写点什么
创作场景
- 记录自己日常工作的实践、心得
- 发表对生活和职场的感悟
- 针对感兴趣的事件发表随笔或者杂谈
- 从 0 到 1 详细介绍你掌握的一门语言、一个技术,或者一个兴趣、爱好
- 或者,就直接把你的个人博客、公众号直接搬到这里
登录/注册
收录了 不稳定排序 频道下的 50 篇内容
有哪些常见的数据结构?基本操作是什么?常见的排序算法是如何实现的?各有什么优缺点?本文简要分享算法基础、常见的数据结构以及排序算法,给同学们带来一堂数据结构和算法的基础课。

Timsort是一种面向真实数据的高效排序算法,它不是在学术实验室中创建出来的。

这种方法消除了不稳定测试对CI和SQ的所有影响,从而大大提高了软件可靠性和开发人员生产力。

对于小规模数据,我们可以选用时间复杂度为 O(n2) 的排序算法。随着数据规模增大, O(nlogn) 的排序算法是不二选择。本篇我们主要对 O(n2) 的排序算法进行介绍
选择排序是基础排序的一种,它的思路是,原数列分为有序和无序部分,每次从无序部分中 挑出极值放入有序数列部分

希尔排序(Shell Sort)是插入排序的一种。是针对直接插入排序算法的改进版本。该方法又称缩小增量排序或者递减增量排序算法,跟插入排序不一样的是希尔排序是非稳定排序算法。因D.L.Shell于1959年提出而得名。


通过这篇文章理解排序基本概念以及稳定性,时空复杂度以及适用场景,熟练掌握直接插入排序、折半插入排序、冒泡排序这三种常见的排序算法,了解希尔排序、快速排序的执行过程以及算法。


之前的排序全面总结(上)对插入类和交换类排序作了比较详细的总结,本章内容要求熟练掌握简单选择排序算法,了解树形选择排序、堆选择排序、归并排序、基数排序的特点、时空复杂度、算法流程。
摘要冒泡排序相对来说,多少都有些了解,就是多循环几轮,每一轮找出最大值放在尾部,直到数组中的元素有序为止。

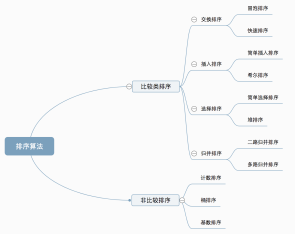
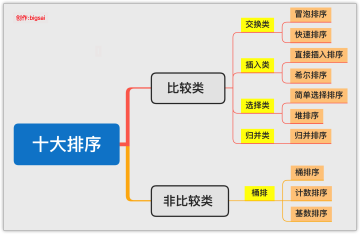
十种常见排序算法可以分为两大类: 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行

该方法因 DL.Shell 于 1959 年提出而得名。 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。

在物联网、单片机开发中,经常需要采集各种传感器的数据。比如:温度、湿度、MQ2、MQ3、MQ4等等传感器数据。这些数据采集过程中可能有波动,偶尔不稳定,为了得到稳定的值,我们可以对数据多次采集,进行排序,去掉最大和最小的值,然后取平均值返回。

连通图:在无向图G中,若从顶点i到顶点j有路径,则称顶点i和顶点j是连通的。若图G中任意两个顶点都连通,则称G为连通图。


快速排序是冒泡排序的改进版,其基本思想:选一基准元素,依次将剩余元素中小于该基准元素的值放置其左侧,大于等于该基准元素的值放置其右侧;然后,取基准元素的前半部分和后半部分分别进行同样的处理;以此类推,直至各子序列剩余一个元素时,即排序完成。


2002年,Tim Peters 开发了 Timsort 排序算法。它巧妙地结合了合并排序和插入排序的思想,并且设计得能很好地处理现实世界中的数据。TimSort 最初在 Python 开发的,但后来移植到了 Java (在 Java 中它以 java.util.Collections.sort 和java.util.Arrays.sor

 京公网安备 11010502039052号 | 产品资质
京公网安备 11010502039052号 | 产品资质