

前言
云端安全小建议的系列文章,是由腾讯云账号与权限团队的一线开发人员推出的关于用户安全的小建议。该系列文章旨在帮助腾讯云用户能够充分利用腾讯云提供的产品特性,安全的解决自己在实际生产中的遇到的问题。文章中会提到很多应用场景以及错误的解决方法和正确的安全的解决方法。该系列文章不仅会有场景分析还会有技术分析,所以只要是腾讯云的用户,无论是技术小白用户还是技术大神都可以一起来讨论和实践。对于用户提出的安全问题,我们会第一时间跟进,站在平台方的角度给出安全合理的解决方案。
场景
在实际的工作中,我们经常会遇到用户想定期审计自己的腾讯云账号。每个用户的审计规则不同,审计规则可能会有很多,我们不做详细描述。在这里只举一个简单的例子,一家腾讯云的客户 A,客户 A 拥有一个腾讯云的主账号,同时这个主账号下面还拥有很多的子账号。A 的老板想能够随时关注到 A 的账号下面的资源个子账号们,在什么时候,在哪里操作过什么业务的整体视图?并且自己可以定制审计规则,一旦命中规则可以及时告知到老板。
我们收到了很多类似的需求之后,开始反思云审计应该有什么样开放的特性,才能帮助到用户达到自己的愿望,让客户 A 的老板能站在上帝的视角俯瞰整个腾讯云账户,只要有不符合预期的风吹草动就能及时感知。(就像《将夜》里面的夫子,俯瞰世界)
后来我们不断的实验和探索,最终找到了一个可持续、可扩展以及可移植的方案,可以帮助客户 A 的老板能有上帝的视角俯瞰他的腾讯云账号。为了验证这个方案的可用性和健壮性,我们自己已经在现网运行了两个月左右。事实证明,该方案能稳定的运行,并能够分析 TB 级别的数据。
基本概念
在介绍整体方案之前,我们先介绍几个基本的概念,在了解了这些概念之后。我们再做详细的方案介绍,并在介绍方案的同时附上关键步骤源码,方便客户 A 的老板的程序员们能够快速的实现老板的需求。毕竟我们都是程序员,程序员何必为难程序员。
什么是云审计
云审计可以获取您腾讯云账号下 API 调用历史记录,包括通过腾讯云管理控制台,腾讯云 SDK,命令行工具和其他腾讯云服务进行的 API 调用,监控腾讯云中的任何部署行为。可以确定哪些子用户、协作者使用腾讯云 API 时,从哪个源 IP 地址进行调用,以及何时发生调用。具体内容可以参考云审计的产品页。
什么是跟踪集
跟踪是一种配置,可用于将云审计的事件传送到腾讯云的 COS 存储桶。简单点讲,跟踪集能够帮助用户,把 API 调用记录持久化存储到 COS 的存储桶里。之所以会有这个功能是因为云审计目前只能帮助用户缓存有限时间内的 API 调用记录,并不能做到持久化存储。
什么是 COS
对象存储(Cloud Object Storage,COS)是腾讯云提供的面向非结构化数据,支持 HTTP/HTTPS 协议访问的分布式存储服务,它能容纳海量数据并保证用户对带宽和容量扩充无感知,可以作为大数据计算与分析的数据池。腾讯云 COS 提供网页端管理界面、多种语言的 SDK 以及命令行和图形化工具,并且完全兼容 S3 的 API 接口,方便用户直接使用社区工具和插件,COS 还可以和其他云产品结合,比如利用 CDN 的全球节点提供加速服务,利用数据万象的图片处理能力提供一站式图片解决方案等。具体内容可以参考对象存储的产品介绍页。
什么是 EMR
弹性 MapReduce (EMR)结合云技术和 Hadoop、Hive、Spark、Hbase、Storm 等社区开源技术,提供安全、低成本、高可靠、可弹性伸缩的云端托管 Hadoop 服务。您可以在数分钟内创建安全可靠的专属 Hadoop 集群,以分析位于集群内数据节点或 COS 上的 PB 级海量数据。具体内容可以参考 EMR 的产品介绍页。
详细方案
在了解完上述的基本概念之后,有经验的程序员们心里大概知道方案是什么样的了。但是我还是决定把详细的方案仔细的详细的介绍一遍,万一你意想不到的惊喜呢?
首先我们先画一个图,先体验一把作为上帝俯瞰整个方案的快感,作为程序员的你,就能体会到老板为什么想站在上帝的视角来俯瞰自己的云账号了。这样才能更有动力帮助老板实现这个方案。
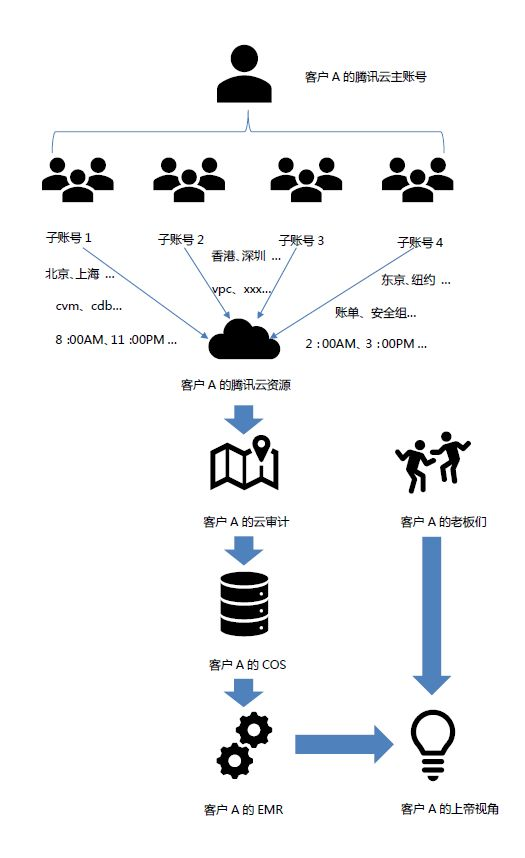
方案描述
从上图可以看出,客户 A 的在腾讯云上的资源很多,员工也很多,分公司也分散在全球各地,员工们也很勤奋。那假如你是这家公司的老板,你是不是想默默的关注着我的全球员工们在云上的工作状态和行为呢,并通过这个视角及时发现安全隐患,并做出及时的调整呢。
以下方案的介绍的重点是,帮助用户快速的搭建起上图描述的方案。所以是假设您已经拥有了以上所需的所有云资源的,比如我在描述到追踪集的格式的时候,我不会去介绍如何去创建追踪集的。也是假设您已经掌握了 MapReduce 的基本概念的。假如说我在描述 Hive 的时候,不会详细介绍什么是 Hive。
在开始正式的详细方案描述之前,我需要首先说一下这个方案目前的限制。
1.COS 存储桶必须建在上海区,因为目前云审计仅支持将 API 的调用记录投递到上海区的 COS 存储桶中。
2.目前仅支持控制流的日志分析,并不支持数据流的审计分析。
3.虽然 COS 存储桶仅支持建在上海区,但是各个地区的操作记录都可以被记录。也就是说,我们的数据一定是全的,不会遗留死角。
4.并不是所有的业务的审计日志都会被云审计记录,支持的业务列表可以参考云审计的产品文档。
5.EMR 的集群也最好建在上海,因为这样可以避免大量的外网流量。
6.在创建 EMR 集群的时候,有一个关键步骤就是允许 EMR 可以读取您的 COS 资源,这个授权很重要,一定不能跳过。
在 Hive 上基于 COS 创建数据库
连接 Hive 数据库
登录到 EMR 的 Master 机器上执行以下命令连接 Hive。
创建基于 COS 的数据库
连接到 hive 之后,便可以在上面创建基于 COS 存储桶的数据库了,可以执行以下命令。
将云审计的核心字段映射到 Hive 的表中的字段
在创建了基于 COS 的数据库之后,接下来就是将存储在 COS 中的云审计数据映射到 Hive 的表中,这样我们边能够借助 MapReduce 对云审计的数据进行分析了。(在创建这个映射关系的时候,应当充分了解云审计的字段。在此就不再赘述,用户可以去自行了解)以下是具体的建表语句。
定时将 COS 存储桶中的数据映射到 Hive 表中
上一步已经根据云审计的字段的映射创建了 Hive 表,那接下来就需要定期(目前是一个小时)将 COS 目录下的数据映射到 Hive 表中。以下是核心的 Python 代码。
将 COS 中的冷数据聚合为热数据
这句话的意思不难理解,其实存储在 COS 的中的日志数据往往是很大的,不能直接作为逻辑开发的数据基础,所以需要将这个里面的数据经过一次聚合,把结果数据存储到 Mysql 这样的热介质中。
以下是一段核心的 Python 代码,将 Hive 的数据进行聚合。
接下来即将发生的事情,我想大家都已经猜到了,就是将 result 的数据存储到 Mysql 中。然后就是常规的审计规则,根据老板的需求做出上帝视角的视图。
上帝视角的想象力
或许是这样的

操作时序图
或许是这样的
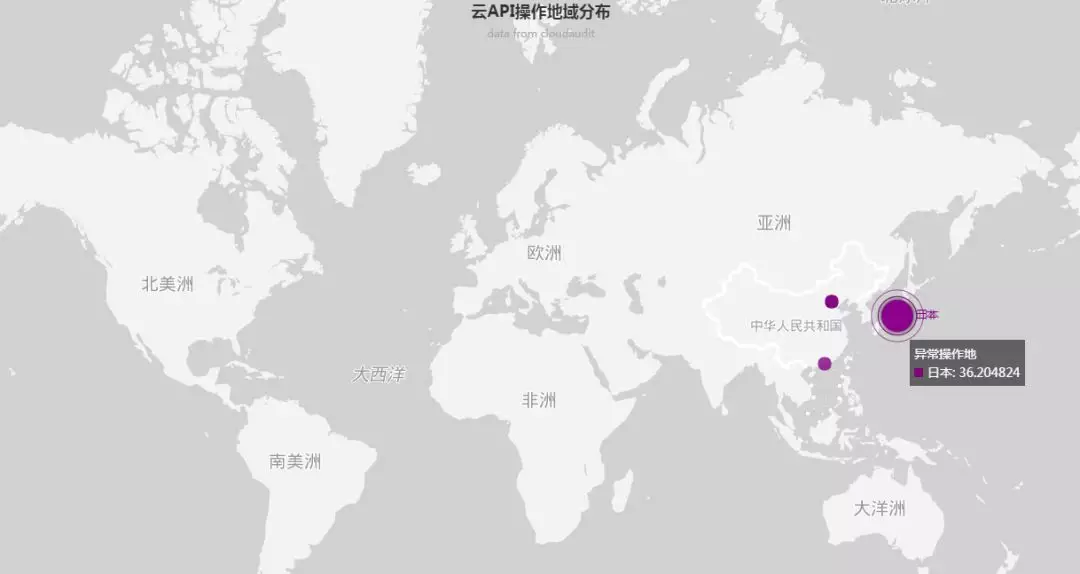
异常地域图
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/qQQl8ghb1zYUmN4pFWmnmQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论