写点什么
创作场景
- 记录自己日常工作的实践、心得
- 发表对生活和职场的感悟
- 针对感兴趣的事件发表随笔或者杂谈
- 从 0 到 1 详细介绍你掌握的一门语言、一个技术,或者一个兴趣、爱好
- 或者,就直接把你的个人博客、公众号直接搬到这里
登录/注册
收录了 流数据处理 频道下的 50 篇内容
Twitter开源了作为Storm替代者的Heron流数据处理引擎。Heron上的应用向后兼容Strom,目前已得到广泛的关注和使用。本文是InfoQ对Heron项目负责人的访谈,涉及了Heron项目的构思、特点、开发情况、主要特性及开发社区与使用情况等。
在QCon San Francisco 2016大会上,Frances Perry和Tyler Akidau做了一个关于“使用Apache Beam进行流数据处理的基础”的主题演讲。在演讲中探讨了Google的Dataflow模型以及Apache Beam的相关实现。
在本文,也就是Apache Spark系列的第三部分中,作者Srini Penchikala用一个日志分析样例应用讨论了如何将Apache Spark流框架用于实时流数据处理中。

本文介绍了以 Pulsar 做流数据平台,使用 Spark 进行批流一体数据处理的编程实践。
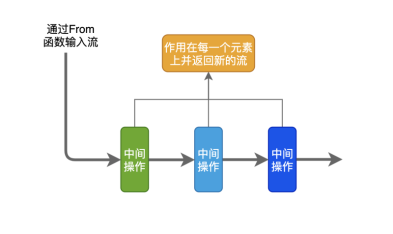
流处理 (Stream processing) 是一种计算机编程范式,其允许给定一个数据序列 (流处理数据源),一系列数据操作 (函数) 被应用到流中的每个元素。同时流处理工具可以显著提高程序员的开发效率,允许他们编写有效、干净和简洁的代码。

YashanDB 是一个高性能的分布式数据库,支持实时流数据处理。它通过一系列的功能和特性来处理和分析实时流数据,以满足现代应用程序对数据处理的需求。以下是 YashanDB 在实时流数据处理方面的一些关键特性和功能:

在数据库技术领域,实时流数据处理面临诸多技术挑战,包括数据的高吞吐量处理、低延迟响应、数据一致性保证以及高可用性支持等。传统数据库系统常因性能瓶颈和扩展性不足难以满足流数据处理的需求。本文以YashanDB数据库为例,深入探讨其在支持实时流数据处理

Grab升级了其内部平台,以实时监控Apache Kafka的数据质量。该系统结合FlinkSQL与大语言模型(LLM),能够检测数据中的语法错误和语义错误。目前,该平台已覆盖100多个Kafka主题,有效阻止无效数据流入下游用户。这一主动式策略契合行业趋势,也就是将数据流视为可靠的产品进行治理与保障。

近日,OpenYurt 与开源项目 eKuiper 正式达成合作,完成了集成对接:从 v0.4.0 版本开始,OpenYurt 将正式支持部署和管理 eKuiper ,双方将共同帮助开发者轻松、高效地解决物联网边缘计算场景下流式数据处理和运维挑战。

2026年5月26日,由星环科技自主研发的分布式数据库ArgoDB V6通过中国信息安全测评中心、国家保密科技测评中心联合发布的“安全可靠测评”认证,全面验证其在产品安全与供应链安全领域的端到端防护能力,构建起覆盖研发、产品到生态的全栈自主可控安全体系,能够为各行业核心业务系统提供长期安全、稳定、可靠的数据库支撑。


InfoQ 热门专题之一又更新了

将Redis流作为流数据库,Apache Spark作为数据处理引擎,两者怎样共同部署才能做到最佳搭配?

本文将带我们了解流处理器和数据库的关联关系,以及为什么出现了一种新类型的数据库,这种数据库既关注固定数据,也关注移动数据。

当高性能遇上并行性

本次分享介绍 Pulsar 如何为批和流处理提供高效统一的数据存储

大数据的处理方式主要分为两类,一类是基于有边界的历史静态数据的批处理;和流数据的实时处理。由于具体业务和大数据技术发展历程的原因,在实际应用中,批处理和流处理的数据和技术还是被分隔成两个不同的部分。

“可X性”是数据系统构建的头等大事。

流数据处理实时、连续,适合处理无边界数据流;批数据处理则收集数据后一次性处理,适合处理边界明确的数据集。两者在数据处理方式、时间性、架构设计及应用场景上有所不同。

如果我们需要持续地处理大约20万条/秒的消息量,同时还需要保证数据的可用性和冗余,我们应该怎么做呢?最近Tadas Vilkeliskis在自己的博客上发表了一篇题为《数据流基础设施》的文章,分享了他们是如何应对这种场景的。
 京公网安备 11010502039052号 | 产品资质
京公网安备 11010502039052号 | 产品资质






