背景
随着云上规模持续扩张,AI 训练数据、实时日志、多媒体内容等数据类型呈指数级增长,推动云存储成为主流选择,同时也带来了 IO 请求量的急剧上升。在多租户云环境中,多个用户共享底层存储资源,高并发访问容易引发 IO 资源争抢,造成性能瓶颈。此外,混合云和多云架构的广泛应用,使得数据在不同云平台间频繁流动,而各异的存储策略和监控体系进一步增加了 IO 问题的排查与定位难度。为了进一步提升问题的解决效率,阿里云操作系统控制台聚焦高频的 IO 异常场景,构建了从问题发现,根因诊断到解决方案的 IO 一键诊断能力。
业务痛点解析
痛点 1:问题类型只是能力缺失
用户普遍缺乏对 IO 异常类型的识别能力(如区分 IO 延迟高还是打满问题),导致无法自主调用针对性诊断工具,必须依赖运维人员介入定位,导致诊断流程效率低下,增加了人力成本。一键诊断能够聚焦于 IO 延迟高、IO 流量异常、iowait 高等几类出现频次高的问题,捕捉 IO 子系统相关的异常,帮助用户快速自动地识别问题类型。
痛点 2:问题现场丢失与取证困难
目前传统监控普遍集成了 OS 的 IO 相关指标,如 await、util、tps、bps 等,同时会依赖指标的突变作为告警依据,但是当指标异常时可能已错过问题发生的窗口期,没法再去针对性地抓取更多帮助信息,获取关键诊断证据(如细粒度的必要辅助信息)。所以快速识别问题并采取相应的措施,是把握住最佳诊断时机的关键。
痛点 3:监控指标割裂与诊断关联弱
现有监控指标体系存在"数据孤岛"现象,各指标独立存在,并且与具体 IO 问题类型缺乏直观的映射关系。例如在 util 指标(硬盘设备的繁忙比率)偏高的时候,往往需关联观察 await 等多个指标,同时结合磁盘 iops、bps 的理论上限来综合判断问题。即使识别出了问题类型,也需要对相应诊断工具有使用方法相关的先验知识,考虑如何根据监控指标的数值来设置诊断参数,而 IO 一键诊断旨在能够屏蔽了这些复杂的关联流程,直抵分析报告。
解决方案
架构介绍
「阿里云操作系统控制台」提供的 SysOM 管控组件已具备应对 IO 延迟高,IO 流量异常,iowait 高等几类问题的诊断能力,但是客户往往不会允许在机器上常态化执行诊断工具去不停地抓取信息。因此,IO 一键诊断设计为在诊断时段内,周期性读取 IO 监控指标数据来检测异常,定界问题,到最后触发子诊断工具输出报告的模式,实现“发现问题->诊断问题->根因分析”的自闭环。
由于不同的业务场景,关注的指标阈值会不一样,如果统一一个静态阈值覆盖各种场景,很可能引起异常的误报或者漏报,因此 IO 一键诊断通过动态阈值来识别异常,总体架构图设计如下图所示:
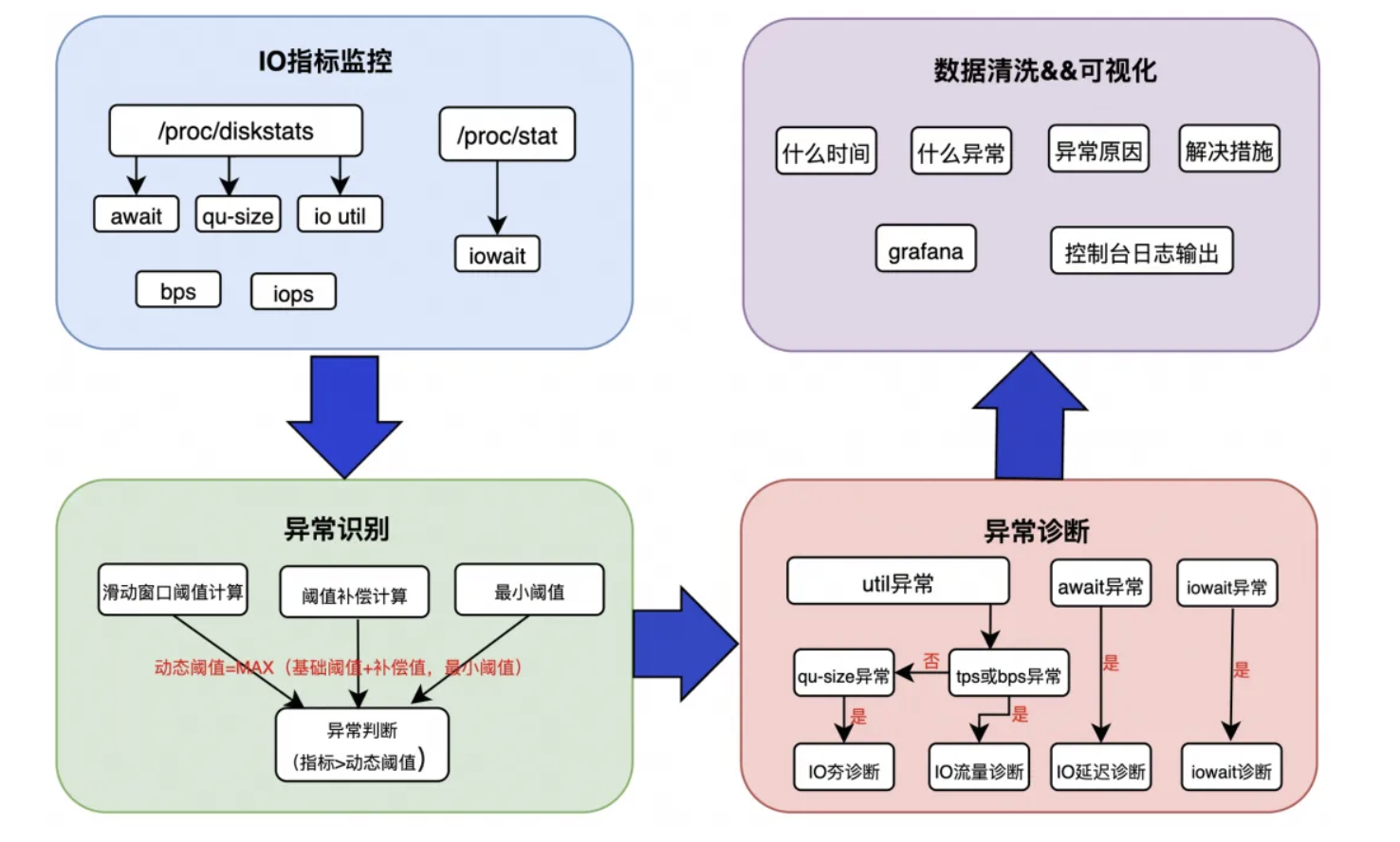
IO 指标监控:从系统获取 IO 的关键指标,例如 await、util、tps、iops、qu-size、iowait。
异常识别:当采集到的 IO 指标大于动态阈值时,判定为异常,因此异常识别的核心在于动态阈值的计算,具体算法将在下文解释。
异常诊断:根据不同的指标异常,触发对应的诊断工具,并且会对触发频率做了一定的限制。
数据清洗 &可视化:根据诊断结果呈现出可视化的输出,给出根因和解决建议。
实现原理
指标采集
触发一键诊断后,每间隔 cycle 毫秒(数值可配置)会读取并计算 iowait、iops、bps、qusize、await、util 等指标的值,并检查是否有异常。
动态阈值计算
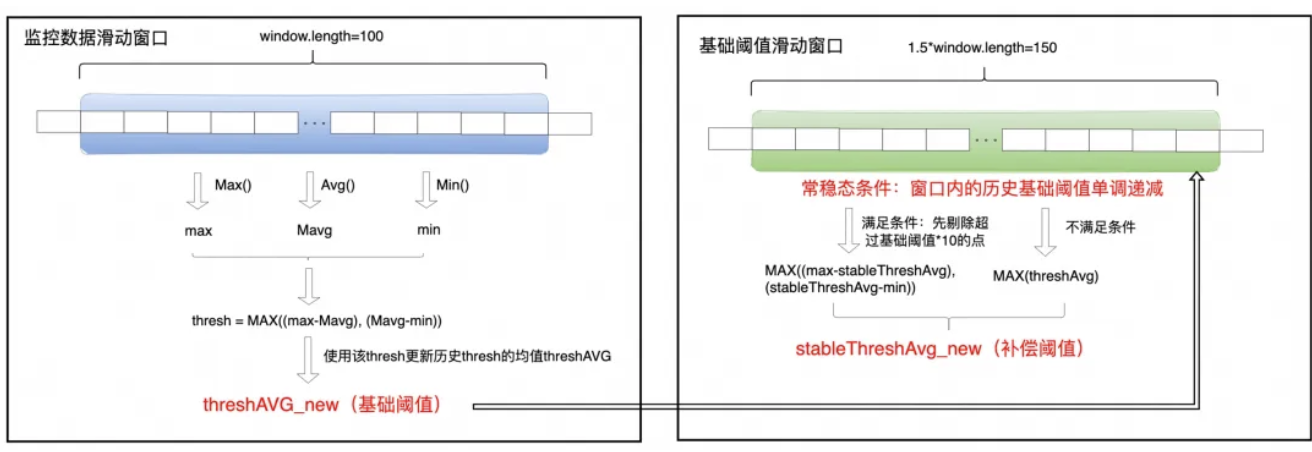
为了能够识别秒级的 IO 异常行为,需要将系统中采集到的各个孤立的 IO 指标聚合起来,形成对 IO Burst 等问题的监控能力,这个过程的核心在于动态阈值的计算,动态阈值经过三步计算得到:基础阈值计算,补偿阈值计算以及最小阈值计算。
基础阈值计算
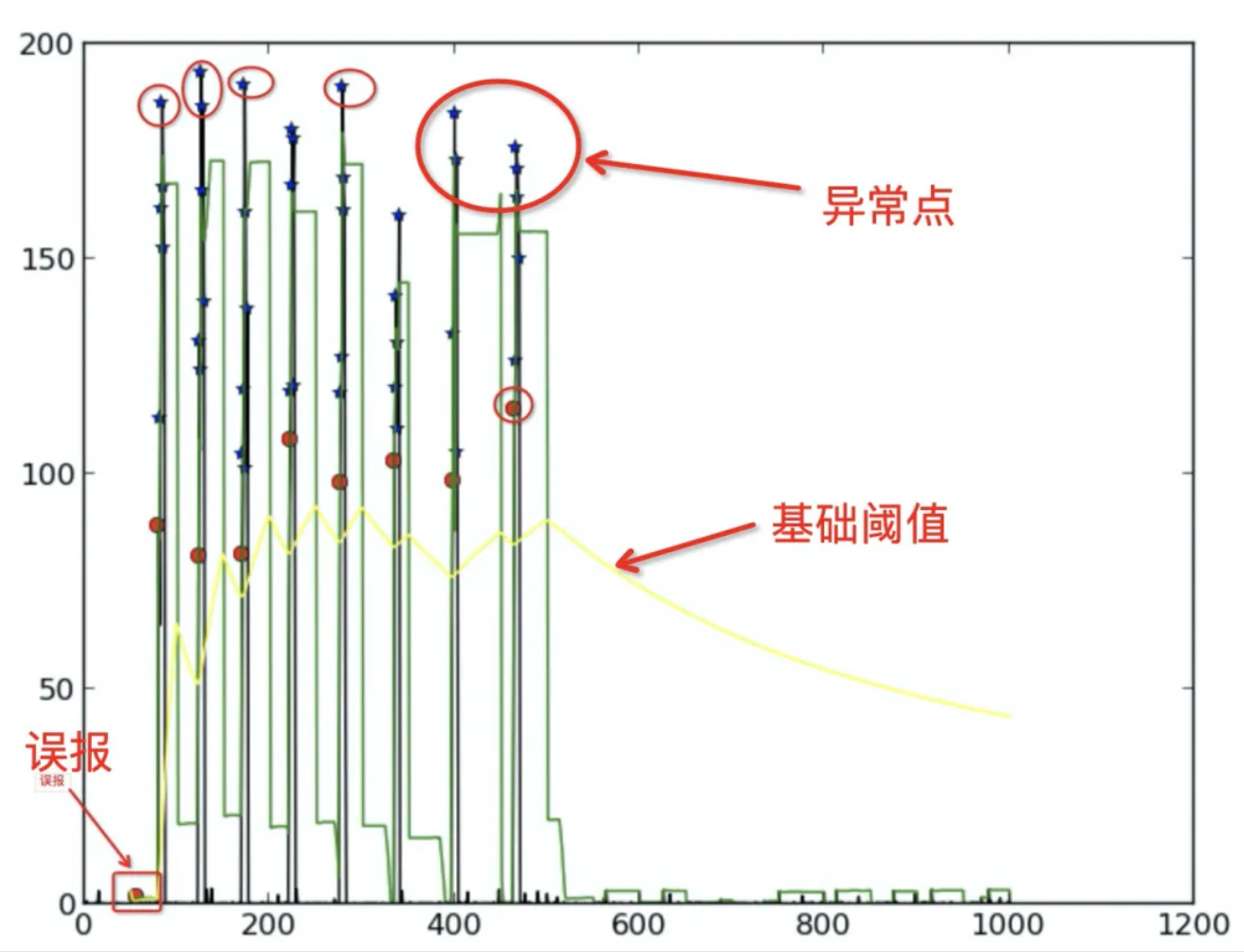
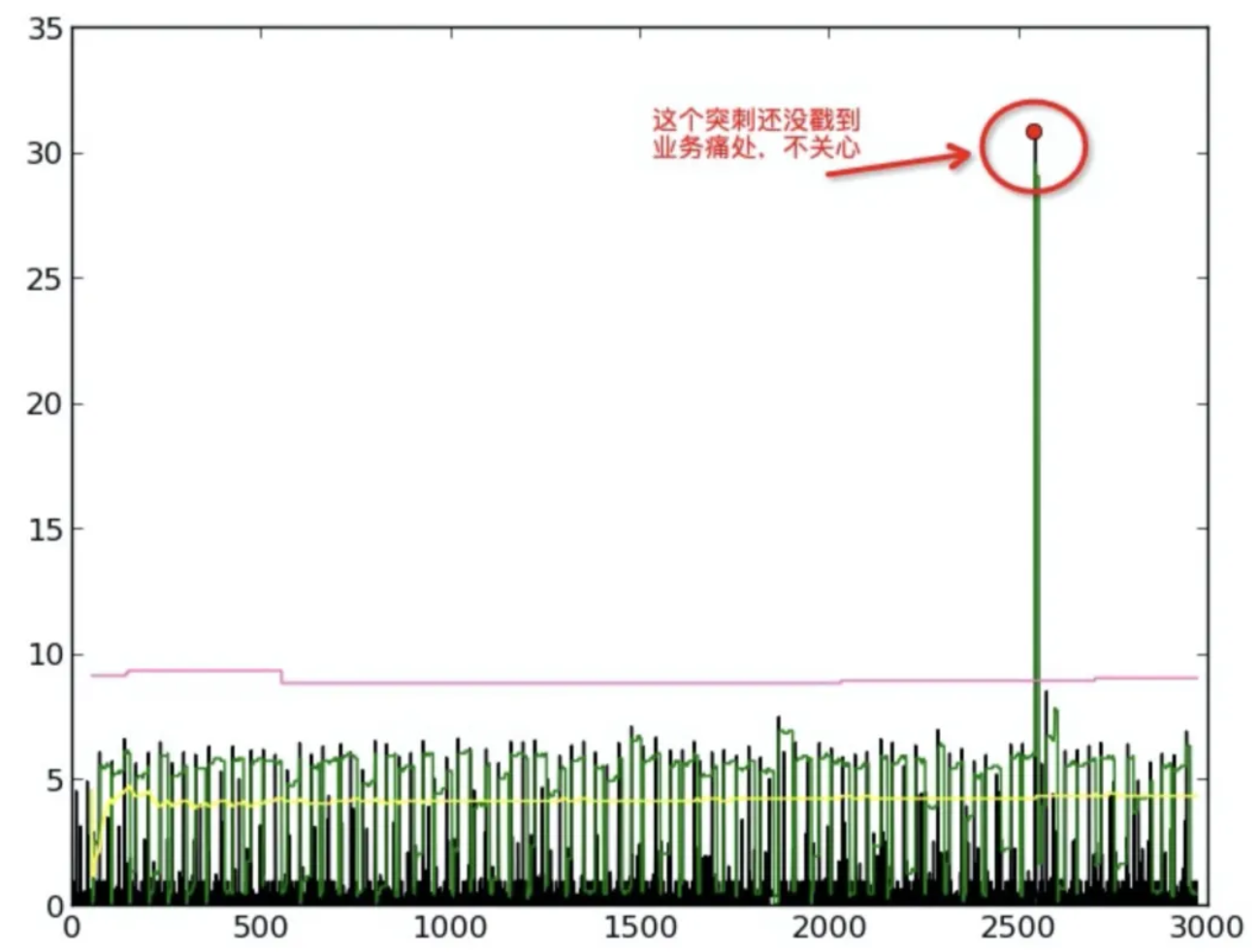
IO 指标其实是一种时间序列,而且一般地,在一个时间区间内,可以认为绝大部分时间是没有异常的,因此序列形成的曲线趋势是趋于平稳的,当出现异常的时候,会产生一个明显偏离平稳趋势的尖峰,因此第一步要做的就是通过本节计算得到的基础阈值把 IO 指标中的尖峰毛刺筛选出来。
我们通过动态窗口持续观察数据,计算窗口内数据的最大偏离平均值作为“瞬时波动值”。然后,将所有“瞬时波动值”的平均值作为“基础阈值”。这个阈值会持续自适应地更新,以反映数据最新的波动特征。
补偿阈值计算
基础阈值曲线(如下图中的黄色曲线)反映的是真实 IO 指标数据的波动情况,但是 IO 指标在平稳状态下往往是限于一个范围内波动,所以需要计算一个补偿阈值,叠加到基础阈值上会减缓基础阈值的快速下降,而从而减少带来误报的情况。

当基础阈值持续下降一段时间后,可以认为系统进入“常态稳定”模式。此时,我们会过滤掉明显的噪音数据,并在剩余的“安静”数据中,计算一个“常稳态补偿值”来衡量这种稳定状态下的微小波动。在“常稳态补偿值”正式计算出来之前,我们会临时用当前窗口最大的基础阈值作为补偿值,并且在每个新窗口开始时都重置。一旦基础阈值停止下降或反弹,该机制将重置,回归更宏观的观察模式。
最小阈值
最小静态阈值是一个预先设定好的最低门槛,。最终的异常判定阈值为 “最小静态阈值” 和 “动态调整阈值(基础阈值 + 补偿值)” 两者中的最大值,确保只有同时超过业务容忍底线和系统动态波动范围的数据才被视为异常。
特别地,如果数据已超出“最小静态阈值”,则“动态调整阈值”的计算会简化,不再考虑“常态补偿值”,直接使用“基础阈值”作为判断依据,以聚焦更明显的异常情况。
异常识别
当采集到的 IO 指标大于动态阈值时判定为异常。不同异常类型虽有各自的判断算法,但都遵循以下原则:
确定警戒线: 设定一个“指标警戒线”,取 “最小静态阈值”(业务容忍的最低门槛)与“动态阈值”(系统根据历史数据计算的正常波动范围)中的最大值。
触发诊断: 若当前指标值超过此“警戒线”,且监测和诊断条件满足,则立即启动诊断。
动态学习: 系统会持续根据最新的指标数据,更新并调整“动态阈值”,使其始终反映指标的正常波动范围。
智能诊断
当系统监测到 IO 异常时,一键诊断工具能够自动调用诊断功能,及时抓取和分析关键信息,快速定位问题。为避免诊断过于频繁,我们通过以下参数进行频率控制:
“诊断冷静期”(
triggerInterval): 设定两次诊断之间的最短间隔,确保系统不会在短时间内重复诊断。“异常堆积计数器”(
reportInterval): 控制诊断发起的条件。若为 0,则异常发生且过了冷静期即可诊断;若不为 0,则需在冷静期过后,且在规定时间内积累了足够数量的异常事件,才触发诊断。
根因分析
在诊断工具抓取了信息之后,面对各种信息,从何处着手,也令人困扰,因此瞄准方向,进行专业的分析、剥丝抽茧地从中筛查跟问题相关的线索显得非常重要;IO 一键诊断则具备这个抽丝剥茧的分析能力,并且能够汇报跟问题相关的结论性信息:
对于 IO Burst 异常,经过分析后,在监控的日志栏中汇报异常期间贡献 IO 最多的进程,其中极具特色的是,对于写 buffer io 后由 kworker 刷脏的情况,也能分析出来是哪个进程在写 buffer io。
对于 IO 高延迟异常,经过分析后,在监控的日志栏中汇报异常期间 IO 的延迟分布,输出 IO 延迟最大的路径。
对于 iowait 高异常,经过分析后,在监控的日志栏中汇报触发 iowait 高的进程、以及触发原因。
案例分析
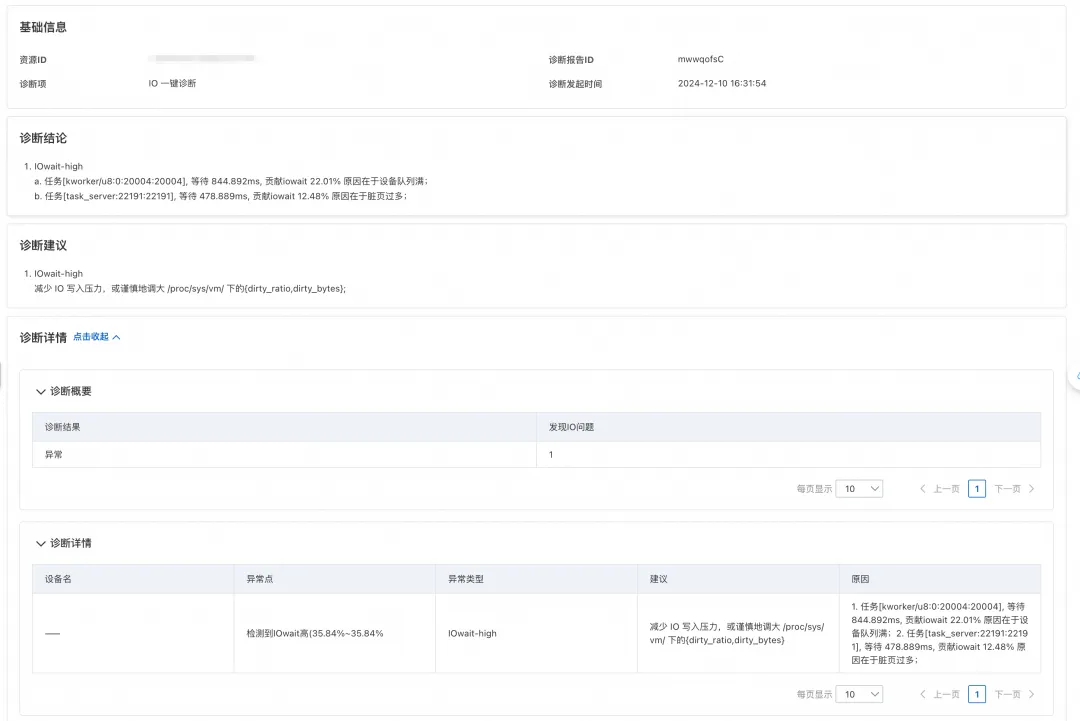
iowait 高
对于 iowait 高异常场景,IO 一键诊断可以直接定位到等待磁盘 IO 的进程来源以及等待时长,分析阻塞的原因。以下案例即是诊断出业务场景 IO 压力过大,脏页过多过多,导致业务进程 task_server 等待 IO 时长过长的问题。对此场景,报告中也提出谨慎地调整 dirty_ratio 和 dirty_bytes 参数,来减少刷脏压力,从而缓解 IO 压力的建议。
IO 延迟高
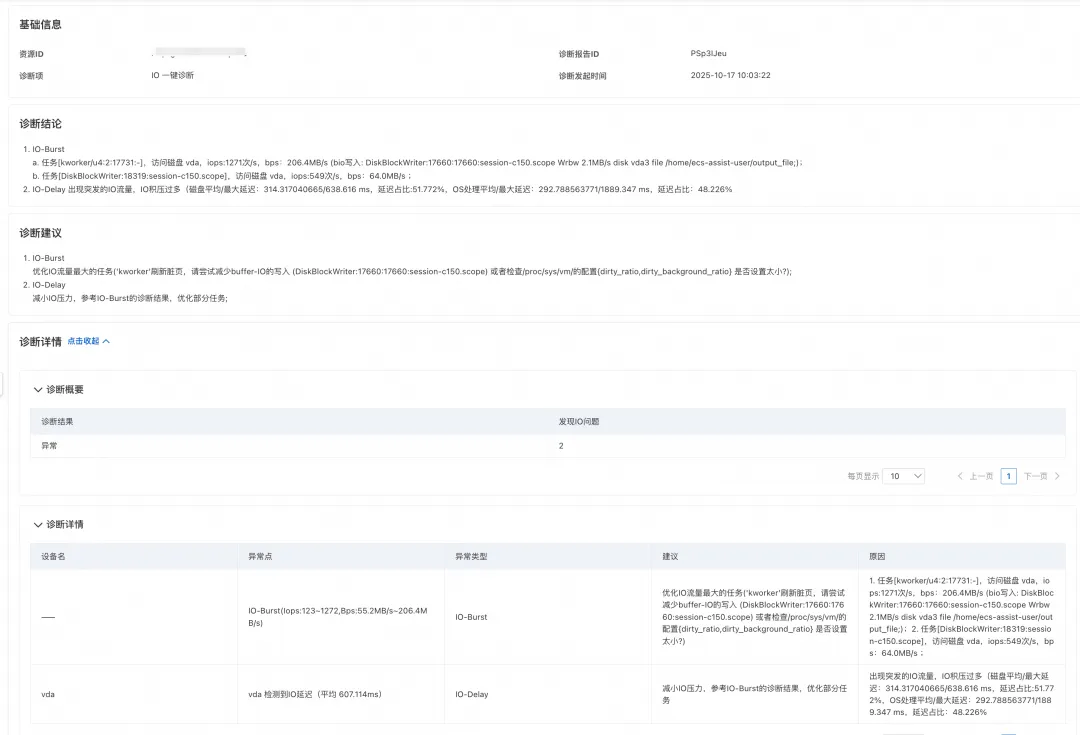
用户通过监控发现机器上 IO 写流量出现了延迟比较高的现象,我们建议他尝试通过 IO 一键诊断来判断根因。
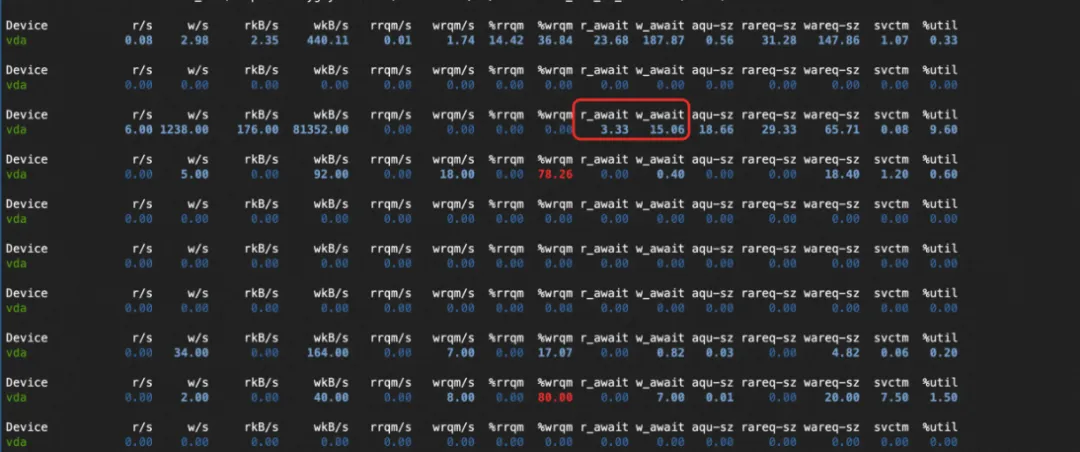
在用户执行的结果中,诊断识别到了是 DiskBlockWrite 进程产生的 IO 压力,主要延迟集中在磁盘刷脏,帮助用户查到了延迟根因。对此,我们在结果中建议用户尝试减少 buffer IO 的写入或者调整机器上的配置的 dirty_ratio 和 dirty_background_ratio 参数数值,来缓解 IO 延迟高的问题。