
从技术竞争到生态共创——开放数据架构正在经历从各自为政到协同演进的根本性转变,而这种转变的核心驱动力不仅是技术本身,而是社区治理模式的成熟。
每年 6 月的旧金山,Snowflake Summit 与 Databricks Data+AI Summit 如双子星般闪耀,既是数据与 AI 行业的风向标,又是科技巨头秀肌肉的顶级舞台。作为今年 Data + AI Summit 2025 的一部分,我有幸在旧金山的 Marriott Marquis 酒店先参与了一场更为“神秘”和特别的技术峰会——Open Lakehouse Mini Summit。想在分享具体的技术干货之前,先和大家聊聊这场会议独特的“画风”。
Open Lakehouse Mini Summit 闭门会
说它独特,首先是因为这不是一场对公众开放的会议,而是在 Databricks 的协助和组织下,专门面向全球各大主流数据开源社区核心贡献者、Committer 和 PMC 成员的闭门邀请制(invite-only)峰会。你可以想象一下这个场面:来自 Apache Spark, Delta Lake, Apache Iceberg, Unity Catalog, Apache Polaris, Apache Arrow 等项目的“核心大脑”们齐聚一堂。这感觉不像一个传统会议,更像是一场数据江湖的“华山论剑”。
其次,它的会议形式也极具特色。全天没有任何冗长的 PPT 演讲,取而代之的是四个分会场里、紧锣密鼓的圆桌讨论。每一场都由一位核心维护者用最多 15 分钟做引子,抛出最具争议或最前沿的话题,剩下的超过半小时则留给所有人进行深入、激烈的现场讨论。
更关键的是,为了鼓励最真实、最坦诚甚至充满火药味的观点碰撞,所有讨论都全程闭门,不设任何录音录像。在这种绝对安全的环境下,大家可以毫无保留地探讨各个项目的未来路线图、技术方案的利弊,甚至直接“挑战”彼此的设计。
正是因为这种独特的设定,这次会议的讨论深度和广度都远超常规的技术大会,信息量极大。为了让大家对峰会的讨论广度有个更直观的了解,我根据官方日程整理了当天的完整议题表。你可以看到,四个会场同时进行,议题覆盖了从底层引擎、存储格式到上层目录和 AI 应用的方方面面,几乎囊括了当前数据技术栈所有热门和前沿的方向。
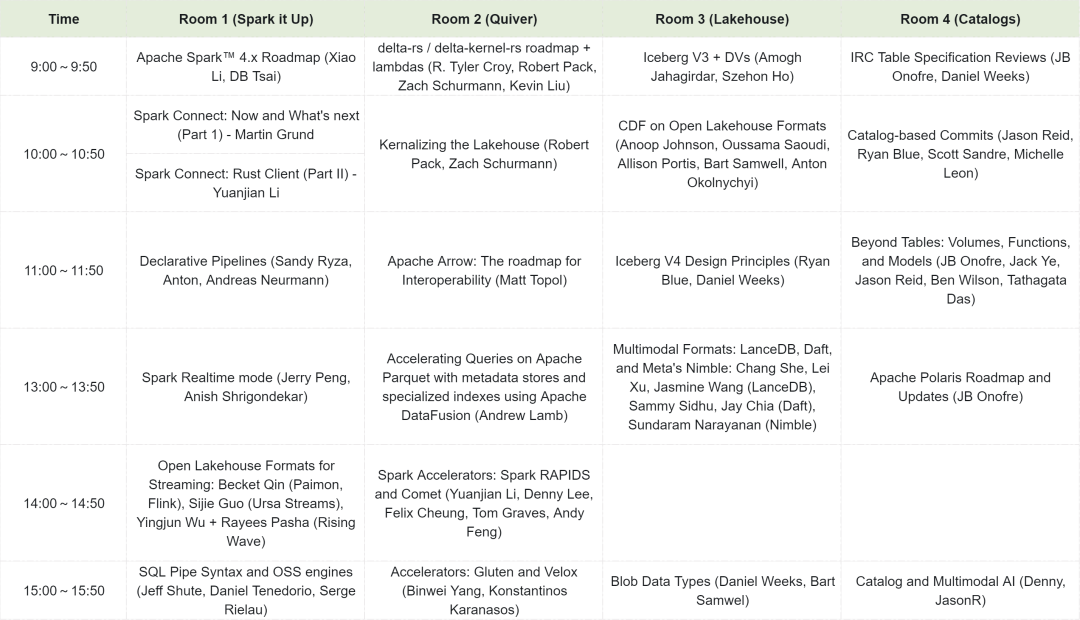
正如你所看到的,每个时间段都有多个极具吸引力的话题在同时进行,真是让人分身乏术,充满了选择的“痛苦”。我主要参加了 Lakehouse 相关(主要是 Iceberg)的话题讨论,所以接下来的内容,我将按照 Iceberg 的现在和未来,结合现场和社区小伙伴们聊天获得的一手信息,分享那些最前沿的观点和让我深受启发的思考。
Apache Iceberg 的现在
2025 年 6 月,Apache Iceberg 社区发布了 V3 表格式规范。这不仅是技术的迭代,更是数据生态从分裂走向统一的关键一步。长期以来,用户不得不在多个 table format 之间艰难抉择,而 V3 通过标准化企业级功能与跨格式兼容性,首次实现无需重写数据即可跨引擎操作——这标志着开放数据生态的质变。

2025 年 5 月 23 日社区投票通过 Iceberg V3 标准
Iceberg V3 亮点一览
下面列出了 Iceberg V3 标准引入的新功能,完整变更请查阅社区官方文档。
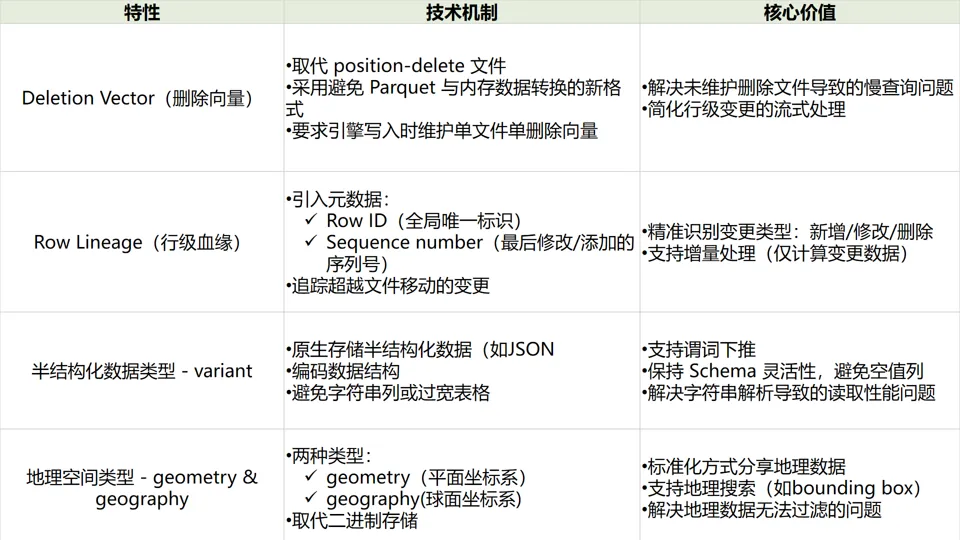
社区协作成就:开放生态的里程碑式突破
正如 Databricks 博文所述,Iceberg V3 的核心突破在于“实现 Delta Lake、Apache Parquet 与 Apache Spark 间的深度互操作性”。这背后是多个社区史无前例的技术协同:
删除向量(由 Databricks 贡献)采用与 Delta Lake 完全相同的二进制编码,使得 Spark 或 Flink 引擎可直接读取彼此修改的数据表,终结了传统表格式的引擎割据;
行级血缘机制(由 Snowflake 贡献)与 Delta Lake 的行追踪设计兼容,让变更数据流能在 Delta 与 Iceberg 表间自然流动;
Variant 与地理空间类型在 Parquet 存储层的标准化(云器科技深度参与其中),使半结构化数据和空间查询得以跨引擎原生支持。
这场协作的本质,是以开放标准取代私有实现——正如博文结语所强调的:“避免用户被迫选择格式,实现在单一数据副本上的自由操作”。
云器科技实践洞察:标准治理的攻坚之路
云器科技作为 Iceberg 的 Variant 与地理空间标准制定的全程深度参与者,我亲身经历了开放生态中技术共识达成的艰难与价值。
Variant 标准化:从分裂风险到生态公约
Iceberg 社区最初计划直接依赖 Spark 的 Variant 实现,并把 Variant 标准放到 Iceberg 中时,我们预见到潜在的社区割裂风险,极有可能导致不同表格式、文件格式和引擎研发出自己封闭的标准。为此,我们主动牵头发起 Iceberg、Spark、Parquet、Arrow 等社区的技术讨论,推动将 Spark 的实现捐赠给 Parquet 社区。这一决策并非代码迁移那么简单,而是达成多方共识将私有技术转化为公共规范。
云器科技(Singdata)因为深度参与了 Variant 类型的标准制定,在 2025 年 4 月的 Iceberg Summit Keynote 演讲中被 Ryan Blue 提及,与多家全球知名厂商并列。

地理空间标准:协调专业社区的“技术外交”
地理空间作为一个 domain knowledge 比较深的专业领域,至今各个数据库和大数据厂商都没有统一的标准和实现。Iceberg 和 Parquet 社区关于地理类型的统一堪称跨社区治理的经典案例:
我们联合 Apache Sedona(空间计算)、GeoParquet(存储标准)、Apache Iceberg 和 Apache Parquet 等社区,以及各个数据厂商如 Snowflake、Databricks、BigQuery、AWS、Wherobots、Apple,成立工作组,直面核心冲突(如统一还是单独数据类型、坐标系表达方式、不同索引支持方式等);
历时九个月,通过多次技术会议协调,最终敲定二进制存储协议(扩展 WKB 格式)与坐标系嵌入规则,并由我主笔完成 Parquet 格式规范(https://github.com/apache/parquet-format/pull/240)的编写;
该标准实现了存储层和引擎层的统一,使空间查询能穿透格式边界下推执行。
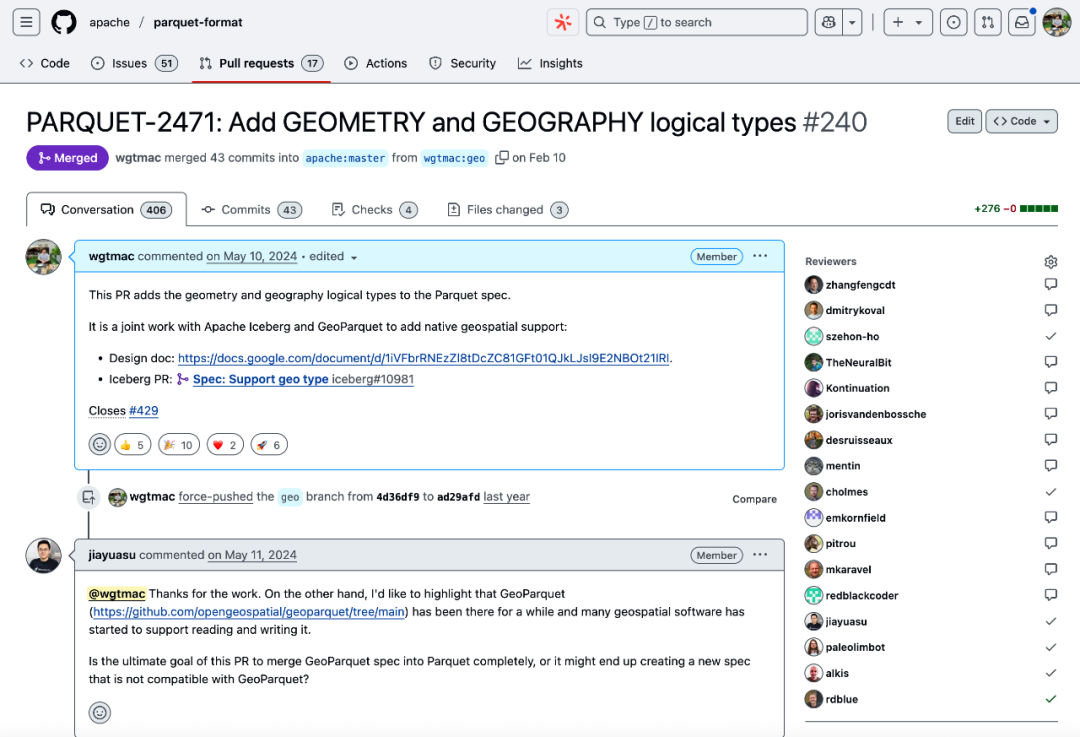
我在 Parquet 标准中加入地理空间类型的 PR,经过多轮讨论和修改,历时九个月终于被合并
真正的互操作性诞生于会议室和技术讨论而非(开源)代码库。当社区和厂商放下技术偏好,以用户数据自由为最高目标时,Delta 与 Iceberg 的二进制兼容、Variant 的 Parquet 层抽象等突破才成为可能。正如我们常听到的:“好的标准如同氧气——只有当它缺失时,你才会意识到其不可或缺”。这或许正是 Iceberg V3 留给数据生态的最大遗产:技术终会迭代,但开放治理的范式将长存。
Apache Iceberg 的未来
虽然 Iceberg V3 才刚刚定版没多久,社区成员们也没有闲着,已经在着手进行下一个版本也就是 Iceberg V4 的筹划。在 Databricks 收购 Tabular 之后,Iceberg V3 已经统一了 Iceberg 和 Delta Lake 的 data layer,这次闭门会同时也邀请到了 Delta Lake 的核心研发,一起合作讨论未来的演进方向。由于现在还在讨论的初期,现场大家基本都是分享一些初期目标和可能遇到的问题,离真正进入技术方案的设计还有一定距离。

Iceberg 最初的两位作者 Ryan Blue 和 Daniel Weeks 在现场发起 Iceberg V4 元数据演进的讨论
实时和高频写入的元数据优化:单文件提交(One-file Commit)

Apache Iceberg V4 正在酝酿一项重要的元数据格式改进,其核心目标是解决当前版本在频繁数据更新时或者数据量比较小的表在写入时,所面临的元数据写入开销问题。 目前,Iceberg 创建一个新快照(snapshot)必须至少写入一个 manifest 文件和一个 manifest list 文件,这种“多文件写入”模式在高吞吐场景下成为性能瓶颈。为此,社区提出“单文件提交”的设计思路:计划重构 v4 的元数据结构,允许 manifest list 层直接存储数据文件和删除文件的引用信息。这意味着在大多数情况下,提交一次变更只需写入一个新的元数据文件,从而显著降低事务操作的成本和延迟。
该优化方案同时瞄准了多个关联问题: 首先,它致力于减少因海量细小 manifest 文件带来的问题——这些小文件不仅需要并行读取增加开销,后续还需进行 Compaction,新的元数据维护机制旨在从源头避免它们的产生。其次,方案计划增强 metadata skipping 能力,探索支持存储兼容地理空间数据等更复杂类型的聚合列统计信息,帮助查询引擎更精准地过滤无关数据分区。最后,针对删除操作,方案考虑引入软删除机制来避免重写整个现有 manifest 文件(类似 metadata deletion vector),进一步减少 I/O 消耗。
增量计算的基石:Change Data Feed(CDF)
当前 Iceberg 和 Delta Lake 都已经具备 CDF 的基本能力:Iceberg V2 版本的 CDF 依赖引擎实现进行暴力扫描计算增量数据,Iceberg V3 则是通过 Row Lineage 标记了行级别数据变更,而 Delta Lake 则是同时支持行级血缘和输出 changelog 文件。下一代 CDF 的核心演进方向聚焦于提升实时数据处理的效率与灵活性,同时降低使用门槛,需满足以下关键要求:
零写入开销:必须支持读取时计算(computed on read),避免写入阶段的额外负载;
无标记化数据捕获:无需用户显式定义 ID 字段,直接利用表格式原生能力(如 Delta 的行追踪 row_commit_version 或 Iceberg 的行血缘 Row Lineage)自动标识变更;
高效生效化(Effectivization):针对整行变更场景,需高效识别变化(例如通过 Delta 的版本差快速定位变更行);
强兼容性:必须支持删除向量(DVs)及非新增型 Schema 变更(如列重命名、类型扩展等复杂演化)。可选方向包括允许用户指定 ID 列,以及基于自定义列值实现生效化逻辑。
在技术实现层面,社区正探索关键问题的解法:
API 设计:需统一生效化接口(如通过布尔参数切换原始 / 生效化视图,或提供独立 API);
引擎集成:定义表格式库与计算引擎的交互协议,核心是避免全表扫描,通过元数据快速定位变更范围;
Schema 处理:处理列重命名 / 类型扩展时,需决策输出结果采用变更发生时的历史 Schema 或当前统一 Schema;
生态扩展:支持非查询引擎(如流处理系统)直接消费原始非生效化数据流,并优化重复读取场景的性能;
安全与协同:探索在数据掩码(data masking)和行级过滤表中启用 CDF,同时推动 Delta Sharing 对 CDF 的原生支持。
未来 CDF 的核心价值在于平衡自动化与灵活性:通过深度集成表格式的元数据能力(如行追踪、版本比对)实现无侵入式变更捕获,同时开放用户自定义接口满足复杂场景,最终构建低开销、高兼容的实时数据流水线基础架构。
面向 AI 的多模态:BLOB 类型
面对 AI 时代下的多模态数据如文件、音频、图片和视频数据,Iceberg 和 Delta Lake 都没有很好的应对方案,两大社区联手组织了一个现场讨论,引入 BLOB 数据类型需系统性解决五大核心问题:
存储表示:需权衡数据文件(即 Parquet)内存储、外部存储或混合模式的效率差异,并决策二进制数据以独立文件还是打包(bin-packed)捆绑形式存在;同时必须确保数据完整性机制。
查询体验:需支持全对象读取、顺序扫描及随机访问等多元 API,突破海量传输的性能瓶颈,通过统计信息、布局优化和索引策略(如内容摘要)实现高效分析,关键要解决部分数据提取(如直接获取视频片段)的可行性。
治理架构:需定义存储位置策略——表级隔离或共享 BLOB 空间,明确安全模型(对象级 ACL vs 表 / 列级权限),解决与目录令牌授权、安全视图的兼容性,并验证 Delta Sharing 预签名 URL 对大文件的支持能力。
创建流程:要求提供零拷贝摄入、多格式转换等 API,支持从异构数据源生成 BLOB。
元数据设计:需确定记录粒度:基础时间戳 / 大小,或扩展 MIME 类型、内容特征(如视频关键帧);同时评估显式子类型(如 TEXT)对专用操作和索引的需求。
参与这场讨论的最直观感受,就是开源社区与企业内部的研发流程有着很大的不同。同样是面对日益增长的 AI 需求,企业内部产品迭代往往采取短周期、高频率的“快糙猛”模式,强调快速交付和灵活调整;相比之下,开源社区的功能开发流程则严谨和克制得多,涉及更广泛的讨论、更详尽的设计评审和更严格的兼容性考量,这是由于社区生态的复杂依赖关系决定了任何疏忽都可能引发连锁反应,导致漫长而昂贵的修复过程。
Lance 格式:替代 vs 融合?
Lance 是一种专为多模态数据(图像 / 视频 / 文本 / 表格)设计的高性能列式存储格式,被认为是传统 table format 的下一代演进形式,其核心优势在于:
百倍级随机访问性能:通过列式存储与硬件加速(SIMD/GPU),号称查询效率比 Parquet 提升百倍;
原生向量搜索:内置 HNSW 等索引,支持毫秒级相似性检索,无缝融合 OLAP 与向量计算;
零拷贝版本控制:通过删除标记 + 快照机制实现低成本实时更新,避免传统 LSM 架构的重写开销。
Lance 格式的核心研发 Weston Pace(也是 Arrow 社区 PMC 成员)在现场作了一场主题演讲,现场感兴趣的听众比较多,大家感兴趣的话题主要是 Lance 和 Iceberg 融合的可能性,大概有三种方式:
Lance 作为 Iceberg 底层文件格式:Iceberg 通过扩展文件格式支持(替代 Parquet/ORC),将 Lance 文件纳入其 ACID 事务体系。优势在于复用 Iceberg 的时空旅行、Schema 演进等能力,同时提升查询性能。但这种替换说实话意义不大,对于大宽表或者面向 AI(比如 feature engineering)场景仍然没有解决根本问题。
Lance Manifest 注入 Iceberg 元数据层:在 Iceberg Manifest 中嵌入 Lance Manifest,比如把 Lance 的一张表或者一个 Manifest 伪装成 Iceberg 的 Manifest 甚至一个数据文件。这个听起来有些 hack,社区很可能不会接受这个路线。
REST Catalog 统一管理:利用 Polaris 等 Catalog 协调层,将 Lance 表注册为 Iceberg 表。Lance 负责存储与索引(如向量搜索),Iceberg 提供跨引擎元数据抽象。适用于历史冷数据存 Iceberg+Parquet,实时热数据存 Lance。会后和 Weston 私下聊天,他也说这是当前 LanceDB 用户最多的用法。
无论是 Parquet 社区还是 Iceberg 社区,都已经意识到像 Lance、Nimble 和 Vortex 这样的新兴文件格式对其发起的挑战。Parquet 社区去年就已经发起了 Parquet V3 的讨论,加上前面提到的 Iceberg V4 相关讨论,未来这两个文件格式和表格式的事实标准如何演进,还是很值得期待的。云器科技也会继续深耕这两个社区,也欢迎志同道合的朋友们加入我们,一起贡献自己的力量。
一个值得关注的项目:iceberg-cpp
展望未来,Iceberg 生态还在快速发展中。除了核心功能的持续优化,社区生态的完善也同样重要。作为长期参与 Iceberg 社区的从业者,笔者一直认为 C++ 生态的缺失是个遗憾。
去年底,云器科技在 Iceberg 官方社区发起了 iceberg-cpp 项目,旨在用纯 C++ 实现完整的 SDK。目前项目在 MVP 版本,作为发起方,云器科技会持续投入资源。但开源项目的成功终究需要社区的共同参与,欢迎大家加入社区一起贡献!
iceberg-cpp 关于 MVP 的 Github Issue
Key Takeaways:
从代码开源到标准开放的协作
Iceberg V3 的成功不在于技术创新,而在于建立了跨社区协作的新模式。真正的互操作性诞生于会议室的激烈讨论和漫长协调,而非代码仓库的 PR 合并。
互操作性源于开放协作: 真正的开放湖仓架构的互操作性和自由源于社区 / 厂商协作,而非仅靠开源代码本身。
数据架构的三大演进方向已经明确
写入实时化: 通过元数据革命,尽可能优化高频和实时写入极限。
计算增量化: 实现更低成本和更高效的增量计算范式,达成流批一体。
查询智能化: 原生支持多模态数据治理与智能查询,突破非结构化数据分析。
AI 不只是应用层的事
Lance 格式的出现、BLOB 类型的讨论、向量搜索的需求,都在提醒我们:AI 正在深刻改变数据基础设施的设计理念。不是简单地在上层加个 AI 应用,而是从存储格式、查询引擎到元数据管理,整个技术栈都在为 AI 场景重新设计。这种自下而上的融合,才是真正的 AI-Native 架构。为下一代 AI 场景快速演进提供强力支撑。
作者简介:
吴刚,云器科技 Lakehouse 研发专家 Arrow Parquet & ORC PMC Member,ASF Member




