
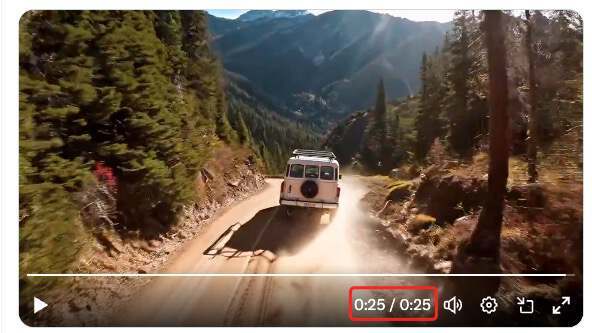
这是全球首个由 AI 生成的 25 秒视频,由字节跳动发布的 Seaweed-7B 模型生成。
字节跳动近日宣布在视频生成领域取得重大突破——Seaweed-7B。这是一个参数量仅为 70 亿的视频生成基础模型,该模型在核心任务上的表现超越了参数量为其两倍的主流模型,而训练成本仅为其约三分之一。
字节跳动早在去年就开始预热 Seaweed 项目,如今,字节 Seed 团队终于放出了技术报告,详细介绍了其技术架构和应用案例,并强调了其在成本效益方面的突破。
这也是 Seed 团队成员的一次曝光。
Seaweed-7B 项目由多个团队共同研发。核心研发团队包括由蒋路、冯佳时等领导的研究团队,下设模型、数据方向和基础设施团队。此外,项目得到了朱文佳和吴永辉的支持。今年 2 月下旬,原 Google DeepMind 副总裁吴永辉正式加入字节跳动,出任 Seed 基础研究负责人。蒋路则早在去年就已加盟字节,作为前谷歌高级科学家,他曾主导谷歌的视频生成相关工作,并在多个核心产品中发挥了关键作用,包括 YouTube、云服务、AutoML、广告、Waymo 和翻译等。同时,蒋路也是卡内基梅隆大学(CMU)的兼职教授。

而他们放出来的宣传视频,这两天也让社区逐渐沸腾起来,引发了广泛而热烈的讨论。
从 Seaweed-7B 看视频生成的下一阶段
和目前主流的 AI 视频模型类似,Seaweed-7B 支持图像转视频、基于参考图像生成视频、半拟真的人物形象、多镜头切换以及高清分辨率输出等常规功能。
真正令人惊艳的是,它具备当前其他 AI 视频模型尚未实现的五项关键能力:
首先,它可以同步生成音频和视频。目前大多数模型都是先生成视频,再单独添加声音。虽然已有一些“音频驱动视频”的研究,但仍处于实验阶段。Seaweed-7B 的音画一体生成,在效率和内容一致性方面都迈出了一大步。
其次,它支持长镜头生成。OpenAI 的 Sora 虽然曾展示过分钟级视频,但公开可用版本的时长普遍仍在 20 秒以内。此次字节跳动展示的 25 秒视频不仅拉长了时长,更是在单条提示词下一次性生成,质量也远超以往拼接或续写的方式。
第三,Seaweed-7B 拥有实时生成能力。据介绍,该模型能以 1280x720 分辨率、24 帧每秒的速度实时生成视频,这在当前 AI 视频领域几乎是革命性的突破,将极大提升互动效率,也为实时创作和虚拟角色应用场景提供了新的可能性。
第四,它引入了名为 CameraCtrl-II 的功能,支持在三维世界中进行镜头调度。研究团队表示,该方法可通过设定镜头角度,生成高度一致且动态丰富的视频,甚至可作为三维视图合成器使用。
最后,模型在物理模拟与真实感表现方面也实现了显著提升。传统 AI 视频模型在处理旋转、舞蹈、滑冰等复杂动态时常显生硬,而 Seaweed-7B 的表现更为自然流畅,虽然仍有提升空间,但已明显优于过去几个月业内常见的模型效果。
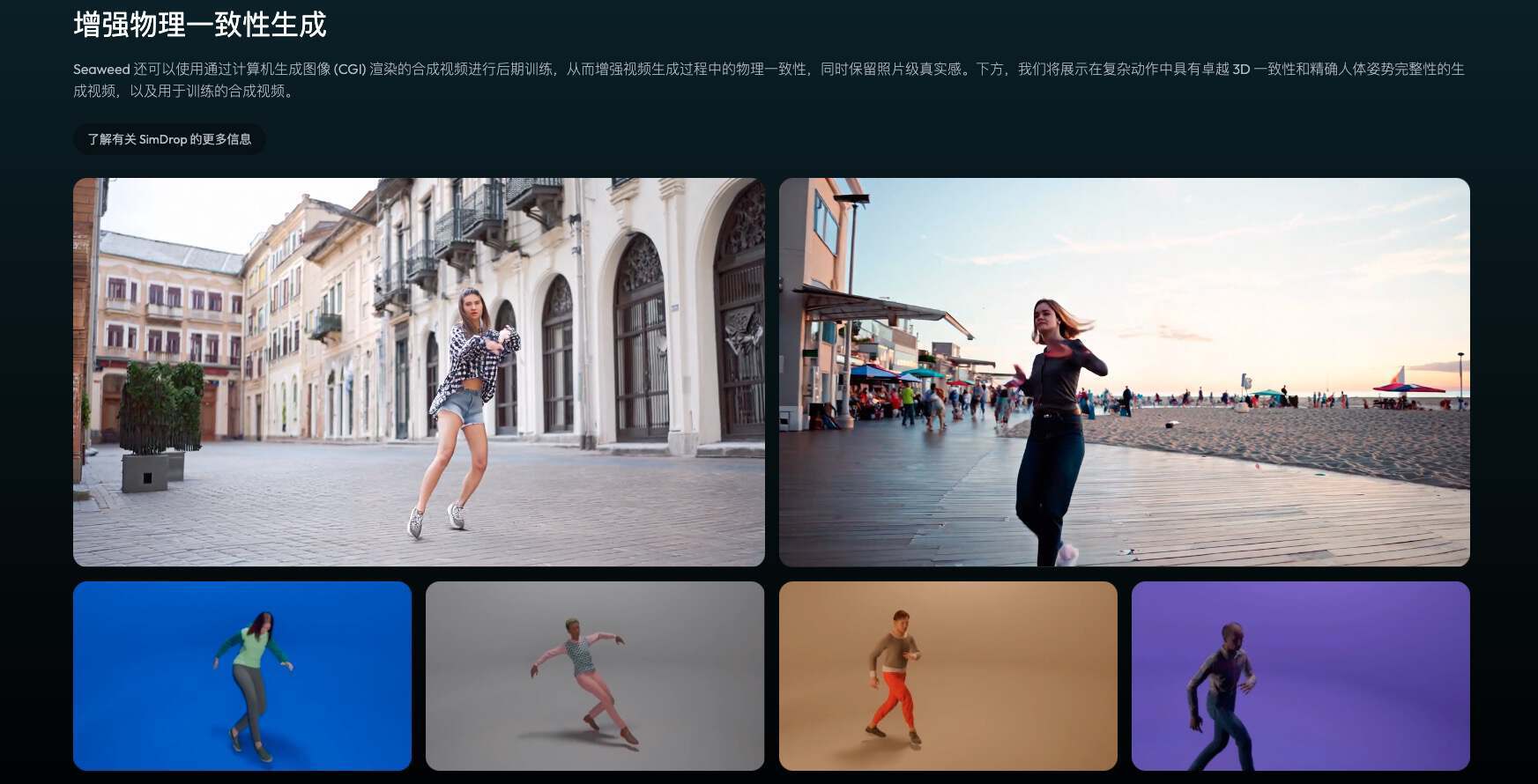
这些视频效果让很多人觉得惊艳,不少网友感叹其在实时摄像机控制、长时高清视频生成和多镜头流畅切换方面的突破,直呼“太疯狂了”、“再次惊艳中国”,尤其“实时视频生成”的概念让人联想到未来 AI 在游戏等领域的可能性。

资源受限环境中,架构设计尤其重要
虽然视频生成的许多技术都受到图像生成技术的启发,但视频生成面临着独特的挑战。与静态图像不同,视频需要对运动动态进行建模,并保持长序列的时间一致性。这些要求极大地增加了训练和推理的计算复杂度,使得视频生成模型成为开发和部署中最耗费资源的基础模型之一。
2024 年 Sora 的发布被视为视频生成领域的重要里程碑,但训练这类模型往往需要极其庞大的算力,通常动辄上千张 GPU。
Seaweed-7B 的训练成本则小很多,仅 66.5 万 H100 GPU 小时,相当于在 1,000 张 H100 GPU 上连续运行约 27.7 天。
虽然该模型仅 70 亿参数,但从图像到视频的效果能超越同类 140 亿的模型。
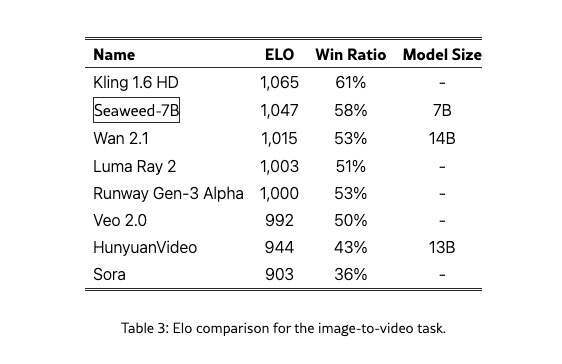
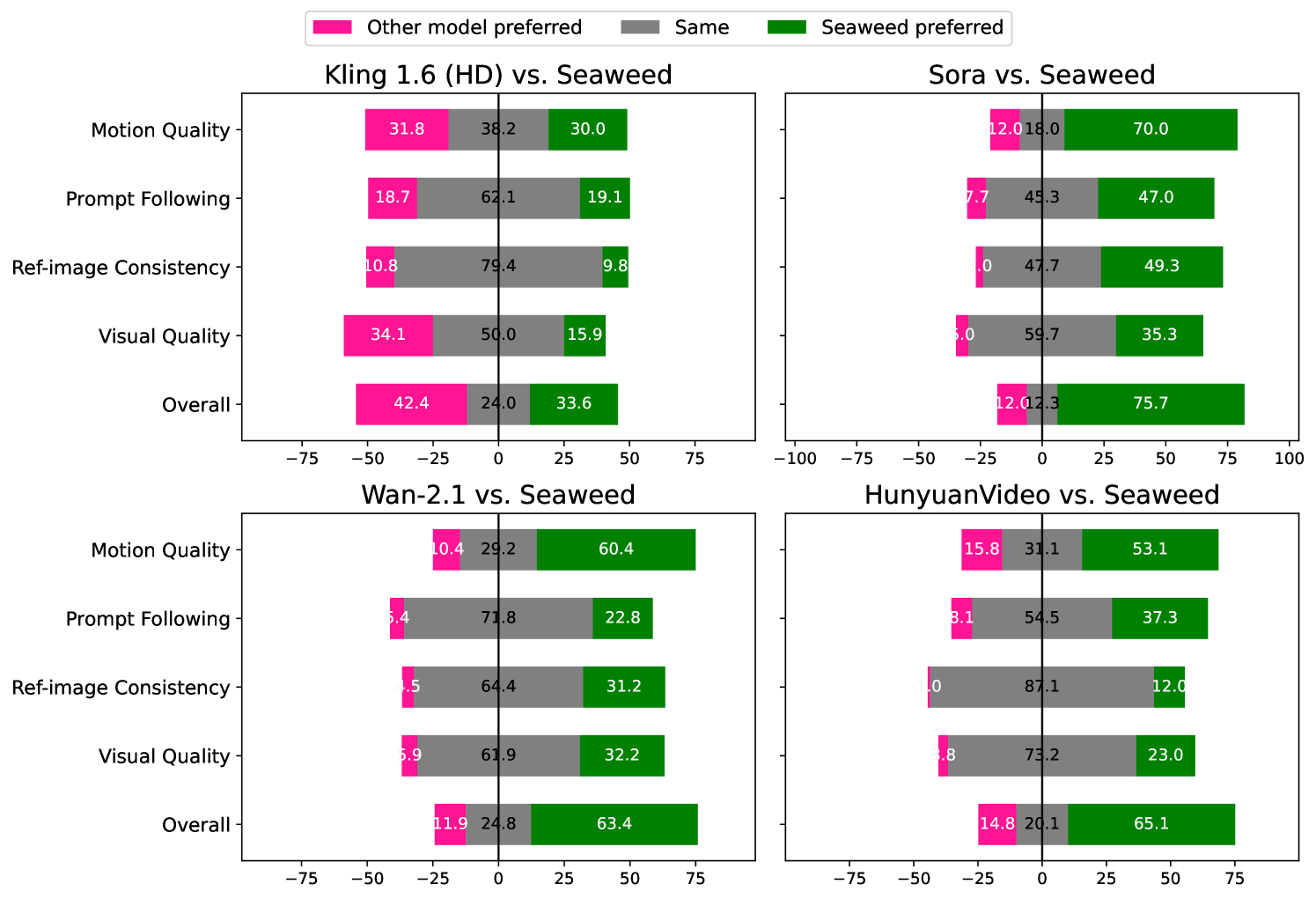
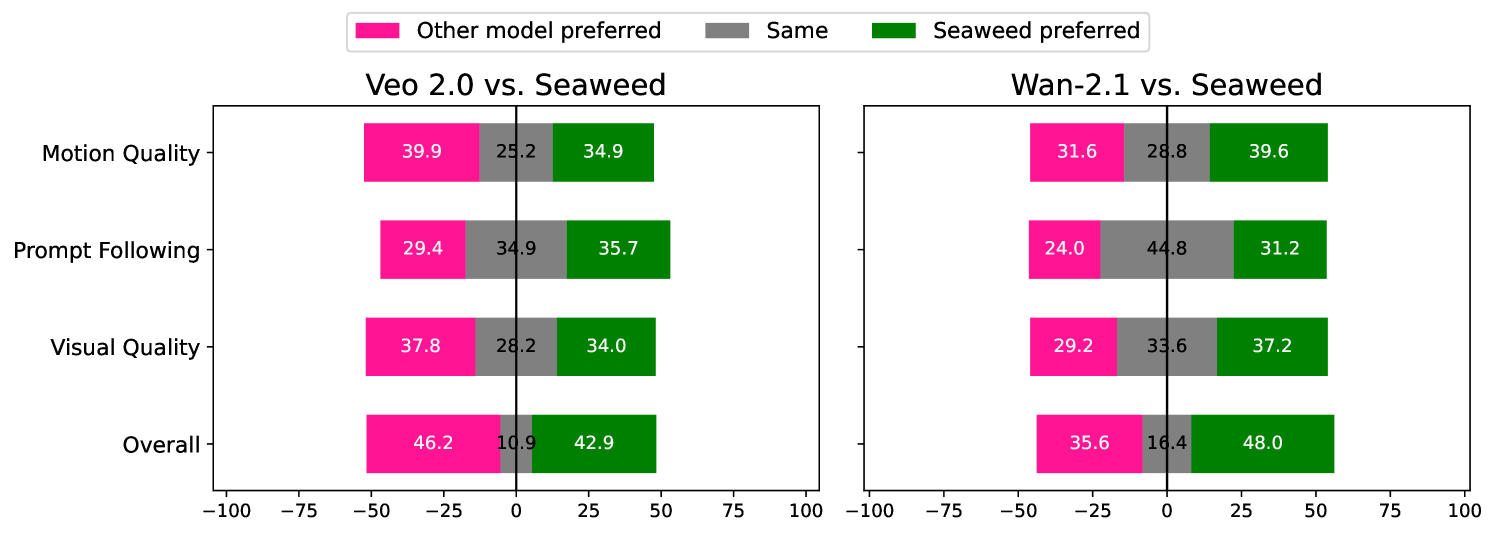
在图像转视频的任务中,Seaweed-7B 在各项指标上均大幅优于 Sora。
在文本转视频的任务中,Seaweed-7B 在 Elo 评分中位列前 2-3 名,紧随排名第一的模型 Veo 2 之后,性能与 Wan 2.1-14B 相当。
而该模型能够以显著降低的计算成本实现极具竞争力的性能,也跟背后的架构设计决策密切相关。
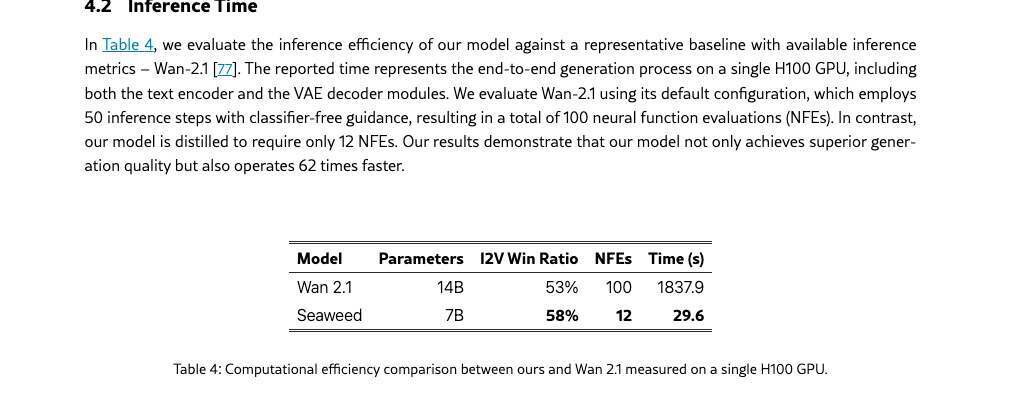
根据公开信息,该模型采用 DiT(扩散变换器)架构,并通过对抗性后训练(APT)技术优化生成速度和质量。它只需单次神经函数评估即可生成 2 秒的 720p 视频,推理速度比同类模型提升 62 倍。同时也提出了变分自编码器(VAE)设计,VAE 定义了生成真实感和保真度的上限,这可能是该模型生成的视频具有高真实感和生动运动的主要因素。
在数据上,该团队开发了一套高吞吐量且灵活的视频管理流程,包括管理视频编码和解码、执行时间分割、空间裁剪、质量过滤等。
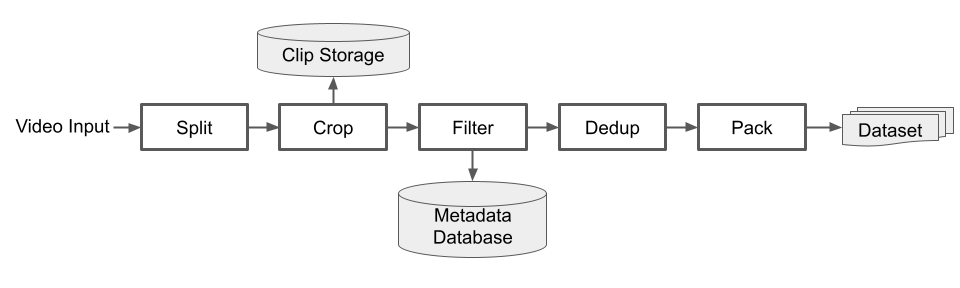
凭借这一基础架构,让 Seed 团队每天能够处理超过 50 万小时的视频数据,足以用于训练,因此可以将精力集中在有效地挖掘高质量视频片段上。为了优化视频片段处理时的吞吐量,他们使用了两个现代框架:BMF 以及 Ray 。
在 Infra 层面,字节跳动围绕“高效训练”进行了系统性的基础设施优化,显著提升了模型的算力利用率与资源效率。具体而言,团队采用三维并行策略(数据并行、上下文并行、模型切分)来应对长上下文视频训练的挑战,并引入“运行时负载均衡”机制,动态调配图像与视频样本在不同 GPU 间的分布,缓解联合训练时的负载不均问题。
此外,Seaweed-7B 还创新性地设计了多级激活检查点(MLAC)机制,支持将中间激活存储在 GPU、CPU 或磁盘等多层级介质中,不仅大幅降低了显存占用,还减少了重计算带来的性能损耗。为进一步提升训练吞吐,团队还通过 kernel 融合手段,将多个内存访问密集的操作整合到单个 CUDA kernel,显著提升了运算强度与 GPU 利用率。
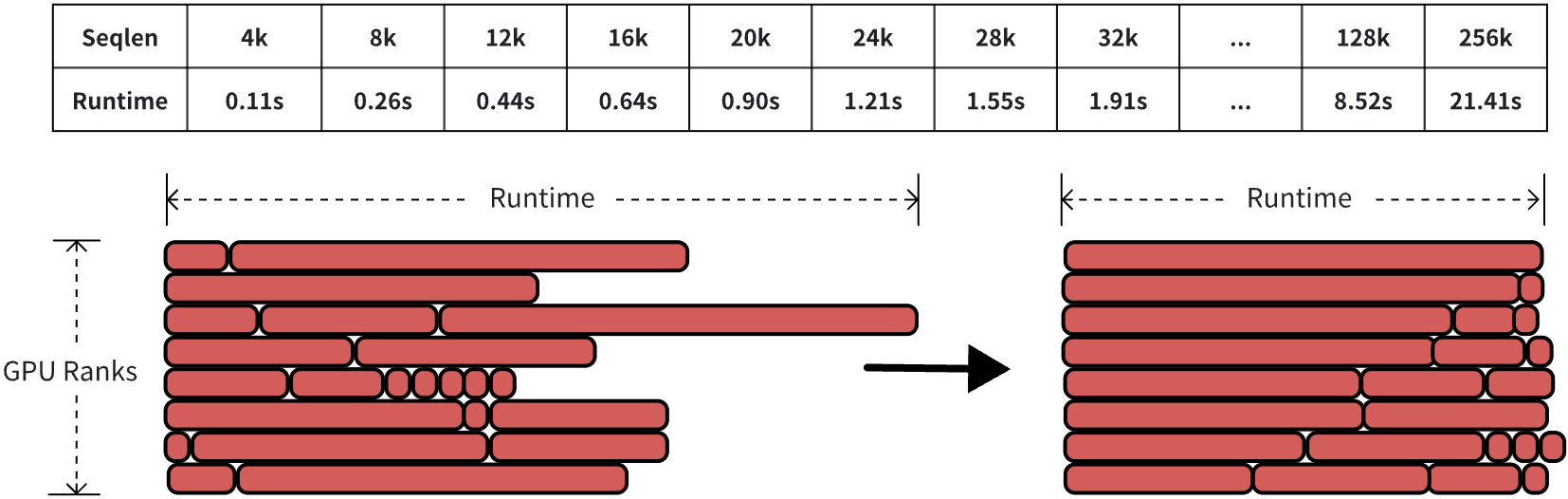
字节在论文中表示,得益于这些系统级优化,Seaweed-7B 在大规模分布式训练中实现了 38% 的 FLOPs 利用率,成为当前 AI 视频生成领域中兼顾性能与效率的代表性模型之一。
不过,有意思的是,尽管字节跳动认为其资源消耗“适度”,不少网友却对此持有不同看法,直呼“字节跳动在暗示我太穷”。
他们指出,动用上千张顶级 GPU 进行近一个月的训练,无论如何都绝非小数目,强调这依然是需要巨大算力的投入,所谓“适度的计算资源”的说法并不恰当。
“字节跳动在暗示我‘GPU 穷人’。一个训练了 66.5 万 H100 小时的模型,却被称作‘成本高效’、‘计算资源适度’。”
参考链接:




