9 月 13 日,元象 XVERSE 发布中国最大 MoE 开源模型:XVERSE-MoE-A36B。该模型总参数 255B,激活参数 36B,能达到 100B 模型的性能「跨级」跃升,同时训练时间减少 30%,推理性能提升 100%,使每 token 成本大幅下降。
并且,元象「高性能全家桶」系列全部开源,无条件免费商用,海量中小企业、研究者和开发者能按需选择。

MoE(Mixture of Experts)是业界前沿的混合专家模型架构 ,将多个细分领域的专家模型组合成一个超级模型,打破了传统扩展定律(Scaling Law)的局限,可在扩大模型规模时,不显著增加训练和推理的计算成本,并保持模型性能最大化。出于这个原因,行业前沿模型包括谷歌 Gemini-1.5、OpenAI 的 GPT-4 、马斯克旗下 xAI 公司的 Grok 等大模型都使用了 MoE。
免费下载大模型
Hugging Face:https://huggingface.co/xverse/XVERSE-MoE-A36B
魔搭:https://modelscope.cn/models/xverse/XVERSE-MoE-A36B
Github:https://github.com/xverse-ai/XVERSE-MoE-A36B
商业应用上更进一步
元象此次开源,在商业应用上也更进一步。
元象基于 MoE 模型自主研发的 AI 角色扮演与互动网文 APP Saylo,通过逼真的 AI 角色扮演和有趣的开放剧情,火遍港台,下载量在中国台湾和香港娱乐榜分别位列第一和第三。
MoE 训练范式具有「更高性能、更低成本」优势,元象在通用预训练基础上,使用海量剧本数据「继续预训练」(Continue Pre-training),并与传统 SFT(监督微调)或 RLHF(基于人类反馈的强化学习)不同,采用了大规模语料知识注入,让模型既保持了强大的通用语言理解能力,又大幅提升「剧本」这一特定应用领域的表现。

在商业应用上,元象大模型是国内最早一批、广东前五获得国家备案的大模型,可向全社会提供服务。

从去年起,元象大模型已陆续与 QQ 音乐、虎牙直播、全民 K 歌、腾讯云等深度合作与应用探索,为文化、娱乐、旅游、金融领域打造创新领先的用户体验。目前,元象累计融资金额已超过 2 亿美元,投资机构包括腾讯、高榕资本、五源资本、高瓴创投、红杉中国、淡马锡和 CPE 源峰等。
MoE 技术自研与创新
MoE 是目前业界最前沿的模型框架,由于技术较新,国内外开源模型或学术研究同步探索。元象在此次升级中围绕效率和效果进行了如下探索:
效率方面
MoE 架构与 4D 拓扑设计:MoE 架构的关键特性是由多个专家组成。由于专家之间需要大量的信息交换,通信负担极重。为了解决这个问题,元象采用了 4D 拓扑架构,平衡了通信、显存和计算资源的分配。这种设计优化了计算节点之间的通信路径,提高了整体计算效率。
专家路由与预丢弃策略:MoE 的另一个特点是“专家路由机制”,即需要对不同的输入进行分配,并丢弃一些超出专家计算容量的冗余数据。为此元象团队设计一套预丢弃策略,减少不必要的计算和传输。同时在计算流程中实现了高效的算子融合,进一步提升模型的训练性能。
通信与计算重叠:由于 MoE 架构的专家之间需要大量通信,会影响整体计算效率。为此团队设计了“多维度的通信与计算重叠”机制,即在进行参数通信的同时,最大比例并行地执行计算任务,从而减少通信等待时间。
效果方面
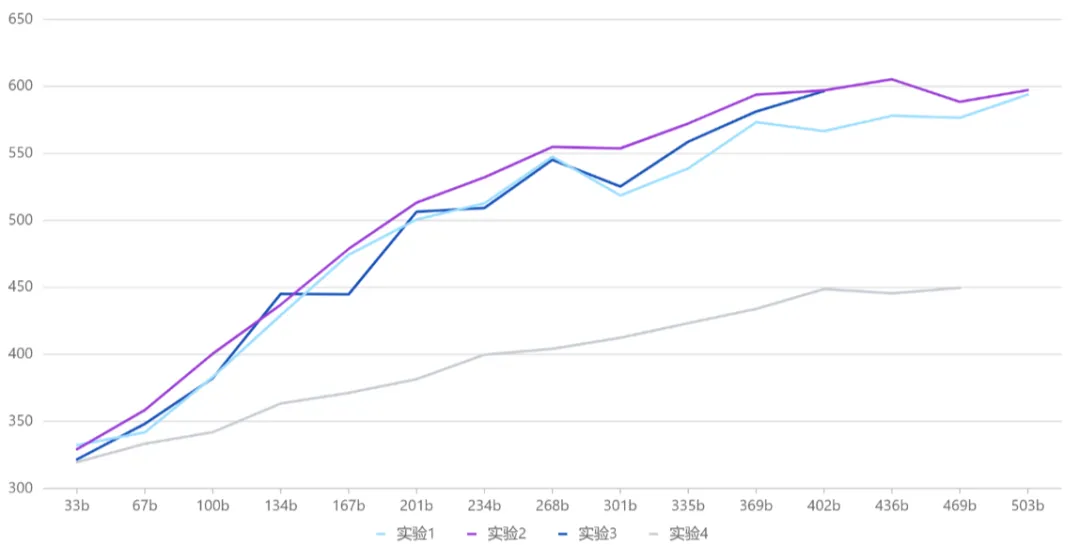
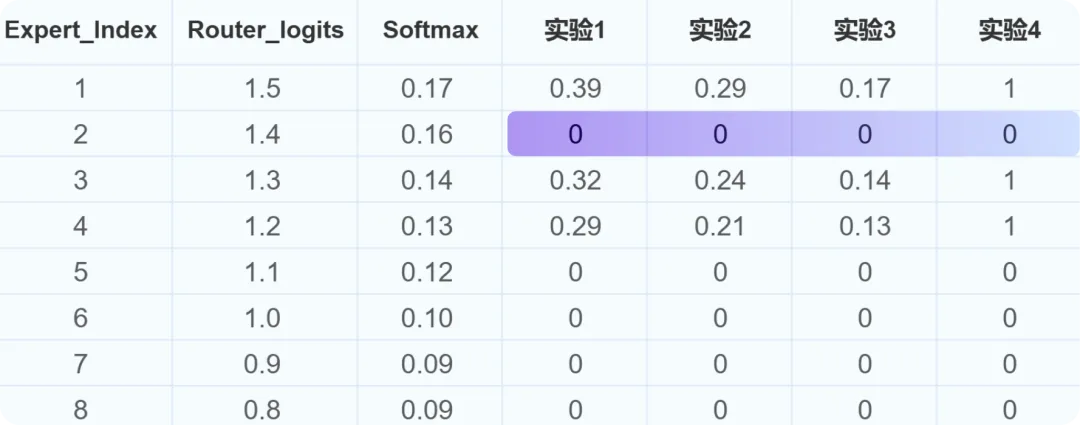
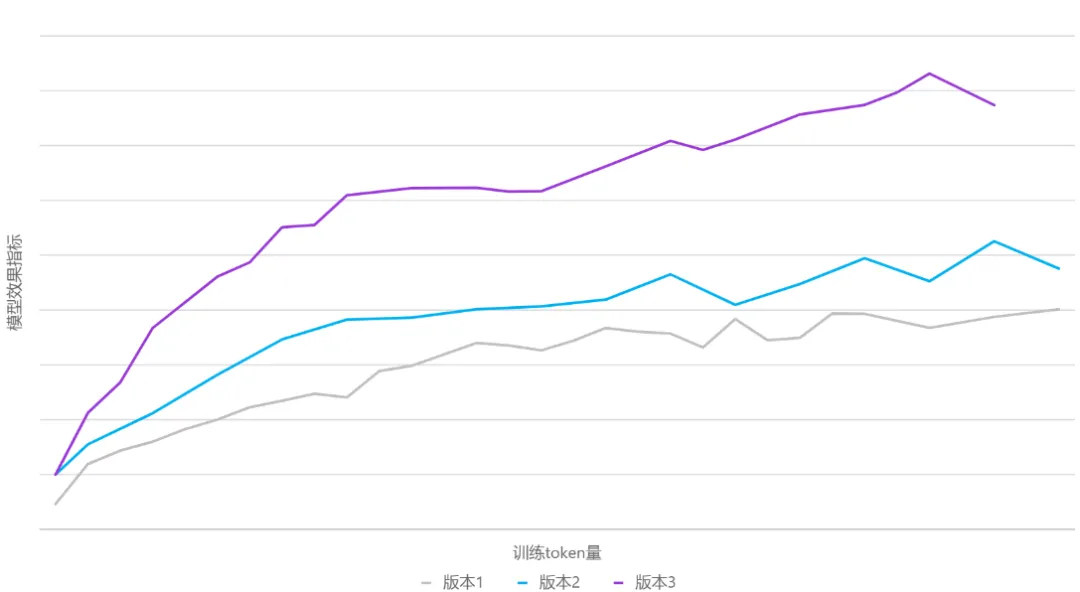
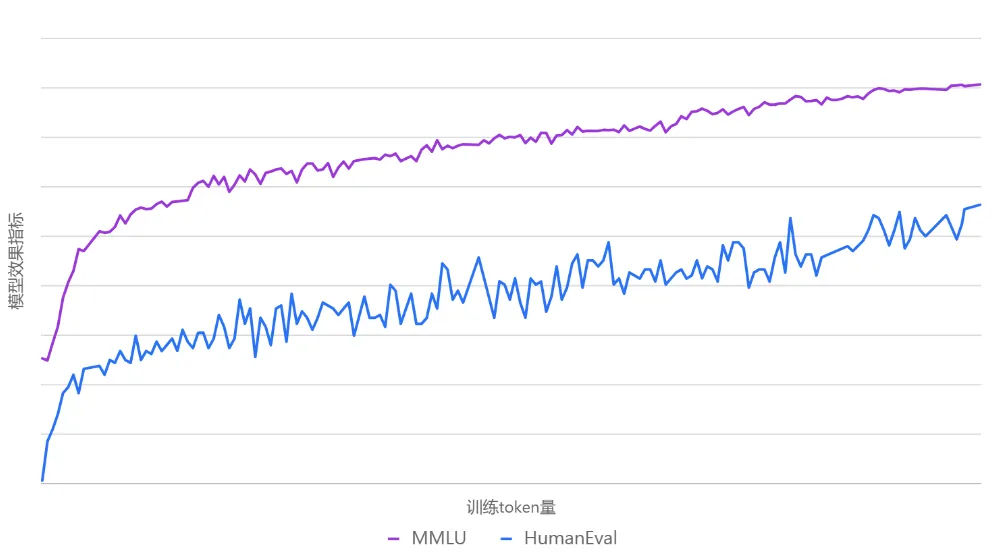
专家权重:MoE 中的专家总数为 N ,每个 token 会选择 topK 个专家参与后续的计算,由于专家容量的限制,每个 token 实际选择到的专家数为 M,M<=K 实验 1:权重在 topM 范围内归一化 实验 2:权重在 topK 范围内归一化 实验 3:权重在 topN 范围内归一化 实验 4:权重都为 1 对比实验结果 举例说明,假设 N=8,K=4,M=3(2 号专家上 token 被丢弃),不同专家权重的计算方式所得的权重如下图: 数据动态切换:元象以往开源的模型,往往在训练前就锁定了训练数据集,并在整个训练过程中保持不变。这种做法虽然简单,但会受制于初始数据的质量和覆盖面。此次 MoE 模型的训练借鉴了"课程学习"理念,在训练过程中实现了动态数据切换,在不同阶段多次引入新处理的高质量数据,并动态调整数据采样比例。 这让模型不再被初始语料集所限制,而是能够持续学习新引入的高质量数据,提升了语料覆盖面和泛化能力。同时通过调整采样比例,也有助于平衡不同数据源对模型性能的影响。 不同数据版本的效果曲线图 学习率调度策略(LR Scheduler):在训练过程中动态切换数据集,虽有助于持续引入新知识,但也给模型带来了新的适应挑战。为了确保模型能快速且充分地学习新进数据,团队对学习率调度器进行了优化调整,在每次数据切换时会根据模型收敛状态,相应调整学习率。实验表明,这一策略有效提升了模型在数据切换后的学习速度和整体训练效果。 下图是整个训练过程中 MMLU、HumanEval 两个评测数据集的效果曲线图。 训练过程中 MMLU、HumanEval 的性能曲线持续拔高 通过设计与优化,元象 MoE 模型与其 Dense 模型 XVERSE-65B-2 相比,训练时间减少 30%、推理性能提升 100%,模型效果更佳。