
DeepSeek 作为一款有重大影响力的大模型,不仅推动了技术的创新,还在企业的人才管理体系中引发了深刻的变革。
在这个 AI 重塑行业格局的时代,研发工程师如何利用 DeepSeek 提升自身的竞争力?企业又该如何创造更加适合技术人才成长的环境?在 InfoQ 举办的 QCon 全球软件开发大会(北京站)上,上海载极数据科技 创始人 / CEO ,中嘉数字科技(浙江)总经理,谷歌开发者专家,谷歌出海创业加速器导师彭靖田分享了“AI 时代下的企业人才管理体系”,深入探讨 DeepSeek 在人才价值链中的变革作用。
主要包含以下方面:
DeepSeek 为何火爆出圈?探讨 DeepSeek 爆火的现象与本质
企业如何重构人才价值链:在人才的”选、育、用、留“方面的变化
未来的人才管理体系:会有什么变化,企业该如何拥抱 AI 时代的变革
在科技驱动的时代,一流技术是企业的核心竞争力,如何将技术优势转化为长期竞争力,从技术领先迈向管理卓越?将于 10 月 23 - 25 召开的 QCon 上海站设计了「从一流技术到一流管理」专题,将探讨技术团队在规模化、产品化和市场化过程中面临的关键管理挑战,分享从技术思维到管理思维的转型路径。敬请关注。
以下是详细的演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
在当今时代,探讨程序员是否会面临被取代的困境,或许需要我们跳出传统思维的框架。在我看来,有三种可能的因素会取代程序员:一是大家耳熟能详的人工智能,二是那些能够熟练运用 AI 的程序员,三是企业老板可能会选择的外部供应商。这三种情况构成了我们今天讨论“什么会取代程序员”的主要方向。我今天想和大家分享的主题是“AI 时代下的企业人才管理体系”,这个话题其实涉及面很广。
今天我主要想讲三个问题,它们也是对前面提到的三个可能取代程序员的因素的回应。首先是 AI 是否会取代你,其次是会用 AI 的程序员是否会取代你,最后是老板的想法,即老板是否会考虑用外部便宜的供应商来取代一个产品研发团队。第一部分的内容稍微偏技术一些,其实这部分是我昨天晚上临时增加了一些内容。因为大家都在讨论程序员会不会被 AI 取代,但我发现我们似乎很少关注 AI 本身。今年其实是一个非常有意思的一年,从开年的《哪吒》电影到各种各样所谓的东方文化崛起的讨论,大家都感觉东方的氛围起来了。那么在这个大背景下,大家有没有关注 AI 呢?
Deepseek 爆火的现象与本质
说到 DeepSeek,它的热度和影响力到底如何,这是一个很难去量化和讨论的问题。2 月 17 日,有一个最高级别的民营企业家会议,是由习总书记召开的。梁文峰就坐在第一排,紧挨着腾讯的马化腾。虽然梁文峰在会议上没有发言,但在 1 月 20 日的总理座谈会上,他作为代表发言了,而且也是在同一天,DeepSeek 发布了 R1 版本。这两位国家领导人在这个最顶级的会议上,让 DeepSeek 这家刚刚成立一年半的公司成为座上宾,这无疑是一个很明确的政治信号。那么,DeepSeek 为什么会得到这样的待遇呢?我认为,这肯定不仅仅是因为技术。在过去,我们要获得 1 亿用户,是以年为单位的。然而,直到上一轮深度学习泡沫破裂,大家觉得 AI 好像要结束了,又进入寒冬的时候,ChatGPT 横空出世,让我们发现两个月就能达到 1 亿用户,所有人都震惊了。所以,OpenAI 成为了资本的宠儿,迅速达到了 1000 亿美金的估值。但是紧接着,DeepSeek 用 7 天的时间改写了这个历史记录,并且我相信在没有人机交互迭代之前,很难再超越这个数字了。这个所谓的国运级的爆火,这 7 天已经非常足以说明问题了。我们看到 AI 产品出现之后,传统的互联网产品的增速已经无法出现在下图左侧 y 轴上面了。那么,AI 的产品一定会像原来的互联网产品一样席卷所有人,并且它的门槛更低。
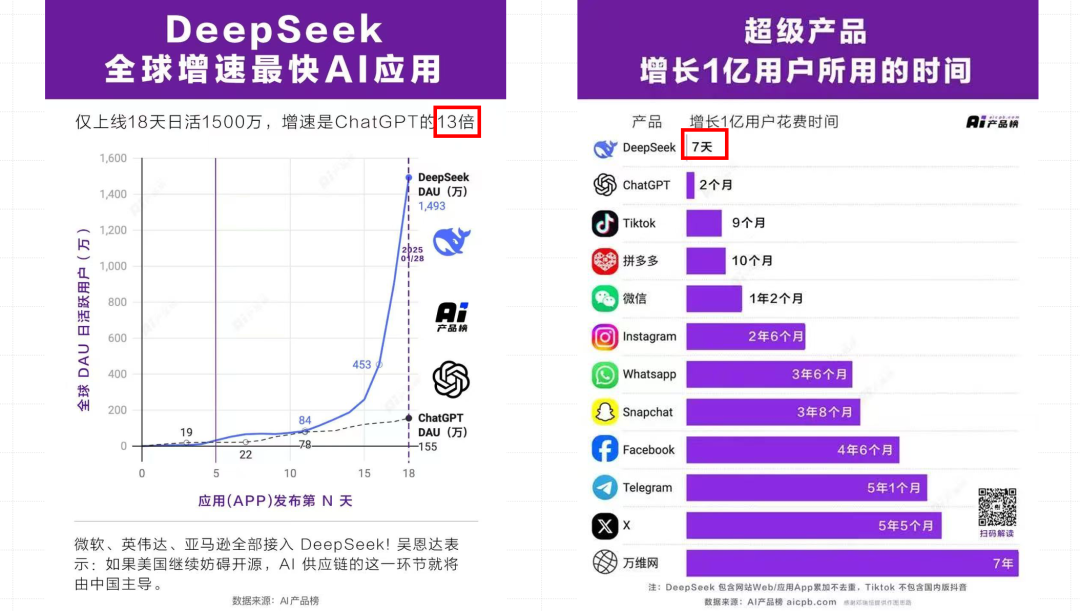
DeepSeek 对于我们技术人员来说,我自己是感觉到非常自豪的。在今年年初的时候,其实有很多朋友来问我,当然他们是非技术圈子的,问我说 DeepSeek 是不是又像一个骗子项目?他们问 DeepSeek 这么火,是真的吗?DeepSeek 的技术到底怎么样?其实我认为 DeepSeek 之所以火,包括受到两位国家领导人的邀请,有很重要的一些原因,从这四个维度是能看出来的。第一个就是它的能力确实非常强,这个强已经强到我们看到 OpenAI 的动作变形了,LLaMA 的动作也变形了。那么它现在可以说在某些维度上就是推理大模型赛道的领头羊,并且很明显 R2 版本应该已经在日程当中了。所以我们相信未来在推理大模型这件事情上,DeepSeek 可以做得更好。
第二点就是开源这件事情。我相信大家今天对于开源,尤其是深入做了很多年开源的人已经不再局限于说我今天要去提几个 PR 了。做开源的核心目的是什么?是要做标准的制定者。这件事情我们看到 MCP 在做,刚刚召开的 Google 开大会也是在做这个事情。把标准立起来,大家都在这个标准下面玩。今天大家习以为常的 TCP/IP、HTTP 这些协议都是美国人定义的,你已经习惯了这件事就是对的,没有别的选择。现在的 AI Agents 就处在这个时刻。那么 DeepSeek 其实做了一个很重要的事情,技术领先,免费开源,你跟着我来做研究,因为你花不起这么多钱。这其实是非常重要的一个点。
第三点是低成本。大家应该都了解过,所谓的大模型界的拼多多非常便宜,逼得 LLaMA 4 也去做 MoE 了。
最后一点是国产化。我是深有体会的,我自己不炒股,但我看到 2 月份的时候,A 股的半导体和 AI 题材涨得非常好。比如上海沐曦 GPU,也完成了上市辅导,马上要主板上市了。整个国产的半导体其实一直是一个追赶落后的状态,包括像华为的昇腾,我跟他们硬件团队聊,去年卖得非常好,就是因为 DeepSeek 的这个事情,销量一下增长了将近十倍。因为中国有自己的大模型,企业和政府才敢用。我在去年跟邮储银行总行去交流的时候,他当时就提到一个巨大的问题。那个时候首先我们不可能用 OpenAI,那同时我们又想要用大模型的技术。如果用 LLaMA,它是一个开源的,但它又是美国人开源的,连用一个美国人开源的项目都需要内部层层的审批。对于我们中国政府来说,数据资产不能轻易地给到海外,这是一个非常重视的问题。但因为 DeepSeek 本身公司是一个 100% 国产的公司,团队也是,所以在这方面,它其实大大地让国内有了更多的机会去做我们自己的智能体生态和大模型。
DeepSeek vs 其他大模型
回顾一下 DeepSeek 这一年的进展,真是令人瞩目。V1 版本的模型应该是在 2020 年的第一季度到第二季度之间发布的。随后,R1 版本在 2024 年 1 月 20 日发布。这四个大版本的模型都做出了巨大的贡献。我自己特别关注 V2 版本,顺便提一下,在我的 《Al 全栈开发实战营训练营》 里也讲过这个版本。当时,DeepSeek V2 正好在进行微调训练营,我那一节课重点讲了 MoE 架构。从 1970 年代到 2024 年,我们看到 Mixtral,所谓“欧洲的 OpenAI”,曾经也风光一时,在 2024 年 5 月的时候,它还在榜单上名列前茅。然而,DeepSeek V2 出现之后,Mixtral 的声音就渐渐小了。
2024 年 12 月,V3 版本开源了。V3 开源之后,我们看到它在和哪些模型竞争呢?LLaMA 3.1 的 4000 亿指令微调的模型,以及 GPT-4O 去年 5 月份的模型,还有 Claude 3.5 的模型。V3 已经在和所有的一线公开模型竞争了,并且在一些特定维度上,比如 MMLU 语义理解、数学能力等方面,都已经非常领先了。
R1 版本在 2024 年 1 月的时候进一步赶超了 OpenAI 的 GPT-1,这也促使从 1 月到现在,我们看到 Sam Altman 非常焦急,整个 OpenAI 的发布节奏变得非常混乱。GPT-5 不发了,先发一个 GPT-4O。DeepSeek R1 大家都知道是个好模型,而且它发了很多款模型。我在和很多企业和领导沟通的时候,他们都不太明白为什么有这么多 R1。技术岗的同学应该能明白什么叫蒸馏。国内的媒体又非常喜欢这种简称,比如满血版。但在企业里真正使用的时候,我相信绝大部分可能还是会选择 DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-67B 这尺寸的模型,因为它们又快又好。

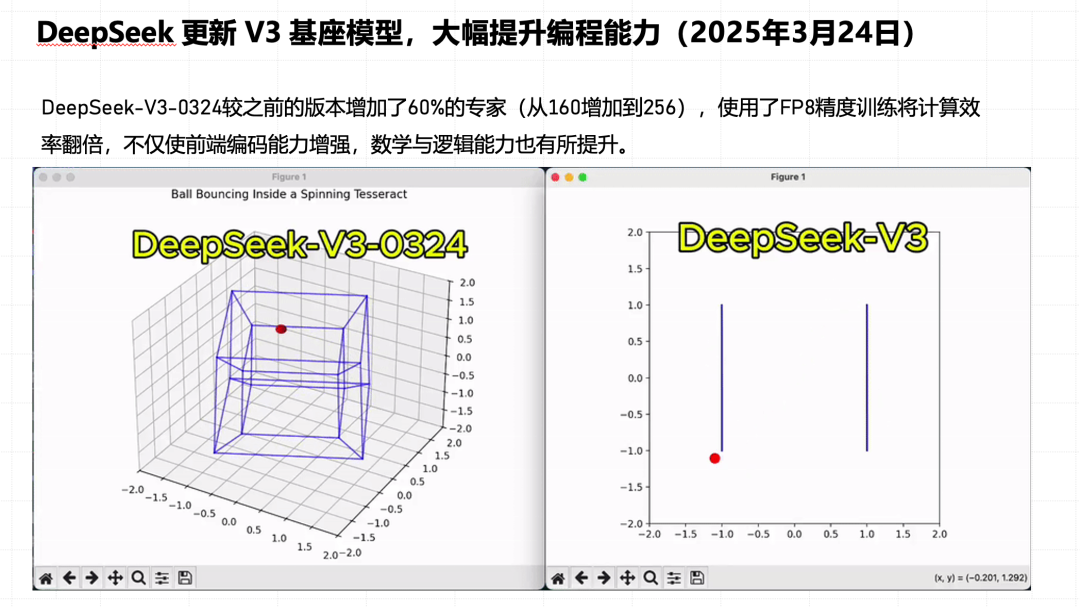
3 月 24 日,V3 低调地更新了一版,甚至没有更新它的版本名称。这一版模型其实把它的 MoE 里面的专家数量从 160 个提升到了 256 个,并且用更低的精度做了一个训练,效果非常好。新版本和旧版本的对比,同时在右边这幅图里,我们看到这是之前的 V3,这是 3 月份更新之后的 V3。Meta 这家公司把它称为 V3.1,它已经用一个非推理模型把一些推理模型甩在身后了。这是一个非常强的事情,因为大家知道 R1 的训练原理就能理解 V3 吐出了一些基本的数据集去训练 R1 Zero,然后左脚踩右脚地训练出了 R1。内部公开出来的模型肯定不是最新的。那么它内部有没有更强的 V3?那个 V3 在训练什么?在 4 月份的那篇论文又把后训练的论文公布出来了,所以其实很好猜,他们已经 R1 走到后训练的阶段了,R2 也走到后训练的阶段了。
2025 年 3 月 25 号,Gemini 2.5 Pro 低调发布之后,实力非常强。但国内大家用这个模型比较麻烦。我还调研了一下像腾讯这些几个大厂能用 OpenAI 的模型,因为微软开放了企业级的 API,也可以用国内的 DeepSeek,但是好像用 Google 的模型一直都比较有障碍。2.5 Pro 当时在早上,北京时间的白天,北美时间的早上发布,发布之后还恶搞了一下 Sam Altman,把他头发移掉,然后让哈士奇去抽雪茄,然后抱抱脸加一点小动作。

结果同一天,北美时间的凌晨,北京时间的 26 号,GPT-4O 就发布了。Sam Altman 直接就说,我先发个 GPT-4O 的更新,GPT-5 可能要晚一些发布。我一直觉得 Google 很惨,特别像大模型界的汪峰。每次有热点,Gemini 2.0 Flash 发布的时候也有热点抢风头,2.5 PRO 发布的时候也是被抢了风头。大家可以看看这个榜单 LMSYS。这个组织是由美国一帮高校 Stanford、UCSD 等等组建的一个非营利性的组织。这个组织其实有一个相对比较严肃的榜单,不像 Hugging Face 上的 LLM Benchmark。我们看到 Gemini 2.5 Pro 其实挺强的,分数也很高,然后 GPT-4O。

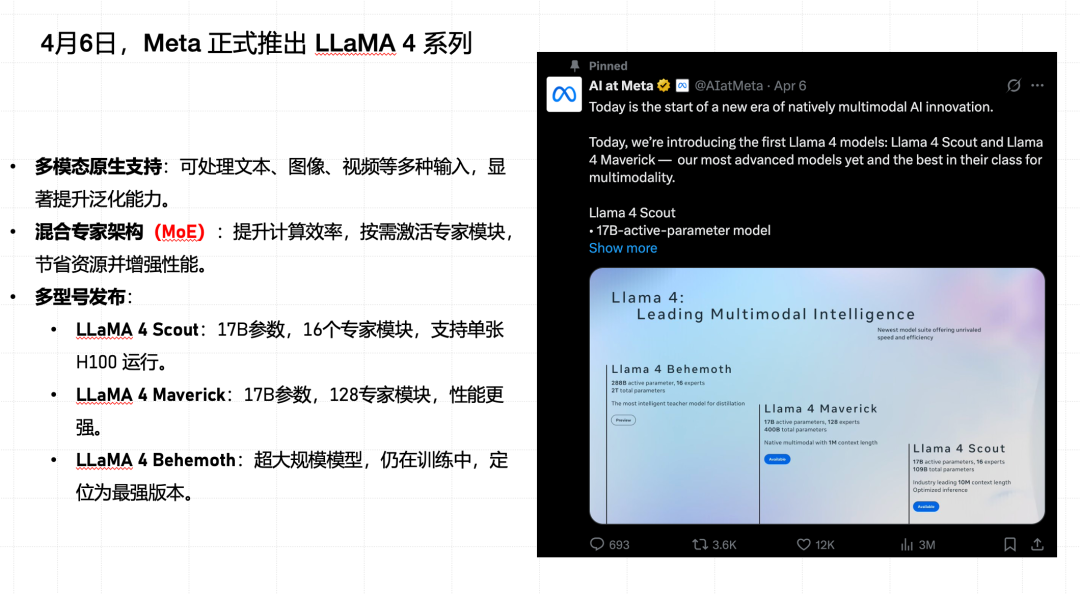
4 月 6 号,Meta 推出了 LLaMA 4 系列,有几个改动是比较大的。第一个就是多模态的原生支持,第二个就是他自己开始用 MoE 了,成本也逐步降下来了。
在当今快速发展的技术领域,从业者们普遍渴望在变革中保持自身价值,不被新兴技术所取代。技术细节固然至关重要,但对宏观技术趋势的全面了解同样不可或缺。毕竟,个人精力有限,不可能对每一项技术都进行深入钻研,但必须清楚那些在专业领域深耕的公司和团队已经达到了何种高度。我衷心希望这些团队能够将模型技术推向极致,如此一来,我们便可以借助他们的成果,站在巨人的肩膀上进行应用开发。
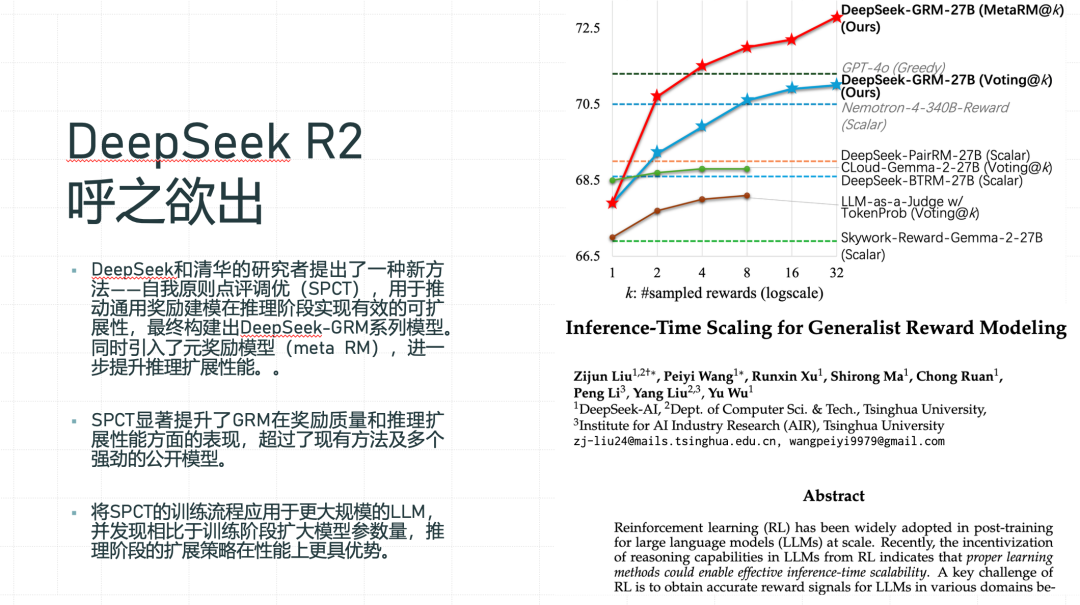
下面这张 PPT 推荐的论文也极具阅读价值。强化学习在大模型训练中的应用,自 R1 版本起便已证实其可行性。然而,在后训练阶段,强化学习面临一个核心难题:如何构建有效的 Reward Model,即如何确保反馈机制的精准与高效。在这方面,相关研究已取得突破性进展。在 Post Training 阶段,通过大模型训练结合强化学习,研究者们找到了一种有效的方法——即 SPCT,这一方法为解决上述问题提供了新的思路和方向。
创新实践:企业如何重构人才价值链
善于运用 AI 的程序员,也可能成为取代我们的力量。那么,他们究竟是如何实现这种取代的呢?在回答这个问题之前,我们或许应该先思考一下,企业为何会做出这样的选择,决定员工的去留呢?这背后,企业的考量究竟是什么?在 AI 时代,我们将着重探讨后两种情况。
从企业和人才的视角来看,企业和人才之间的关系本质上是双向选择的。无论时代如何变迁,哪怕是在当前经济形势不佳的时期,只要你是真正的人才,就应当具备被选择的资格。人才与企业之间的双向选择,最为关键的要素在于目标的一致性与对齐。人才在企业中追求的是发展,这种发展体现在技能的提升上。而随着技能的提升,人才自然期望获得相应的回报,这可能表现为职级的晋升,也可能体现为薪酬待遇的增加。
这三者——个人发展、技能提升和薪酬回报——如何与企业的需求相对应呢?在个人发展的过程中,不能一味地自由生长,企业是有明确战略的。通过 KPI 或 OKR,我们可以实现目标的对齐。只有当个人的发展方向与企业战略高度一致时,才能在企业战略的执行中实现双赢。
从技能方面看,如今许多人关注自己的技术栈,思考技能是否足够深入或广泛。然而,对于企业而言,它们更关心的是团队能否高效完成任务。一个团队中,每个人都有自己的技能,但如果大家各自为政,就像八仙过海各显神通,那么团队的整体效能将大打折扣。理想的团队协作应该是这样的:即使是两位资深的专家,也能够相互协作、互补,共同推动项目前进。因此,对于企业来说,你 的技能固然重要,但更重要的是你是否能够在团队中实现有效协作。如果你能够与另一位专家协作,甚至引领他们,使团队方向一致,那么你未来就有可能成为能够与专家协作甚至调度专家的人才。
从业绩上看,只有当业绩得到提升,薪酬才有可能增加。如今,VC(风险投资)时代已经过去,企业不能再依靠融资来随意增加薪酬。今天,企业需要真正能够创造价值的人才,只有产生实际价值,才能有相应的薪酬回报。这是我们在当前形势下必须面对的现实。
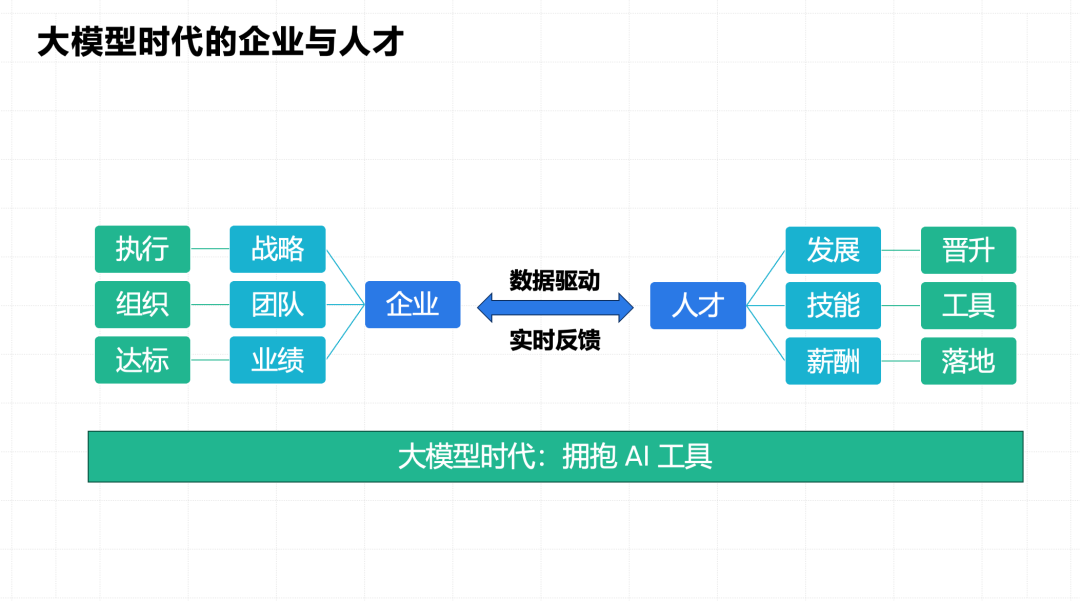
从企业角度来看,它们的诉求与我们是一致的,甚至更为迫切。我曾在上一家公司管理过大约 100 人的研发团队。那时,我最担忧的问题是:今天睡一觉,第二天醒来要发出去多少钱?当你的思维视角发生变化后,你所考虑的问题也会随之改变。你可能会计算,有 100 个人,每天的工资是多少?是否能产生相应的价值?当企业规模扩大到几万人、几十万人时,这种焦虑只会更加强烈。因此,企业必须解决这个问题。在大模型时代,我们看到许多企业致力于内部提效,包括我们自己,也在努力解决企业内部的问题。我们的考核逻辑可能是 20% 的自由增长,80% 与公司目标一致。我认为,在大模型时代,企业一定会采取这样的行动。如果我们能够理解这一点,就可以优化自己的表现。所有的研发人员都是聪明的,了解了机制,就可以善于运用机制。了解了企业的评价方式,我们就可以在表现上做得更好。

除了前面提到的三个对齐之外,我看到许多企业在从招聘开始,到希望留住人才的整个过程中,都在全方位地拥抱 AI。现在,我们面临的第二个挑战就是会用 AI 的程序员。那么企业如何面对那些会用 AI 的程序员呢?从招聘环节开始,对于那些从未工作过的应届生来说,在招聘环节花费了最多的精力。我们看到,现在有许多公司在为招聘候选人提供工具,例如在线笔试的辅助工具。当问题发过来后,不同的大模型会同时给出回答,然后你可以整合这些回答来完成笔试。这非常简单,所以现在的笔试对于会用 AI 的程序员来说已经没有意义了。但如果有些同学在笔试时仍然自己回答问题,就会显得慢一些,或者不够机智。
面试也可以用 AI 来帮助回答问题。AI 实在太全面了。如果一个人回答得更全面,面试官可能没有那么多评判能力和标准,他们被录用的几率就更高。如果你在寻找工作,而你的竞争对手是熟练运用 AI 的人,你能赢过他们吗?AI 工具已经在影响我们的许多环节了。从企业的招聘角度来看,也有一些应对方案,就是 AI 对 AI。你用 AI 来回答我的笔试题,我用 AI 来出笔试题,然后 AI 再出评审报告。你用 AI 来面试,我找个数字人面试官来问你。最终,这反而变成了 AI 对 AI,看谁的 AI 用得好。你可以想象,那些不会用 AI 的人,在这一环节就已经被淘汰了。
入职后:培养与发展
入职后,我们该如何进一步提升自己呢?在公司里,大家可能都经历过这样的时刻:每年发完年终奖,很多人都会萌生去意。这就像婚姻中的“七年之痒”,企业里也有“四月之痒”。不过,由于当前的经济环境,这种离职的冲动似乎没有过去那么强烈了,年终奖的吸引力也有所下降。但不管怎样,企业总是希望在现有员工中培养自己的人才。虽然外部人才也很优秀,但自己培养的人才往往更了解公司文化,更容易融入团队。说到培养人才,我想在这里打个小广告。极客时间的企业版 可以很好地解决这个问题。它为员工提供个性化的培训计划和完整的评估流程,帮助企业和员工共同成长。
拥抱未来:AI 时代企业人才管理体系
如何成为不被 AI 取代的工程师或企业呢?这其实与前面提到的三条线相对应。首先,目标必须一致。作为一名工程师,我认为第一点是把 AI 当作手机一样看待。它并没有那么神奇,也没有那么具有侵略性,它只是一个工具。如果你能用这个工具解决问题,那就用吧。我们并没有规定你必须用到什么程度。虽然有些企业现在要求每个团队的 AI 使用率或覆盖率要达到多少,这是从管理者的角度出发,他们需要量化评估。但从个体角度看,你越频繁地使用这种工具,当然能更有效地解决问题,提升工作效率。
第二点是终身学习。我们都知道,大学里学到的知识大多已经忘得差不多了,更多是在公司和社会这所大学里学到的软技能和硬技能。在当今时代,信息迭代速度极快,知识的有效期非常短。有些知识的有效期可能只有一个月,甚至只有几天。特别是针对一些特定大模型的提示词,它的有效期可能很短。下个月用于某个任务的模型可能已经不是原来的那个了,提示词可能就失效了。这时,我们看到 MCP、AtoA 等新工具应运而生。但无论如何,学习能力,尤其是终身学习的能力,至关重要。
第三点是我们需要构建一个协同共生的系统。从企业的角度看,是要保留优秀人才。有了 AI 之后,我们可以更高效地从大量员工中筛选出真正的人才。
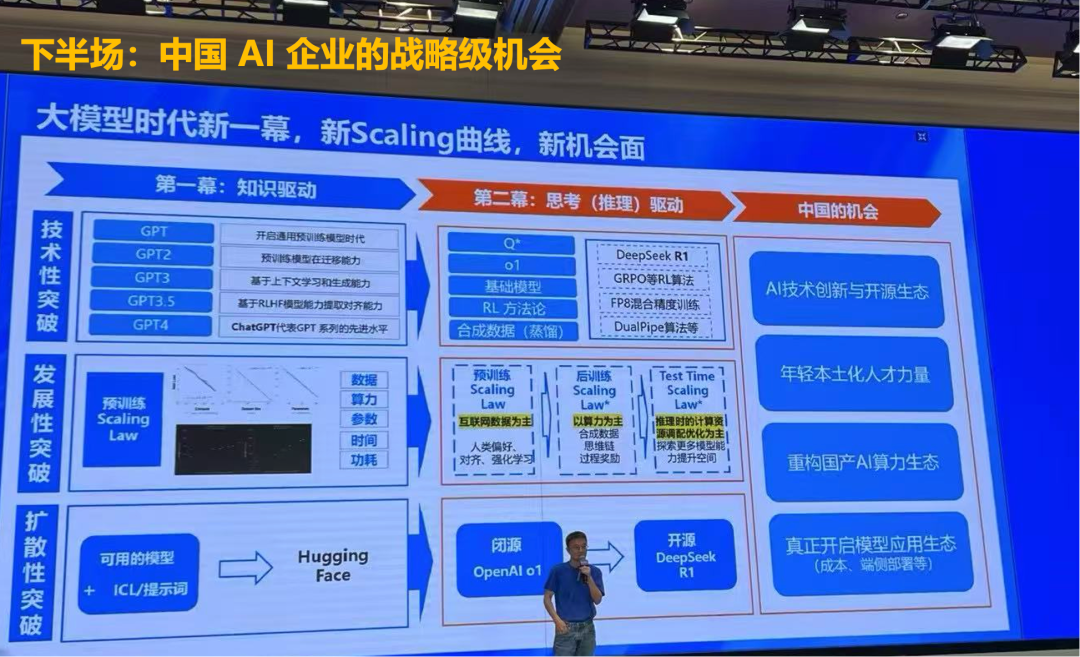
最后,我想给大家打打气,激励一下。在陆奇老师的“奇绩创坛”内部分享中,他提到中国 AI 企业在下半场有战略级的机会。从技术角度看,大模型的机会在于推理驱动的模型。上半场知识驱动的大模型时代已经结束,推理驱动的模型才刚刚开始。R1、Claude 和 OpenAI 都在跟进,R2 也即将推出。在整个下半场,中国在推理驱动的大模型领域有先发优势。中国人非常勤奋,我们有更多的创新生态,数据使用限制较少,没有 GDPR,也没有像旧金山市长那样禁止安装摄像头的限制,所以机会很大。同时,国家政策也非常支持,无论是硬件还是招商引资,力度都非常大。我觉得下半场我们有很多机会。
极客时间刚刚上线了一个 《Al 全栈开发实战营训练营》,完整覆盖了从 AI 应用层到算力层的四个技术层次。我做这个课程的初衷很简单:如果你之前不是 AI 开发人员,这门课可以作为你的入门课程,让你了解所有的技术栈;如果你本身就有这方面的素养,也可以通过这门课了解如何在企业中推动 AI 应用,如何让自己更上一层楼。
演讲嘉宾介绍
彭靖田,上海载极数据科技 创始人 / CEO ,中嘉数字科技(浙江)总经理,谷歌开发者专家,谷歌出海创业加速器导师。加州大学访问学者,毕业于浙江大学竺可桢学院。
连续创业者:3 家公司成功退出(字节收购,股权退出)。华为公司 2012 实验室深度学习团队成员,从零到一参与了华为深度学习平台和华为深度学习云服务的设计与研发工作。2017 年作为技术合伙人加入才云科技(2020 年被字节全资收购,成为字节火山云),负责 AI Cloud 产品和解决方案。2019 - 2023 年担任品览数据联合创始人兼 CTO,带队自主研发 AI 智能工程设计云平台 AlphaDraw「筑绘通」, 是国内有报道的以 AI 生成式算法赋能建筑设计并实现 AI 自动制图和 AI 生成模型的领先科技企业,累 计融资近 2 亿元。
行业布道者:Linux 云原生基金会(CNCF)程序委员会成员,深度学习和大模型培训学生超 10 万人。 开源项目 Kubeflow 维护者,TensorFlow 贡献者。国内第一本深度剖析 Google AI 框架的畅销书《深 入理解 TensorFlow》作者。极客时间《企业级 Agents 实战营》、《 AI 大模型应用开发营》和《 AI 大模型微调训练营》作者。




