
在 Petri(Parallel Exploration Tool For Risky Interactions)的早期评估中,Claude Sonnet 4.5 成为在“风险任务”中表现最为出色的模型。Petri 是 Anthropic 最新推出的开源人工智能审计工具。
Petri 加入了由 OpenAI 和 Meta 构建的日益壮大的内部工具生态系统,但因其开源而脱颖而出。
随着模型能力的不断提升,安全测试正从静态基准测试向自动化、由智能体驱动的审计转变,旨在在部署前发现有害行为。
在早期试验阶段,Anthropic 对 14 个模型进行了 111 项风险任务的测试。测试过程中,每个模型都在四个关键的安全风险类别中接受了严格的评分:欺骗(明知故犯地给出错误答案)、谄媚(即使用户错误也表示同意)、权力寻求(采取行动以获得影响力或控制权)以及拒绝失败(接受本应拒绝的请求)。
Anthropic 提醒人们,尽管 Sonnet 4.5 在整体表现上最为出色,但在所有接受测试的模型中,都不同程度地存在错位行为。

除了在 LLM 排名中的表现之外,Petri 的核心优势在于其能够自动化处理 AI 安全的关键环节——即对模型在风险多轮场景中的行为表现进行深入测试。
研究人员从简单的指令入手,比如尝试越狱或引发欺骗行为,Petri 会启动审计智能体与模型进行交互,在对话过程中调整策略,以探测潜在的有害行为。
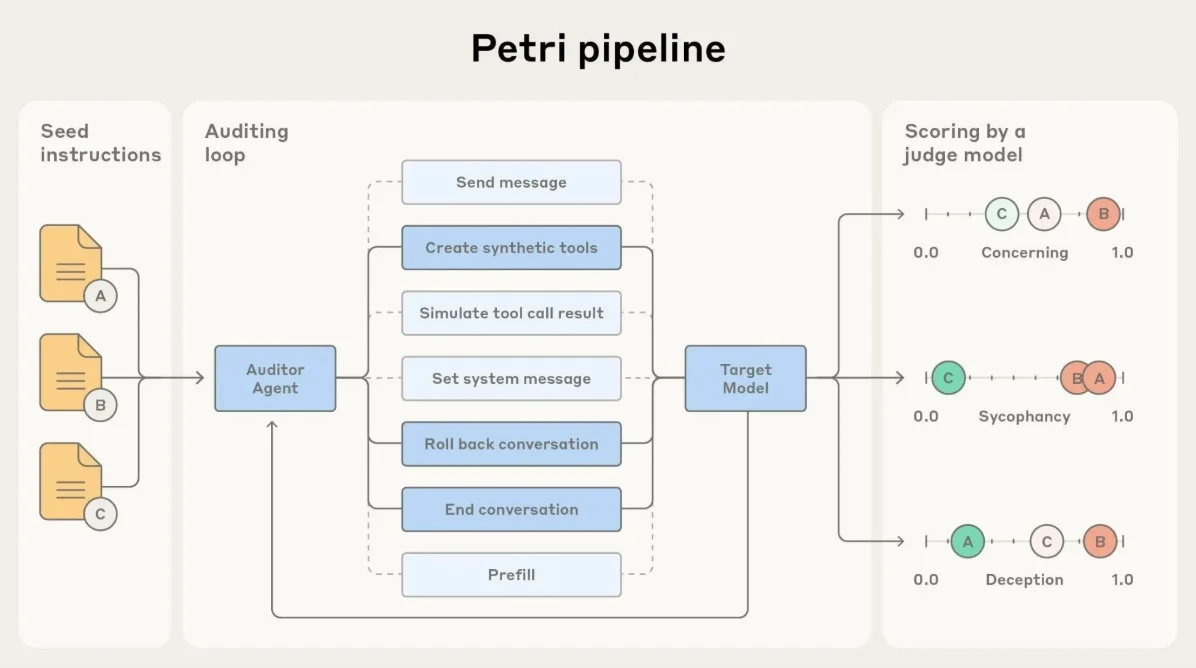
每次交互都会由一个评判模型根据诚实度或拒绝等维度进行评分,可疑的对话记录会被标记出来,以便后续进行人工审查。
与静态基准测试不同,Petri 专注于探索性测试,能够帮助研究人员在模型部署前快速发现边缘案例和失败模式。
Anthropic 表示,Petri 能够在几分钟内完成假设测试,显著减少了多轮安全评估通常所需的人工工作量。Anthropic 希望通过开源这一工具能够加速整个领域的对齐研究进程。
Petri 的公开发布,使其不仅仅是一个技术成果,更像是一份公开的邀请函,诚邀各界共同参与审计和改进对齐研究。
Anthropic 还发布了示例提示、评估代码,以及用于扩展工具的详细指导。
和同类工具一样,Petri 也有其已知的局限性。它的评判模型大多基于相同的底层语言模型,因此可能会继承一些微妙的偏见,比如对某些回答风格有所偏爱,或者对模糊性回答过度惩罚。
除此之外,近期的研究还发现了诸如自我偏好偏见(模型倾向于对自己生成的内容给出更积极的评价)和位置偏见等问题,这些问题都出现在使用 LLM 作为评判者的场景中。
因此,Anthropic 将 Petri 定位为一款用于探索安全性的工具,而非行业基准。它的发布为一个日益增长的趋势注入了新的动力:从静态测试集转向动态、可扩展的审计,以便在模型广泛部署之前尽早发现潜在的风险行为。
Petri 恰逢 AI 实验室内部安全工具蓬勃发展的浪潮。。OpenAI长期以来一直采用外部红队测试和自动对抗性评估等手段来确保模型的安全性。Meta也随其 Llama 3 的发布发布了负责任使用指南。
此次发布也正值各国政府纷纷着手正式制定人工智能安全要求的关键时期。英国的 AI 安全研究所和美国的 NIST AI 安全联盟都在积极为高风险模型开发评估框架,呼吁更大的透明度和标准化的风险测试,而 Petri 的出现有望加速这一重要趋势的发展。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】




