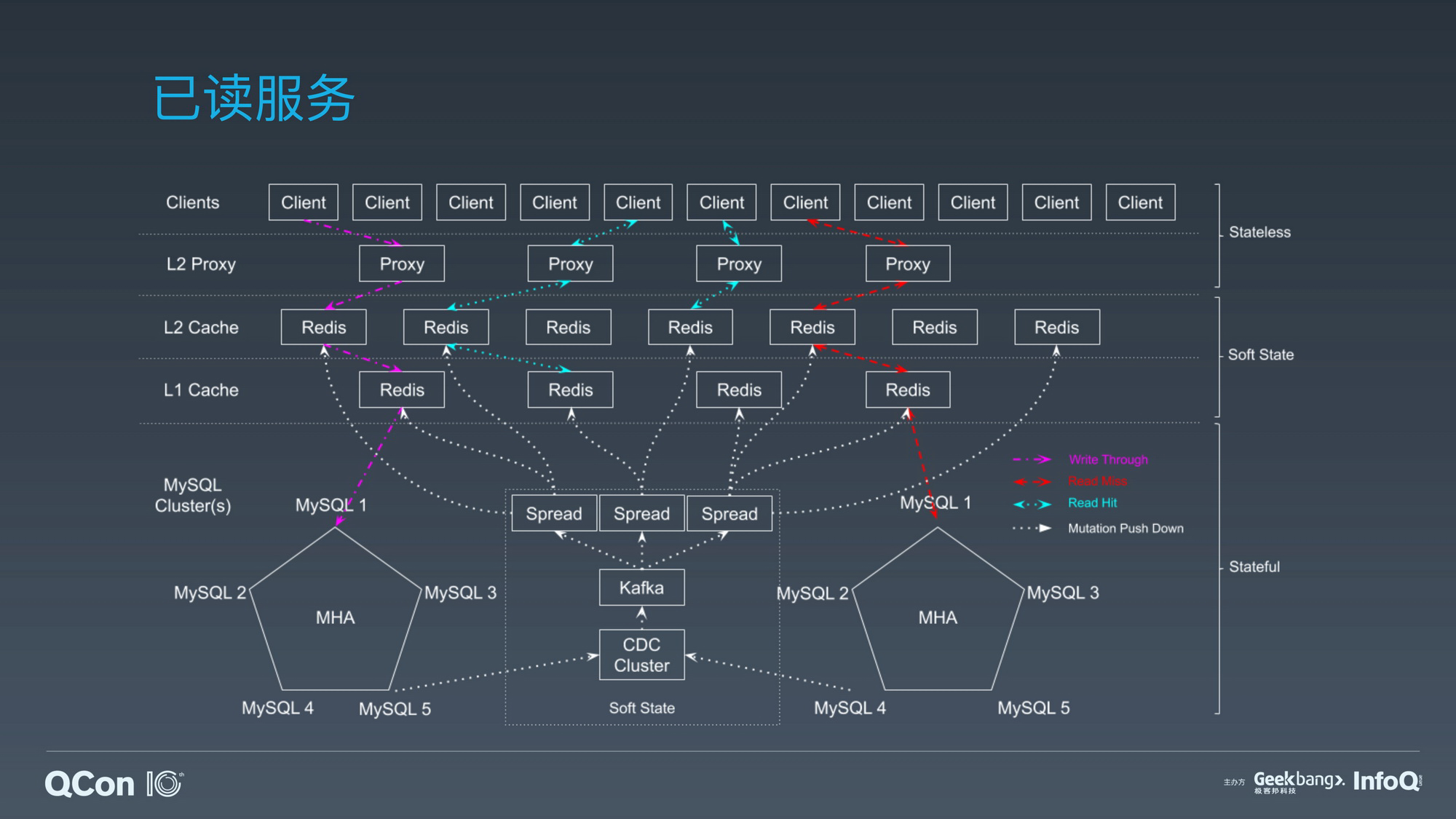
服务架构:知乎目前已读数据已经达万亿条量级并且还在以更快的加速度持续增长,而缓存系统则是万亿规模数据集高吞吐低时延的关键点。已读服务通过将缓冲智能化来应对数据频繁更新和数据高度稀疏对缓存系统在一致性和命中率方面的挑战。
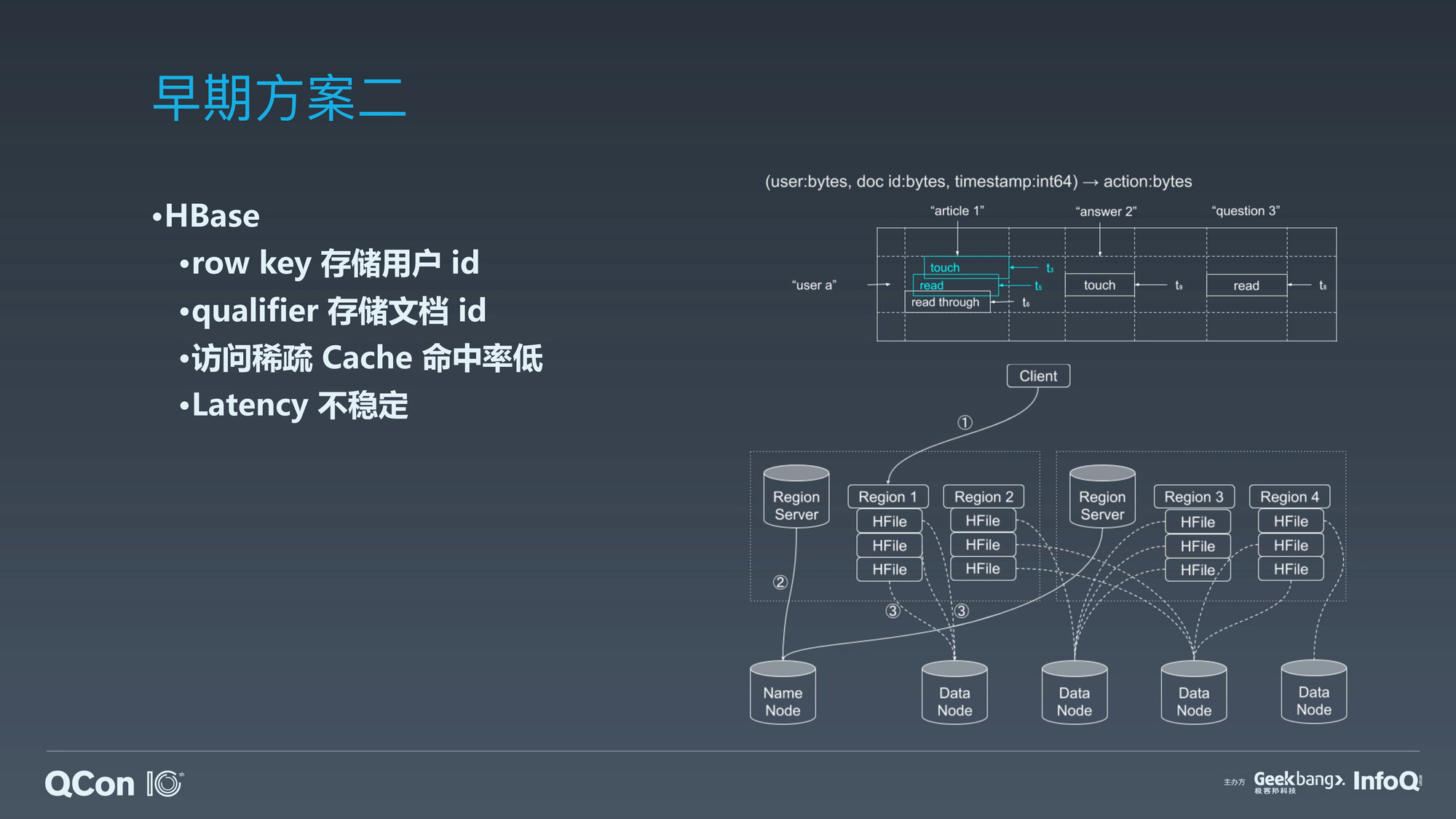
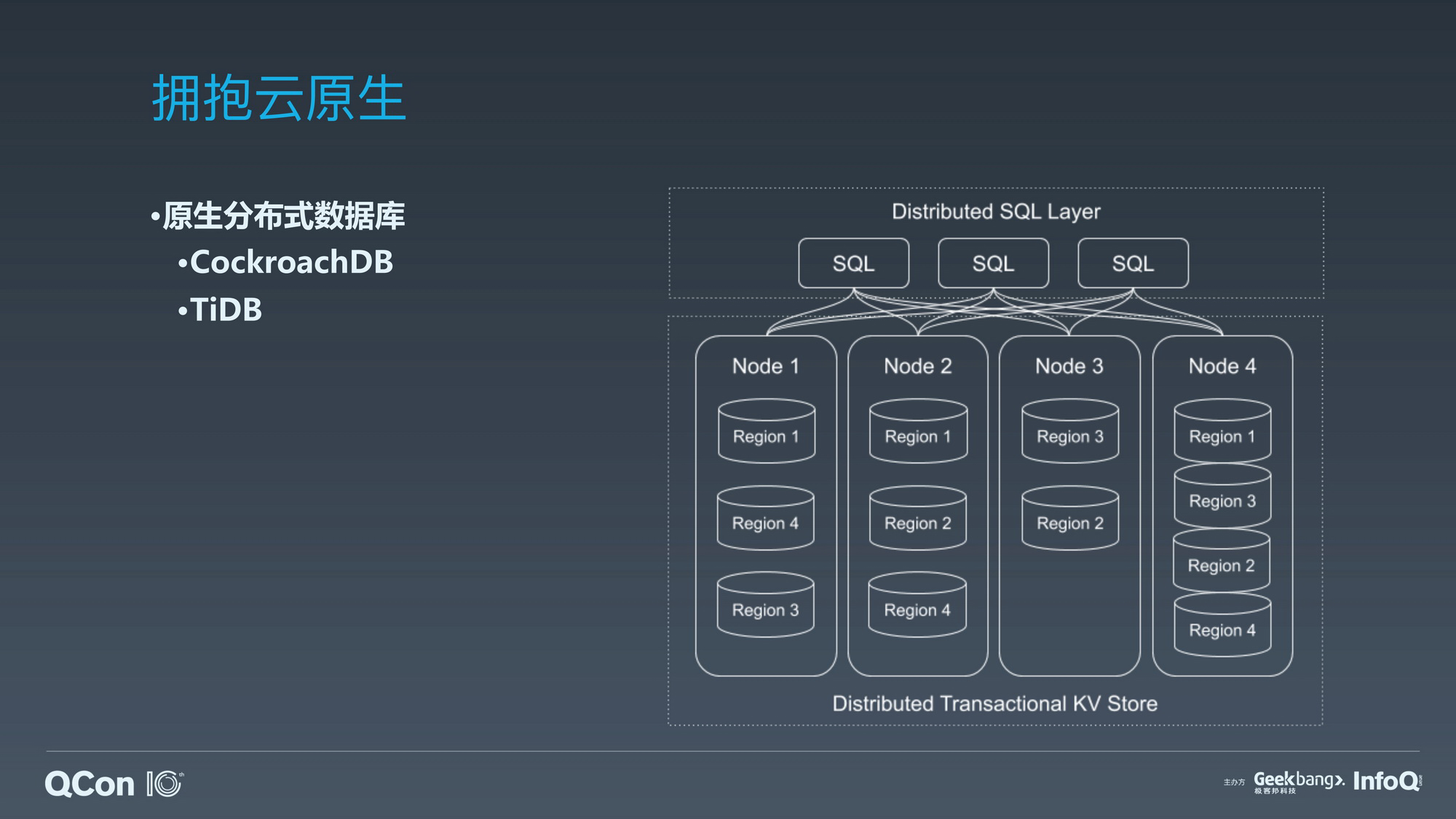
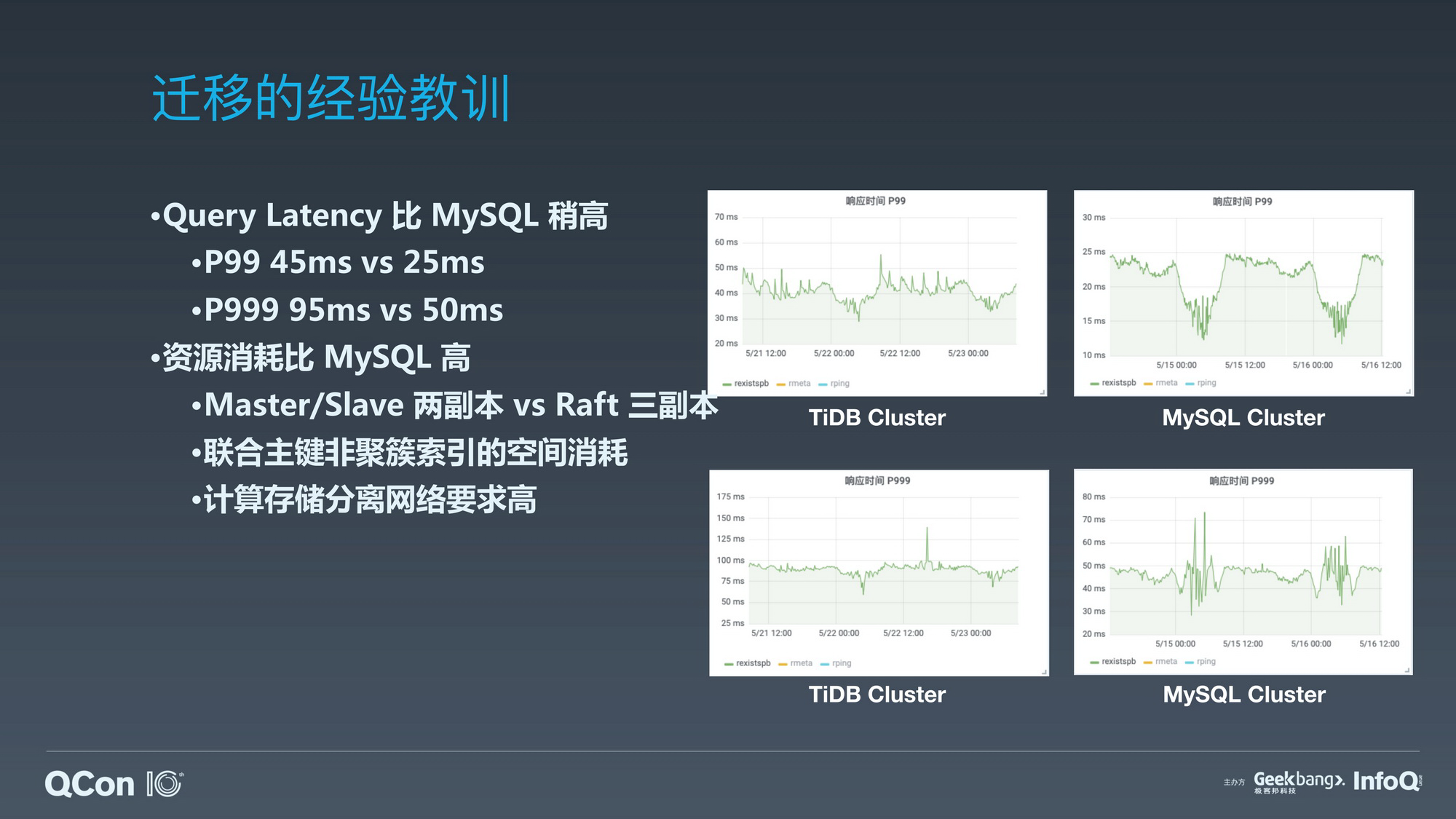
原生分布式数据库的迁移代价和海量数据集下的收益。
听众受益:
大量更新的海量数据缓存系统设计;
缓存一致性的考量和取舍;
原生分布式数据库的迁移成本和巨大收益。
讲师介绍:
孙晓光
知乎 搜索后端负责人
知乎搜索后端负责人,目前承担知乎搜索后端架构设计以及工程团队的管理工作。曾多年从事私有云相关产品开发工作关注云原生技术,TiKV 项目 Committer。


完整演讲 PPT 下载链接:
https://qcon.infoq.cn/2019/guangzhou/schedule

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论