
9 月 17 日,开源 AI“顶流”DeepSeek 再次引发行业轰动。其推理模型研究论文 DeepSeek-R1,DeepSeek 创始人梁文锋以通讯作者的名义正式发表在国际顶尖期刊《自然》(Nature)上,并登上当期封面。
这不仅标志着国产 AI 研究迈入世界舞台,也意味着大语言模型首次通过了完整的同行评审,填补了行业空白。
DeepSeek-R1 的核心突破在于,该模型无需依赖大量人工标注的思维链数据,而是借助强化学习(RL)机制,让模型在训练中自主形成推理能力。研究团队首先基于 DeepSeek-V3 Base 构建出 R1-Zero,通过只奖励最终预测正确性的方式,引导模型逐渐学会生成更长、更具逻辑性的回答。随后,团队在此基础上引入多阶段训练,结合监督微调和拒绝采样,最终打造出既具备强推理性能、又符合人类偏好的 DeepSeek-R1。
在全球开源社区中,DeepSeek-R1 已成为最受欢迎的推理模型之一。截至目前,其在 Hugging Face 平台的下载量已突破 1090 万次。
新版论文回应质疑,披露训练细节
与今年初的预印版相比,本次发表于《自然》的论文补充了大量训练细节,并回应了此前外界关于“蒸馏”的质疑,总结下来可以概括为下面几个重点:
首先是数据来源问题。该论文中称,DeepSeek-V3 Base 的预训练数据完全来自互联网,虽然可能包含部分由 GPT-4 生成的文本,但团队强调未进行任何有意的蒸馏过程。
其次是去污染措施:为避免基准测试成绩“虚高”,团队对预训练和后训练数据进行了大规模清理。仅在数学数据中,就剔除了约 600 万条潜在污染样本。
安全性评估:DeepSeek-R1 引入外部风险控制机制,并通过 DeepSeek-V3 进行实时审查。在多个公开测试中,其安全性表现优于 Claude-3.7-Sonnet 和 GPT-4o 等主流模型。
此外,值得注意的是,该新版论文补充材料中首次披露了 R1 的训练成本:仅相当于 294000 美元。这不包括打造 R1 所基于的基础大模型花费掉的 600 万美元左右,但总金额仍远低于竞争对手模型所花费的数千万美元。
论文地址:
https://www.nature.com/articles/s41586-025-09422-z#code-availability
同行评审报告:
首个经过同行严格审查的模型
R1 被认为是第一个经过同行评审流程的大语言模型重要项目。“这是一个非常受欢迎的先例,”Hugging Face 的机器学习工程师 Lewis Tunstall 说道,他曾审阅过《自然》杂志的论文。 “如果我们没有公开分享这一流程大部分内容的规范,就很难评估这些系统是否存在风险。”
到底经过同行严格审查这件事有多重要?意味着什么?
据悉,DeepSeek 团队于今年 2 月 14 日将论文提交至《自然》,经过 5 个月审查,在 7 月 17 日获准接收,并于 9 月 17 日正式发表。在此期间,共有 8 位外部专家参与评审,从原创性、方法设计到鲁棒性提出了上百条意见。
这些意见既包括对单复数用法等细节的修改,也涉及更为关键的学术问题,例如:避免在论文中过度拟人化 AI、澄清“开源”概念的使用、解释数据污染防控措施,以及提供更透明的监督微调(SFT)和强化学习(RL)数据链接。
最终形成的审稿文件长达 64 页,篇幅几乎是论文本身的三倍。DeepSeek 逐一回应并吸纳了建议,在正式发表版本中新增了多处章节与补充材料。
《同行评审报告》的关键结果指出:
以往的研究表明,大语言模型在涉及数学或逻辑推理的任务中,如果在生成最终答案前先生成推理过程,往往能取得更好的表现。现有的方法主要包括:通过提示工程(例如在输入中添加“让我们一步一步思考”这样的字符串)来引导模型生成推理,或者利用包含推理示例的训练数据进行监督微调。
本论文的主要贡献在于:他们证明了仅依靠强化学习,就可以教会大语言模型进行推理,而无需依赖提示工程,也几乎不依赖人工数据(如人工示范和奖励标注)。
这项研究在语言模型的后训练方法上具有奠基性意义:它展示了无需人工干预,仅通过强化学习就能实现接近专家水平的推理能力。最终得到的模型 DeepSeek R1 在多项评测基准上达到了业界领先的水平,并且已经在学术界引发了广泛关注和兴奋。
不过,论文也存在不足:其训练数据的具体组成缺乏透明度,可能会限制研究的可复现性;同时,模型开发过程中许多决策缺乏实证结果来解释其有效性。
为了回应同行评审的意见,DeepSeek 团队减少了描述中的拟人化,并增加了对技术细节的说明,包括模型训练的数据类型及其安全性。“经过严格的同行评审流程无疑有助于验证模型的有效性和实用性,”哥伦布俄亥俄州立大学的人工智能研究员 Huan Sun 表示。“其他公司也应该这样做。”
DeepSeek 的主要创新在于使用一种自动化的试错方法(即纯强化学习)来创建 R1。该过程会奖励模型得出正确答案,而不是教它遵循人类选择的推理示例。该公司表示,这就是其模型学习自身类似推理策略的方式,例如如何在不遵循人类规定的策略的情况下验证其工作原理。为了提高效率,该模型还使用估算值来对自己的尝试进行评分,而不是使用单独的算法,这种技术被称为组相对策略优化。
Huan Sun 教授表示,该模型在人工智能研究人员中“颇具影响力”。“到目前为止,2025 年几乎所有在大语言模型中进行强化学习的研究都可能以某种方式受到了 R1 的启发。”
使用了 OpenAI 输出的数据训练 R1?
1 月份的媒体报道称,OpenAI 公司(ChatGPT 和“o”系列推理模型的创建者)的研究人员认为 DeepSeek 使用了 OpenAI 模型的输出来训练 R1,这种方法可以在使用更少资源的情况下加速模型的能力。
DeepSeek 尚未将其训练数据作为论文的一部分发布。但在与审稿人的交流中,该公司的研究人员表示,R1 并非通过复制 OpenAI 模型生成的推理示例来学习。然而,他们也承认,与大多数其他大语言模型 (LLM) 一样,R1 的基础模型是在网络上训练的,因此它会吸收互联网上已有的任何 AI 生成的内容。
Huan Sun 表示,这一反驳“与我们在任何出版物中看到的一样令人信服”。Tunstall 补充道,虽然他不能 100% 确定 R1 没有接受过 OpenAI 样本的训练,但其他实验室的重复尝试表明,DeepSeek 的推理方法可能足够好,无需进行重复训练。“我认为现在的证据相当明确,仅使用纯粹的强化学习就能获得非常高的性能,”他说。
Huan Sun 教授表示,对于研究人员来说,R1 仍然非常具有竞争力。在一项名为 ScienceAgentBench 的科学任务挑战赛中,Huan Sun 教授和同事发现,虽然 R1 在准确性方面并非第一,但在平衡性能和成本方面,它是最好的模型之一。
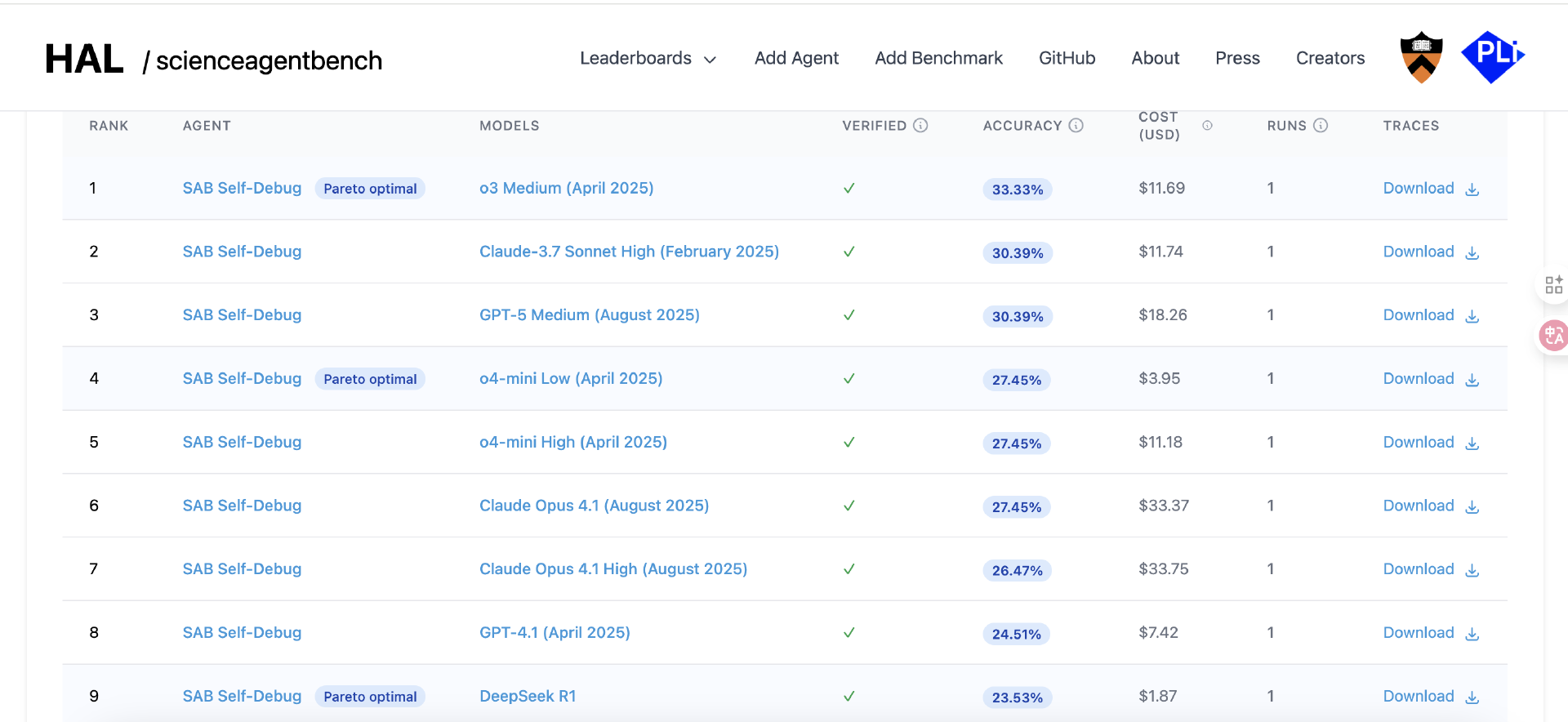
Tunstall 表示,其他研究人员目前正尝试运用创建 R1 的方法来提升现有大语言模型(LLM)的推理能力,并将其扩展到数学和编码以外的领域。他补充道,R1 以这种方式“引发了一场革命”。
参考链接:




