
上个月,我们发布了适用于 Apache Spark™的 Snowpark Connect 引擎,目前该功能已进入公开预览阶段。在本文中,我们将超越新闻稿的范畴,深入剖析该功能背后的技术实现细节,探讨开发过程中遵循的最佳实践以及遇到的挑战。
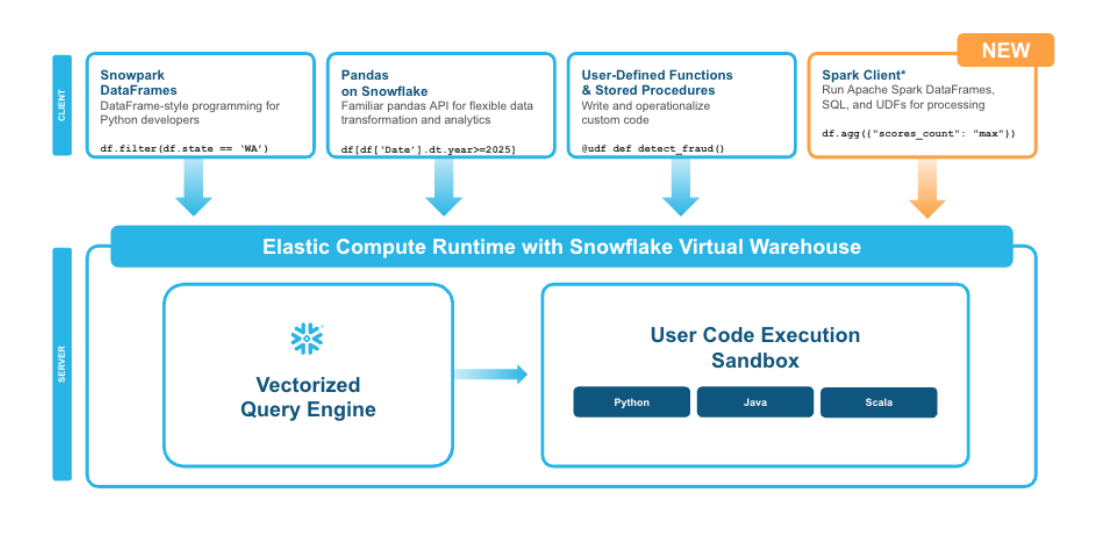
作为添加到 Snowpark 的最新功能,Snowpark Connect 通过支持 Spark 代码在 Snowflake 上运行(无需托管 Spark 引擎!),为开发者带来了更丰富的使用体验,同时也为 Snowpark DataFrames 提供了一种替代方案。为充分利用 Snowflake SQL、人工智能(AI)、pandas 等平台专属集成能力,Snowpark 持续为开发者提供一套易于使用的工具。
Spark Connect 是什么?
Spark Connect 是 Apache Spark™ 3.4 版本中引入的一种客户端 - 服务器架构,它实现了客户端接口与 Spark 执行引擎的解耦。该架构允许远程客户端通过基于 gRPC 的协议连接到 Spark 集群,使开发者能够从多种语言和环境(如 Web 应用、集成开发环境(IDEs)、笔记本电脑)与 Spark 进行交互,且无需在客户端安装完整的 Spark 或 Java 虚拟机(JVM)。
它是如何工作的?
Spark Connect 的核心是通过将逻辑计划从客户端发送到服务器来运行的。然后,服务器执行这些计划后返回结果。这一过程通过 gRPC(远程过程调用框架)和协议缓冲区(protocol buffers,简称 protobufs)实现。
消息结构是怎样的?
Spark Connect 消息使用 protobuf 模式定义。这些模式在 Spark 源代码中指定,描述了客户端与服务器之间交互的逻辑计划、表达式及结果的结构。这种标准化的消息格式确保了不同客户端与服务器实现之间的互操作性例如,以下是一段 Spark 代码:

与 Apache Spark 的经典模式类似,Spark Connect 会继续构建底层查询计划,直到触发执行(比如通过 persist、collect、show 等方法)。当执行上述代码中的 show 命令时,扩展了开源 Spark(OSS Spark)中 SparkConnectServiceServicer(具体可看源码)的 gRPC 服务器,会接收到如下的 ExecutePlanRequest(具体可看源码):


在顶层结构中,我们有 session_id、user_context、plan、client_type、request_options 和 operation_id 这几个字段。其中,plan 字段存储的是在客户端生成的 Spark 查询计划。请注意,该结构呈嵌套形式,类似树状结构。
构建 “Hello World” 示例
下面我们将通过一个简单的 “Hello World” 示例,详细说明其工作流程。该示例基于 Snowpark 开发,适用于高性能关系型 OLAP(联机分析处理)工作负载,将使用针对 Snowflake 矢量化计算优化的 Snowpark Python 客户端,以 Python 语言实现 gRPC 服务器。
构建 Python gRPC 服务器以接受 Spark Connect 请求
道理很简单:要接收 gRPC 请求,第一件事得先有个 gRPC 服务器。服务器的实现过程相当直接:第一步,我们需自己写一个 Servicer 类(服务处理器类),该类需继承自 SparkConnectServiceServicer(源码参考);第二步,创建 gRPC 服务器实例,并将刚才写的 Servicer 类添加到该服务器上:
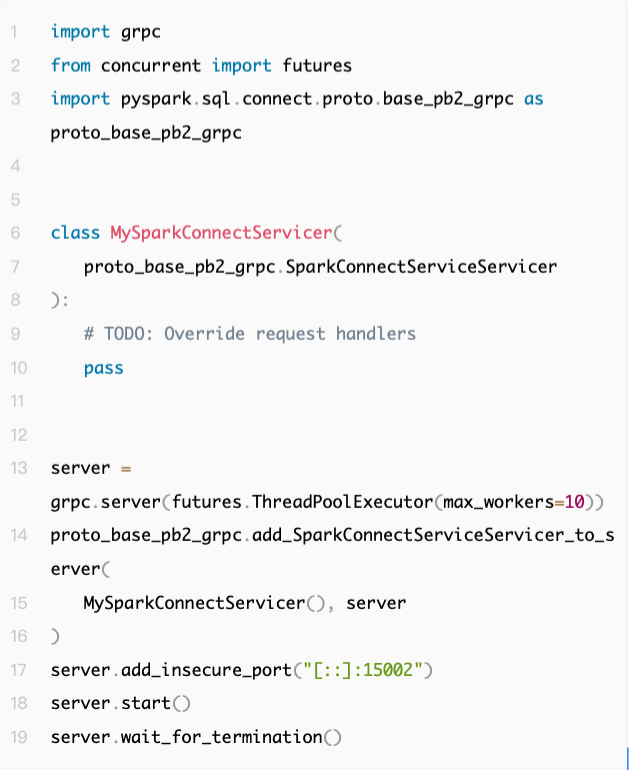
您可以自行运行上述代码,并从另一个 Python 脚本或交互式解释器(repl)中,通过本地主机(localhost)连接到该服务器:

由于我们尚未实现任何请求处理器,因此每一次请求都会返回如下格式的错误信息:

Hello World:让 Spark 代码按预期运行
本产品开发的核心原则之一,是兼容 Spark 的行为特性。Snowpark 客户端与 Snowflake SQL 保持一致,因此在迁移过程中,Snowflake SQL 与 Spark 行为特性之间的任何差异,都可能引发细微但影响体验的问题。我们决定选择一个相对简单的工作负载,该工作负载从 Spark 迁移到 Snowpark 时只需进行少量代码修改。最终确定的工作负载如下:

此工作负载包含:
在客户端创建一个列名为小写的 DataFrame(数据框)
打印 DataFrame 中的内容 l 执行分组操作(通过 df.count 方法)
使用点运算符(如 dr.id)和字符串(如 "age")进行列投影 l 对投影后的列执行简单运算
基于简单运算的结果创建新列
从 S3 读取 Parquet 文件
为使本篇博客文章篇幅保持在易于阅读的范围内,我们将重点讲解前两个操作:createDataFrame 和 show。其余代码可在您自行构建 Spark Connect 版“Hello World” 执行时使用。
createDataFrame 是如何在 Spark Connect 中工作的?
您可能还记得,在触发执行之前,不会向服务器发送任何查询。由于 show 方法会触发执行,因此 createDataFrame 操作会与 show 操作同时被服务器接收。createDataFrame 以 Relation protobuf(源码参考)中的 local_relation 字段的形式传输。包含该 Relation protobuf 的 relation 字段,包含在我们 ExecutePlan 中接收到的 ExecutePlannRequest 的 request.plan.root 字段中(从技术上讲,它位于另一个 Relation 的 input 字段中)。

这里包含两个字段:data 和 schemadata 字段呈现为一串字节,若查阅 Spark 源代码,我们就能找到关于如何反序列化这些字节的提示:


既然我们已将数据存入 pyarrow 表中,就可以通过 Snowpark 轻松将其移入 Snowflake,但还有一个 schema 字段需要处理。在我们的例子中,schema 是一个 JSON 字符串。我们可以使用 json.loads 将其转换为嵌套字典,然后通过将此处在其字符串名称(例如“long”)中定义的各个类型映射到 Snowpark 等效项来构建我们自己的 Snowpark 模式。类型转换的逻辑在此省略,因为多数情况下它都很简单(不是全部情况!):

有了 pyarrow 表和 schema,我们就能轻松创建一个 Snowpark DataFrame:

创建好 snowpark_df 后,我们就可以着手处理 Hello World 示例中 df.show() 这部分内容了。
Show 如何在 Spark Connect 中工作?
Spark 客户端上的 df.show()通过 Spark Connect 以 show_string 关系对象的形式传输(源码参考)。在服务器端,show_string 关系的结构如下:

这部分逻辑相当直观,接下来我们看看 Spark Connect 客户端期望数据以何种形式返回。在 pyspark.sql.connect.DataFrame 类中,我们在 show(源码参考)调用的_show_string 中看到以下代码:

其中_to_table 返回一个 pyarrow.Table 对象。因此,基本上,我们需要将想要显示的字符串从 1x1 pyarrow.Table 序列化为 Arrow IPC 流。这是一种非常优雅的 show 处理方式,因为它重用了已经用于其他操作(例如 collect)的基于 Arrow 的传输机制,这也让服务器能够完全控制字符串格式。为了简单起见,我们可以使用 Snowpark 的内部_show_string 方法来生成我们想要返回的字符串(注:此方法不适用于外部使用)。然后,我们可以创建所需的 1x1 pyarrow.Table,结果如下:

现在,通过从 Servicer 对象的 ExecutePlan 方法返回一个 ExecutePlannResponse,结果就可以从服务器传回了:
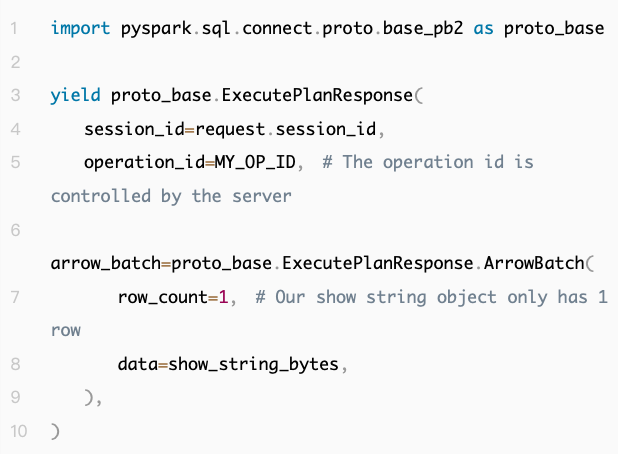
此时,我们的 ExecutePlan 方法看起来像这样


显然,这并非生产环境中的理想实现方式,但对于 “Hello World” 示例而言,这种方式是可行的。如果你要自己构建它,你需要能够解析整个 Spark 查询计划树,并将操作映射到目标系统中。
适用于 Apache Spark 的 Snowpark Connect 架构
既然我们已经了解了 “Hello World” 示例的实现方式,接下来让我们更详细地探讨适用于 Apache Spark 的 Snowpark Connect 架构。图 2 显示了该架构的概述。
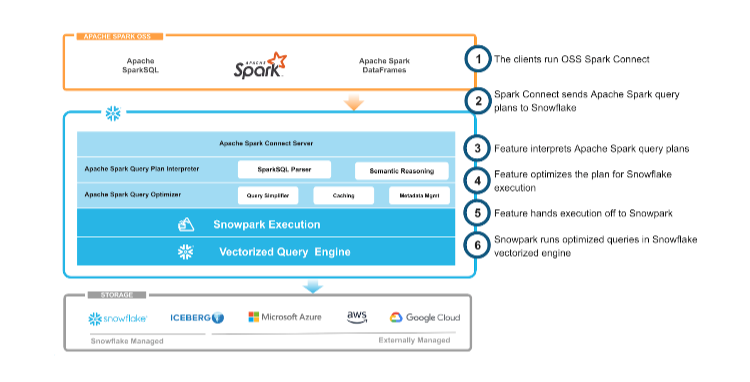
图 2:Snowpark 最初的构建理念与 Snowpark Connect 一致,均基于客户端 - 服务器分离的前提。在此架构视图中,您可以看到:通过与 Spark Connect 结合,我们能够以无缝透明的方式,将 Snowflake 平台的易用性、性能优势及可靠性,赋能于 Spark 工作负载。
如前所述,Spark Connect 使我们能够在 Snowflake 中内置一个服务器,这样一来,用户只要在自己安装的开源 Spark 环境里,直接连接到 Snowflake 的 Spark Connect 服务端点就行。具体怎么操作,入门文档里写得很清楚。
当 Snowflake 通过 Spark Connect 收到 Spark 的查询计划后,会对这个计划做一连串转换,最终生成一个经过最优的 Snowpark 查询计划。
SparkSQL 解析器
我们遇到的一个特别有意思的难题,是怎么把 SparkSQL 转换成 Snowflake SQL。至于 SparkSQL 解析器的具体细节,我们之后会专门写文章讲。简单说,我们的做法是:先用 SparkSQL 自带的 Catalyst 解析器处理 SQL,再把处理后得到的 “Catalyst 计划” 转成 Spark Connect 能用的 protobuf 格式。这种方式确保了每个所需算子只需要写一套实现代码,但过程中也碰到了不少新问题。
另外,SparkSQL 比 Spark 的 DataFrame API 功能更灵活,比如有些 SQL 里能用的算子,在 protobuf 定义里根本没提到。不过还好,Spark 开发者早就想到可能需要扩展协议,所以对于那些 “SparkSQL 里有但 protobuf 没定义” 的算子,我们可以给 Relation 对象用 Spark Connect 的 “扩展 protobuf” 来处理。更方便的是,所有解析工作都在服务器端完成,用户那边连新客户端都不用装,直接就能用!
park 查询计划解释器
这个组件花了我们最多的开发时间。因为 Snowpark 客户端和 Apache Spark 之间,藏着不少细节差异。比如 Snowpark 客户端得跟 Snowflake 的逻辑保持一致,所以哪怕是列名默认大写还是小写这种小事,设计的时候都得仔细考虑,不能马虎。
测试
一开始我们就面临一个关键问题:怎么测试。我们先想到用 Apache Spark 的开源测试套件 —— 既然开源社区靠这些测试来保证功能正确,那对我们来说应该也是个好起点。这些测试确实帮了大忙,但还有很多问题要考虑,因为开源开发者的设计假设,跟 Snowpark 引擎的实际情况并不完全一致。
现在,适配 Apache Spark 的 Snowpark Connect 已经能通过 80% 以上的开源 SparkSQL 测试(包括 HiveSQL 和 ANSI SQL 相关测试),以及 85% 以上的开源 PySpark 测试(比如 DataFrame、Column、Function 这些工具类的测试)。
除了用这些开源 Spark 测试,我们还自己搭了一套测试套件,一部分是手写的测试用例(专门盯着 Spark 和 Snowpark Connect 在行为上有差异的边缘情况);另一部分是 AI 生成的工作负载(模拟 Spark 用户平时常用的操作)。这套测试策略帮我们在公开预览版发布前,揪出了不少潜在的 bug 和问题,尤其是那些 Spark 默认行为没写进文档里的情况。
Snowpark 执行和矢量化查询引擎
等我们把 Spark 查询计划解释器做好后,剩下的事就简单了,只需让 Snowpark 执行处理我们通过 Snowflake 的矢量化查询引擎,去跑我们生成的优化后查询计划就行。开发这个适配 Apache Spark 的 Snowpark Connect,还顺便推动了整个技术栈的不少更新,比如优化了基于种子的随机抽样功能、提升了复杂查询计划的性能表现等等。这种架构有效地将 Snowflake 生态系统的所有优势直接带给了 Apache Spark 用户,同时也让 Snowflake 用户能轻松用 Spark 的功能,两全其美。
结论
适配 Apache Spark 的 Snowpark Connect 现已推出公共预览版,欢迎立即试用!Snowflake 正在招聘多个产品和工程岗位。探索开放职位并即刻申请,助力开发我们令人振奋的新功能。
原文地址:https://www.snowflake.com/en/engineering-blog/spark-connect-engine-snowflake-engineering-deep-dive/




