

本文是该系列的第一部分,我将在本文中讲述如何收集流行音乐的数据并清理。 目前,全部代码已经放到了GitHub上。
多年来,韩国流行音乐成为一种全球性现象,其流行程度让我感到惊讶。 所以,我决定用机器学习来分析韩国流行音乐,探索有趣的见解。 本文,我将阐述数据科学周期中的数据收集和数据清理阶段。
数据收集
为了找到数据集,我不得不在谷歌上进行了搜索,我发现了一个 Excel 文档,内含针对社交媒体和韩国流行音乐的调查,我觉得很有意思。数据集包含来自世界各地的 240 名韩国流行音乐歌迷,共有 22 个调查问题。
数据集链接:Ranman,Saanjana(2020):KPOP DATA.xlsx. figshare. Dataset.
数据清理
数据清理是重要的一步,因为需要为 EDA 和模型构建提供最干净的数据。如果放进去的是垃圾,那么从模型中得到的也是垃圾。
数据集可能有前导空格和尾随空格。因此,我决定使用函数来删除第一列的“Timestamp”,因为没有用处。
由于列名太长,我决定给它们提供代码名称,以简单地表示列名。
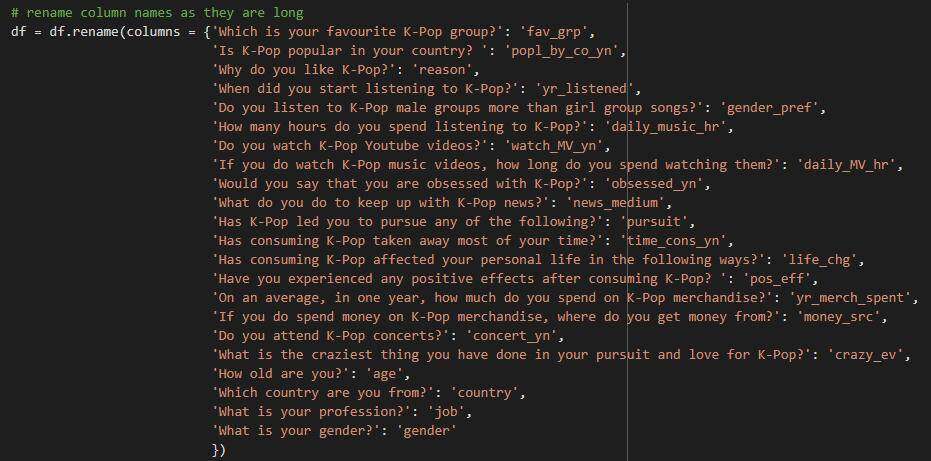
重命名列
接下来,检查数据集是否有空值。
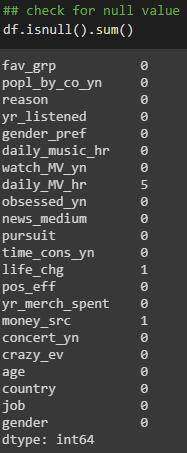
检查空值
有三个列具有空值。首先,让我们检查只有一个空值的列。
我发现 life_chg 和 money_src 中的空值是“ n/a ”,因此,我简单地将它们替换为字符串“ none ”。
对于 daily_MV_hr 列,我决定用平均值替换空值。处理空值有多种方法(删除行、分配唯一类或者运行回归模型来预测缺失值等),但我认为用平均值替换它们是最佳选择。
我取了 1 和 4 的平均值,也就是 2.5 小时,去掉了“hours”(小时)这个词。我注意到有些类别在范围内,所以为了简单起见,我取了这些范围的平均值,创建了一个特殊函数来处理这个问题。
该函数用来在一些有范围而另一些没有范围的情况下查找平均值。

清理 daily_MV_hr 列前后对比
我意识到这个数据集有点混乱。所以我重复了类似的步骤来清理每一列。
“
yr_listened” 列
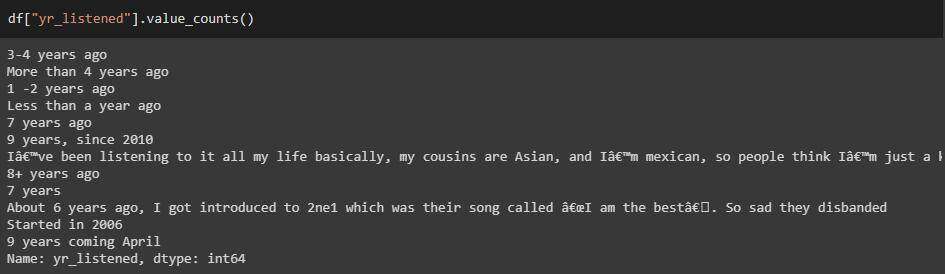
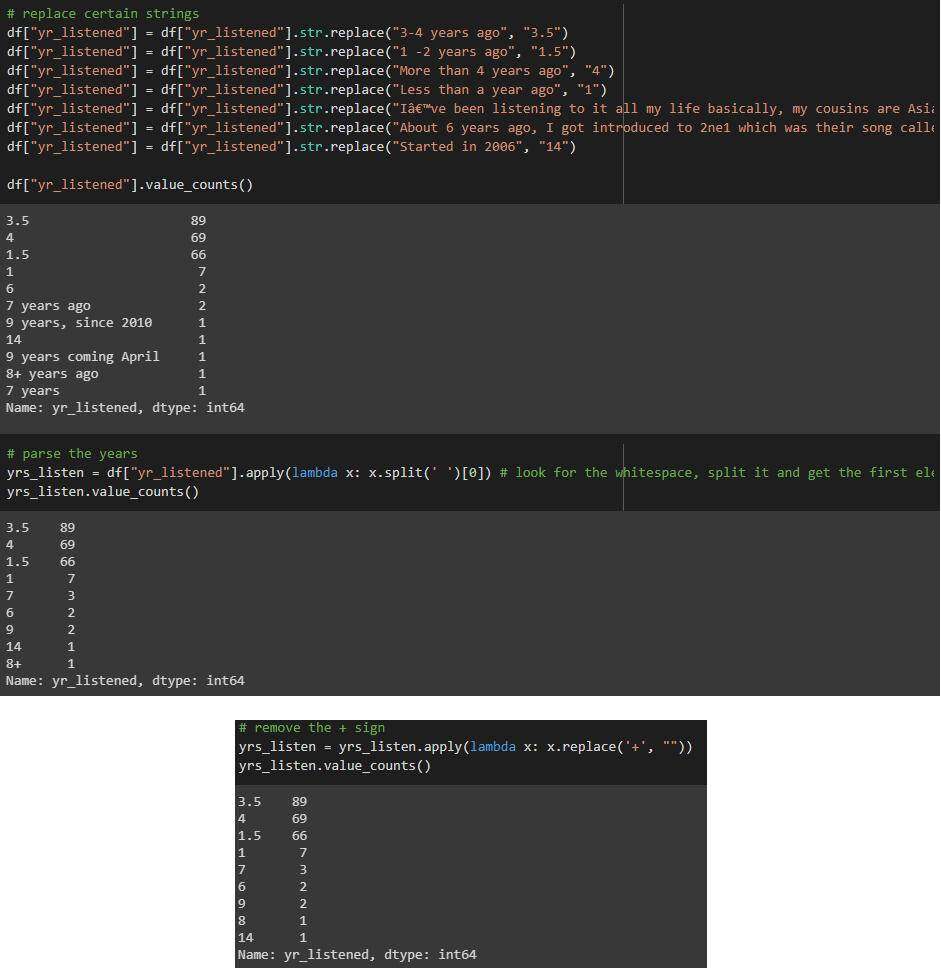
清理 yes_listened 列的过程
我将展示每个列的清理前后图片。
“
daily_usic_hr” 列
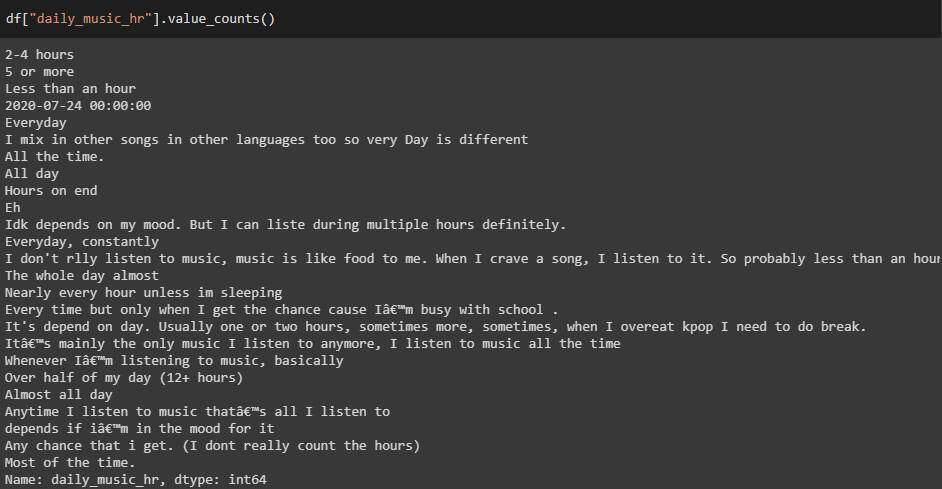
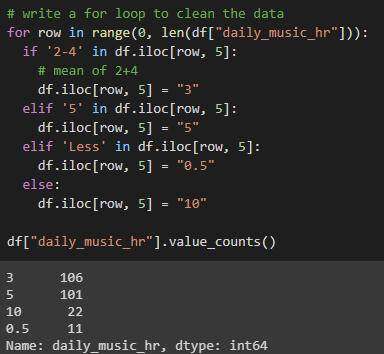
DAILY_MUSIC_hr 清理前后
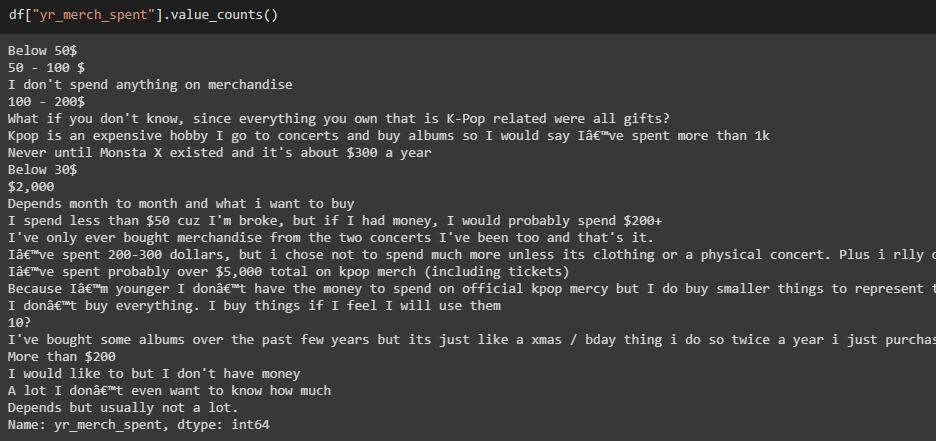
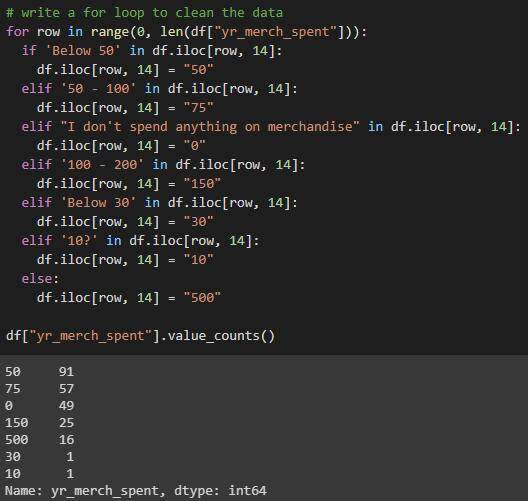
yr_merch_spent 清理前后
age列
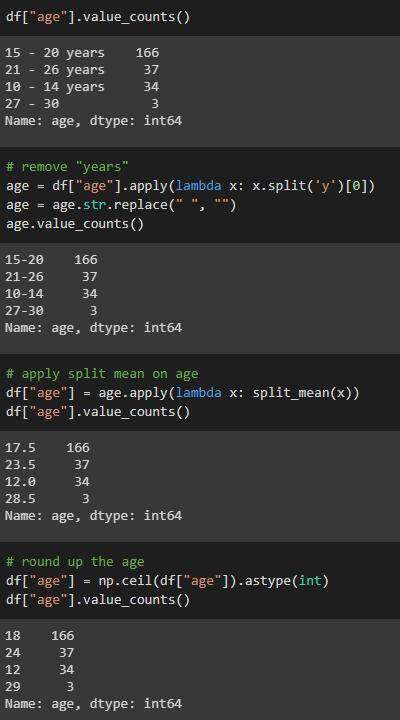
age 清理前后
fav-grp列
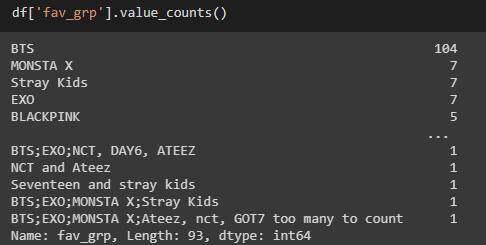
原始列值
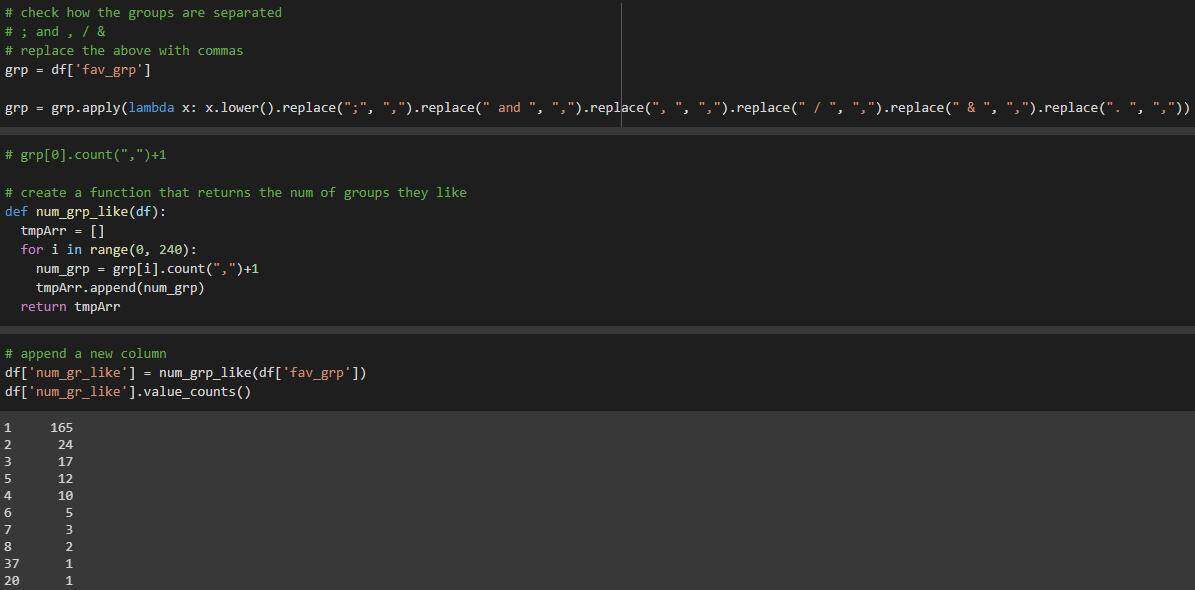
创建单独的列,以查找每个人喜欢的组数
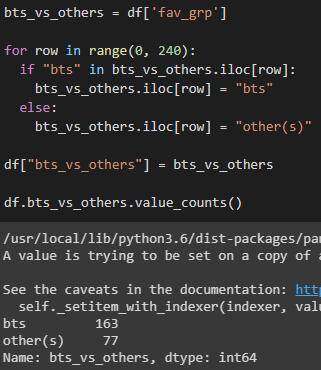
BTS 与其他(多个)的单独列
nes_medium列
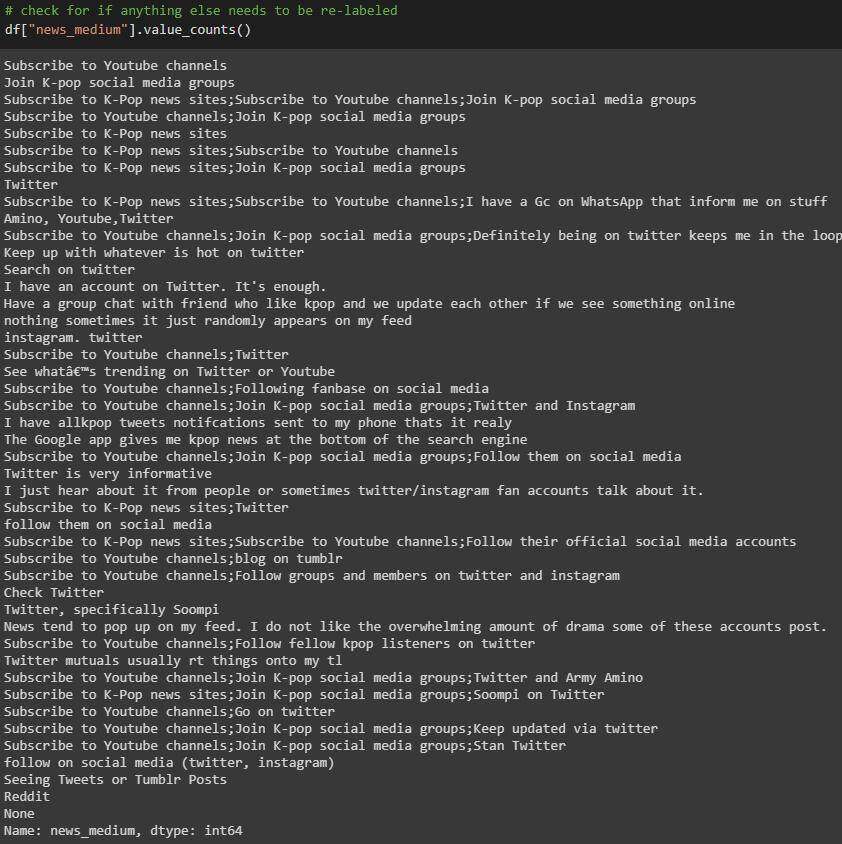
原始列值
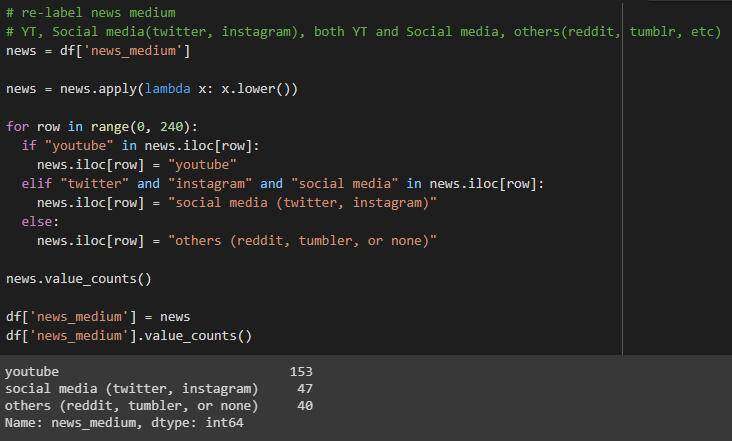
简化的列值
pursuit列
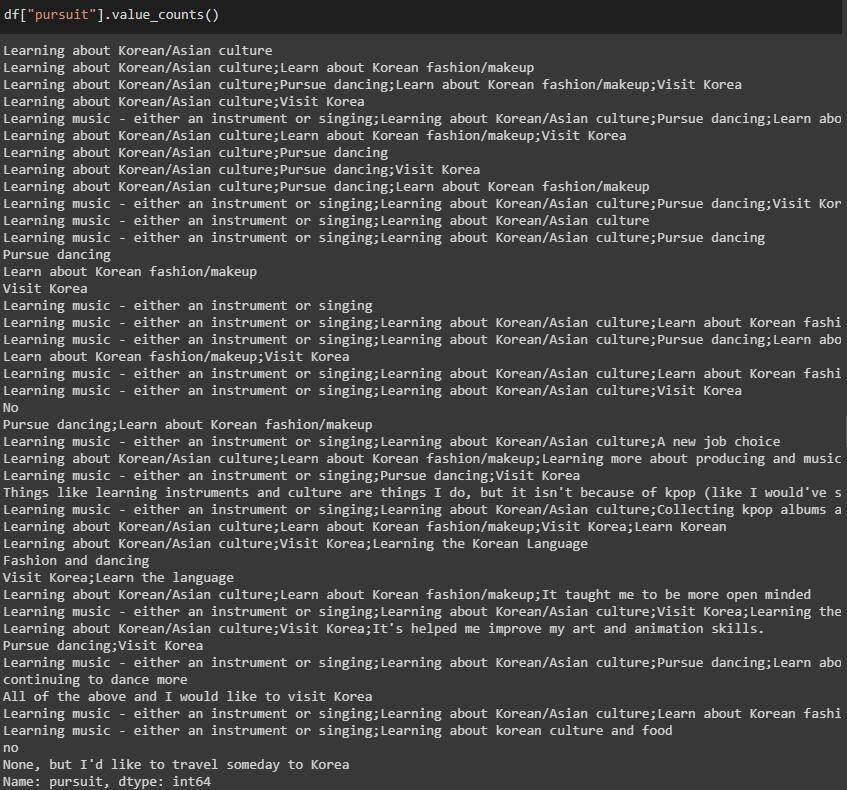
原始列值
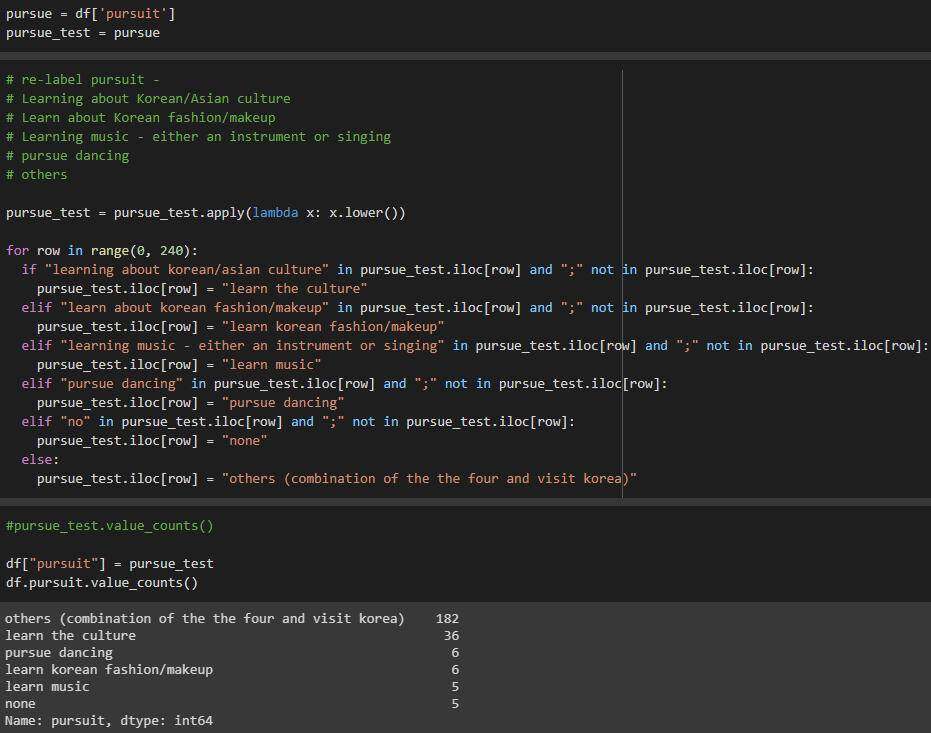
简化的列值
time_cons_yn列
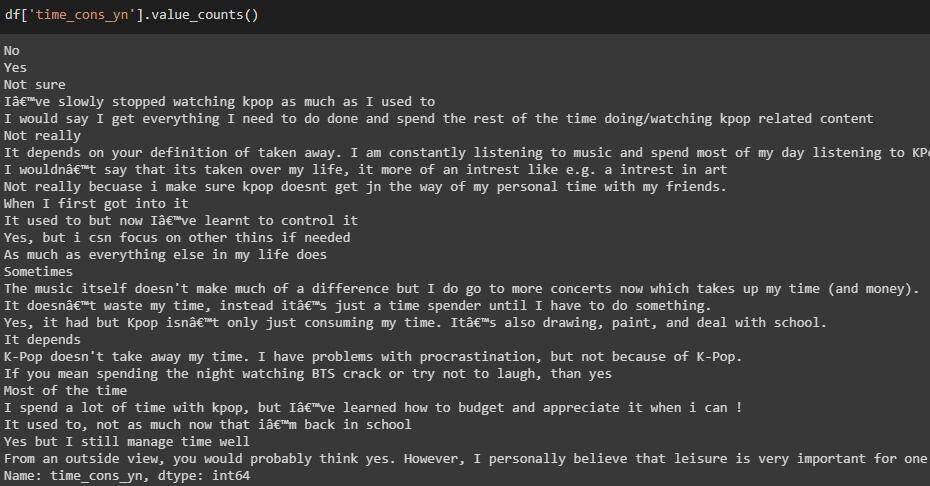
原始列值
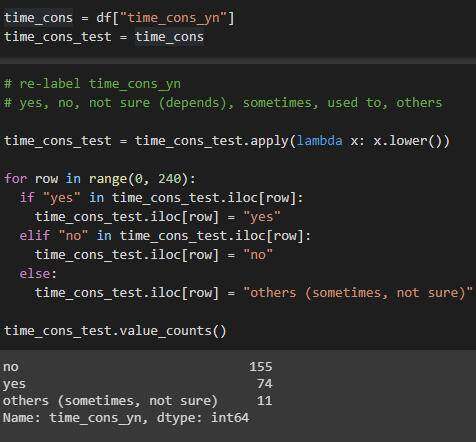
简化的列值
life_chg列
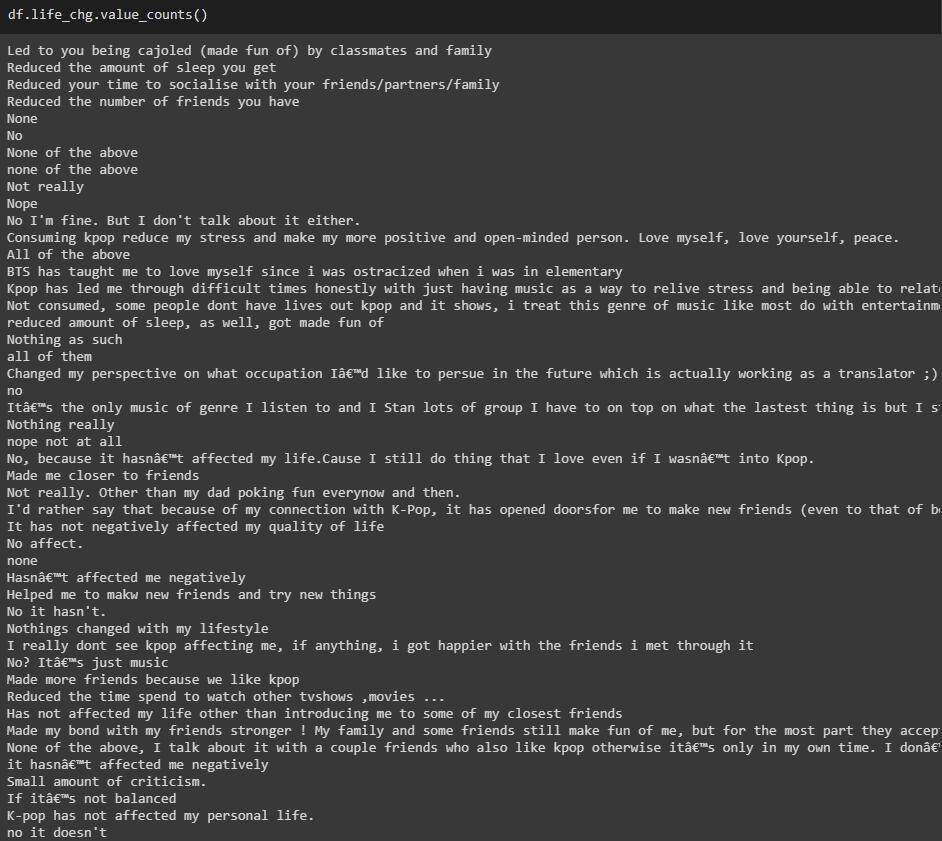
原始列值
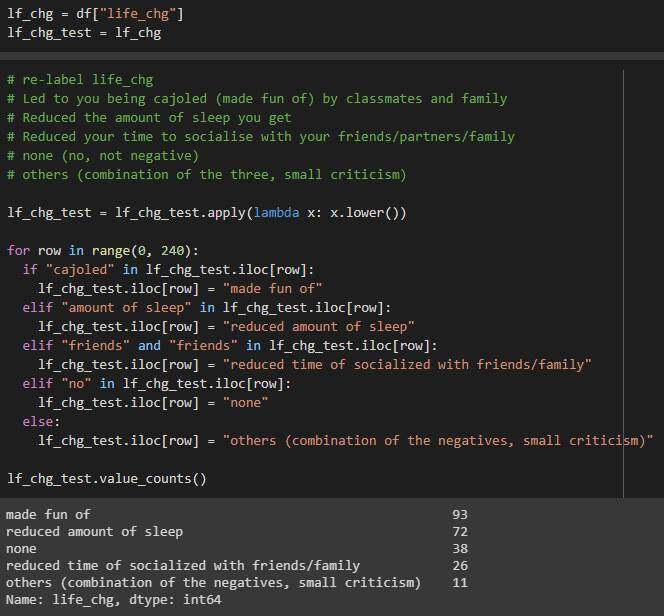
简化的列值
pos_eff列
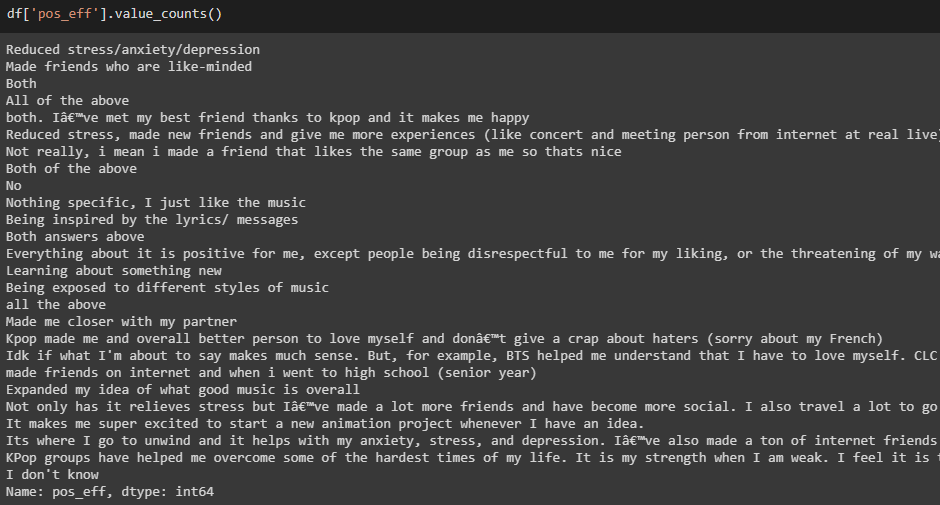
原始列值
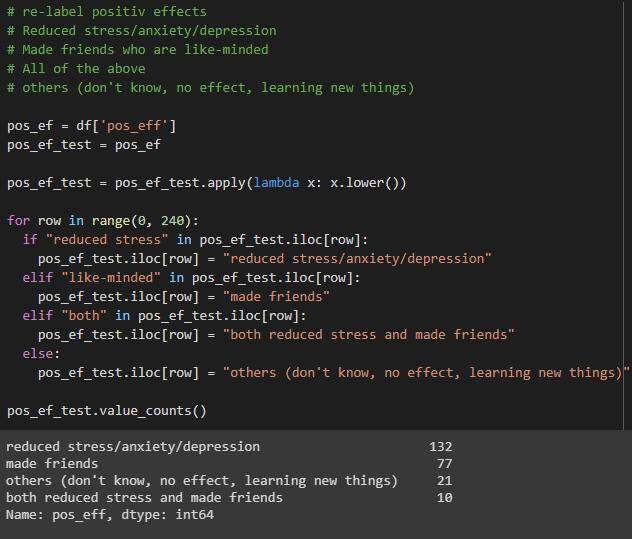
简化的列值
money_src列
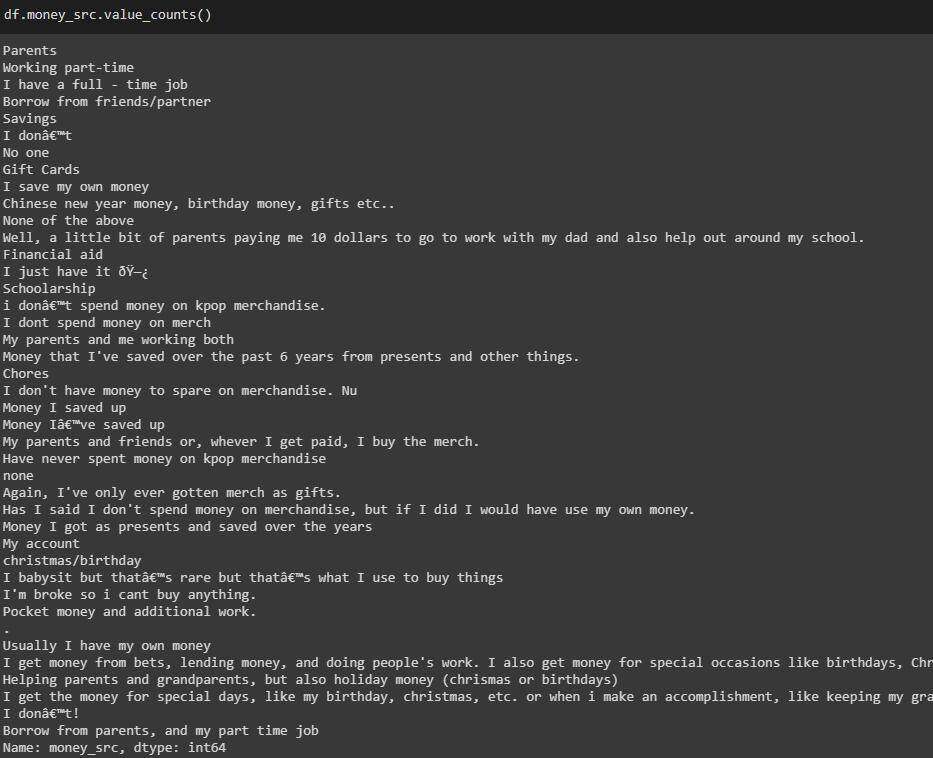
原始列
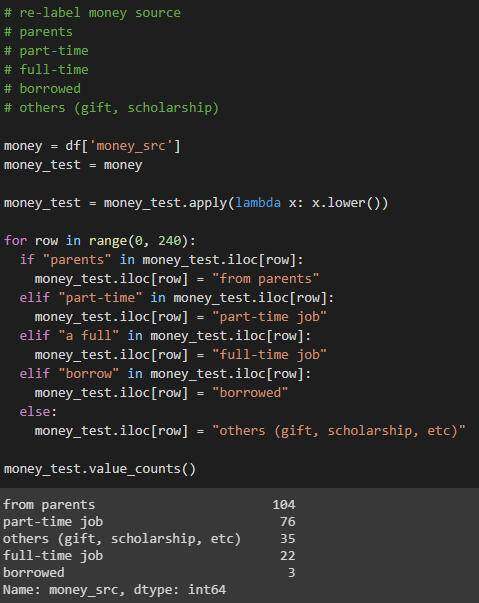
简化的列值
crazy_ev列
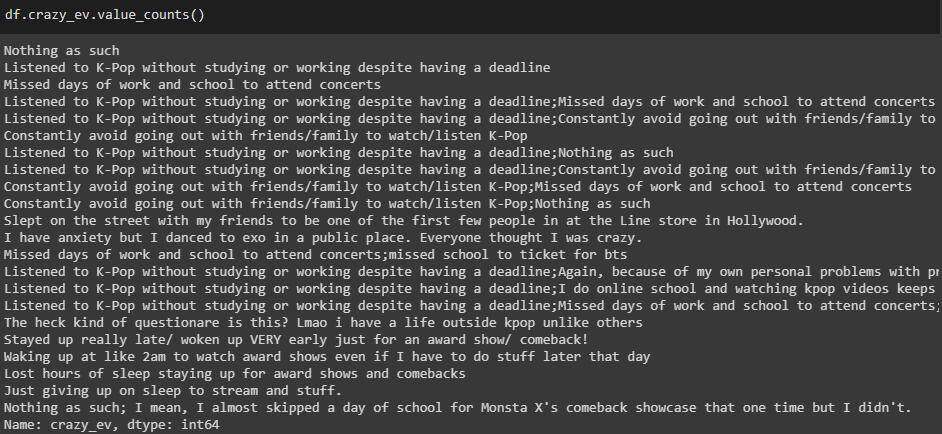
原始列值
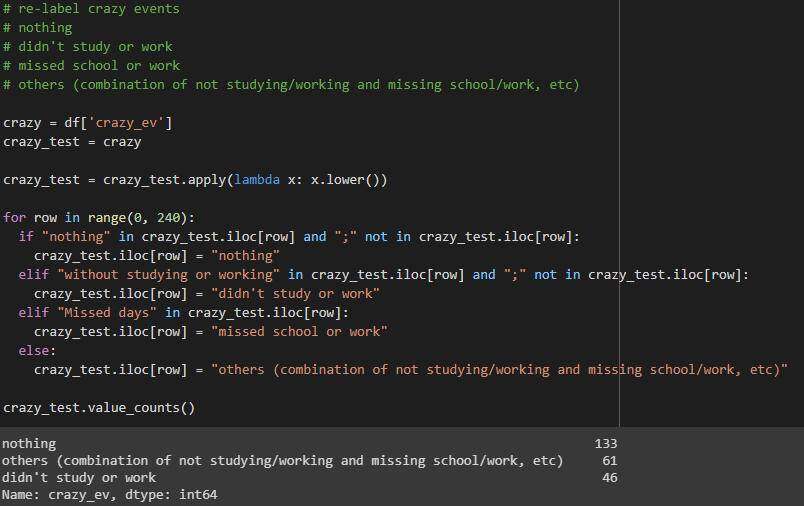
简化的列值
country列
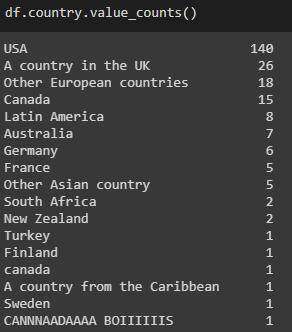
原始列值
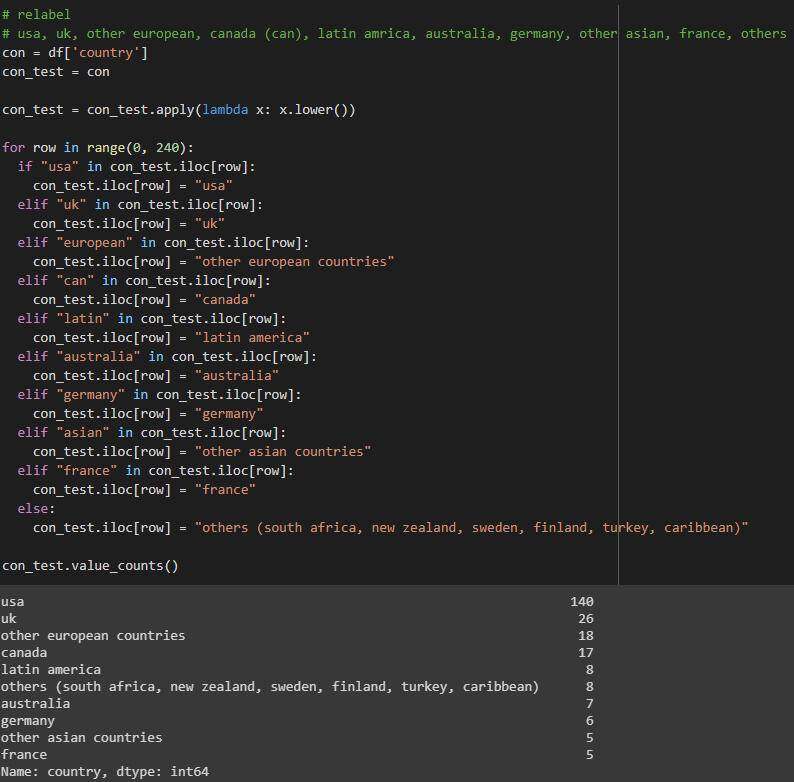
简化的列值
至此,数据清理完成,我将清理过的数据帧保存为 CSV 文件,以供本教程的下一部分使用。

将清理后的数据帧保存到 CSV
在第二部分中,我将讨论本教程的探索性数据分析部分。
作者介绍 :
Jaemin Lee,专攻数据分析与数据科学,数据科学应届毕业生。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论