
当前全球 AI 产业已从模型性能竞赛迈入智能体规模化落地的“生死竞速”阶段,“降本” 不再是可选优化项,而是决定 AI 企业能否盈利、行业能否突破的核心命脉。在此大背景下,浪潮信息推出元脑 HC1000 超扩展 AI 服务器,将推理成本首次击穿至 1 元/每百万 token。这一突破不仅有望打通智能体产业化落地“最后一公里”的成本障碍,更将重塑 AI 产业竞争的底层逻辑。
浪潮信息首席 AI 战略官刘军强调,当前 1 元/每百万 token 的成本突破仅是阶段性胜利,面对未来 token 消耗量指数级增长、复杂任务 token 需求激增数十倍的必然趋势,现有成本水平仍难支撑 AI 的普惠落地。未来,AI 要真正成为如同 “水电煤” 般的基础资源,token 成本必须在现有基础上实现数量级跨越,成本能力将从“核心竞争力”进一步升级为“生存入场券”,直接决定 AI 企业在智能体时代的生死存亡。

浪潮信息首席 AI 战略官刘军
智能体时代,token 成本就是竞争力
回顾互联网发展史,基础设施的“提速降费”是行业繁荣的重要基石。从拨号上网以 Kb 计费,到光纤入户后百兆带宽成为标配,再到 4G/5G 时代数据流量成本趋近于零——每一次通信成本的显著降低,都推动了如视频流媒体、移动支付等全新应用生态的爆发。
当前的 AI 时代也处于相似的临界点,当技术进步促使 token 单价下滑之后,企业得以大规模地将 AI 应用于更复杂、更耗能的场景,如从早期的简短问答,到如今支持超长上下文、具备多步规划与反思能力的智能体……这也导致单任务对 token 的需求已呈指数级增长。如果 token 成本下降的速度跟不上消耗量的指数增长,企业将面临更高的费用投入。这昭示着经济学中著名的“杰文斯悖论”正在 token 经济中完美重演。
来自多方的数据也有力佐证了 token 消耗量的指数级增长趋势。火山引擎最新披露的数据显示,截至今年 12 月,字节跳动旗下豆包大模型日均 token 使用量突破 50 万亿,较去年同期增长超过 10 倍,相比 2024 年 5 月刚推出时的日均调用量增长达 417 倍;谷歌在 10 月披露,其各平台每月处理的 token 用量已达 1300 万亿,相当于日均 43.3 万亿,而一年前月均仅为 9.7 万亿。

谷歌公布其 token 处理量变化
当使用量达到“百万亿 token/月”的量级时,哪怕每百万 token 成本只下降 1 美元,也可能带来每月 1 亿美元的成本差异。刘军认为:“token 成本就是竞争力,它直接决定了智能体的盈利能力。要让 AI 真正进入规模化普惠阶段,token 成本必须在现有基础上继续实现数量级的下降。”
深挖 token 成本“暗箱”:架构不匹配是核心瓶颈
当下,全球大模型竞赛从“盲目堆算力”转向“追求单位算力产出价值”的新阶段。单位算力产出价值受到能源价格、硬件采购成本、算法优化、运营成本等多种因素的影响,但不可否认的是,现阶段 token 成本 80%以上依然来自算力支出,而阻碍成本下降的核心矛盾,在于推理负载与训练负载截然不同,沿用旧架构会导致算力、显存与网络资源难以同时最优,造成严重的“高配低效”。
一是算力利用率(MFU)的严重倒挂。训练阶段 MFU 可达 50%以上,但在推理阶段,特别是对于追求低延迟的实时交互任务,由于 token 的自回归解码特性,在每一轮计算中,硬件必须加载全部的模型参数,却只为了计算一个 token 的输出,导致昂贵的 GPU 大部分时间在等待数据搬运,实际 MFU 往往仅为 5%-10%。这种巨大的算力闲置是成本高企的结构性根源。
二是“存储墙”瓶颈在推理场景下被放大。在大模型推理中,随着上下文长度的增加,KV Cache 呈指数级增长。这不仅占用了大量的显存空间,还导致了由于访存密集带来的高功耗。这种存算分离不仅带来数据迁移功耗和延迟,还必须配合使用价格高昂的 HBM,已经成为阻碍 token 成本下降的重要瓶颈。
三是网络通信与横向扩展代价愈发高昂。当模型规模突破单机承载能力时,跨节点通信成为新瓶颈。传统 RoCE 或 InfiniBand 网络的延迟远高于芯片内部的总线延迟,通信开销可能占据总推理时间的 30%以上,导致企业被迫通过堆砌更多资源来维持响应速度,推高了总拥有成本(TCO)。
对此,刘军指出,降低 token 成本的核心不是“把一台机器做得更全”,而是围绕目标重构系统:把推理流程拆得更细,支持 P/D 分离、A/F 分离、KV 并行、细粒度专家拆分等计算策略,让不同计算模块在不同卡上按需配置并发,把每张卡的负载打满,让“卡时成本”更低、让“卡时产出”更高。
基于全新超扩展架构,元脑 HC1000 实现推理成本首次击破 1 元/每百万 token
当前主流大模型的 token 成本依然高昂。以输出百万 token 为例,Claude、Grok 等模型的价格普遍在 10-15 美元,国内大模型虽然相对便宜,也多在 10 元以上。在天文数字级别的调用量下,如此高的 token 成本让大规模商业化应用面临严峻的 ROI 挑战。要打破成本僵局,必须从计算架构层面进行根本性重构,从而大幅提升单位算力的产出效率。
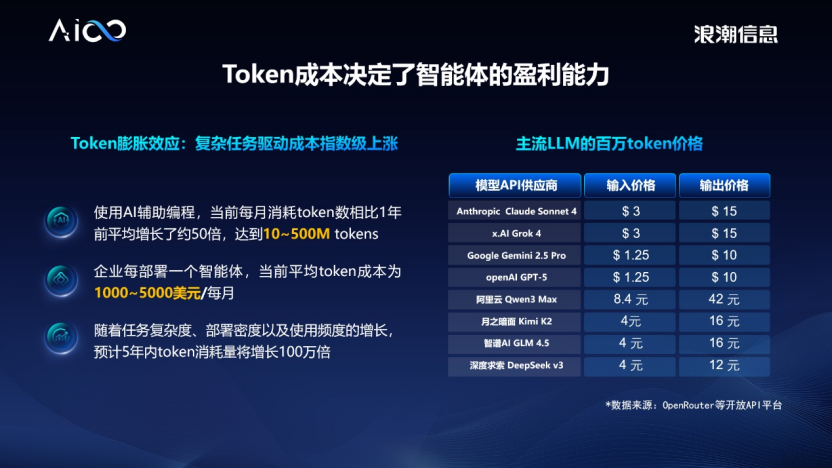
主流 LLM 的百万 token 价格
(注:9 月 26 日(AICC2025 大会当日)数据,9 月 29 日 DeepSeek 发布 V3.2 Exp 价格降为 3 元/每百万 Token)
为此,浪潮信息推出元脑 HC1000 超扩展 AI 服务器。该产品基于全新设计的全对称 DirectCom 极速架构,采用无损超扩展设计,可高效聚合海量本土 AI 芯片,支持极大推理吞吐量,推理成本首次击破 1 元/每百万 token,为智能体突破 token 成本瓶颈提供极致性能的创新算力系统。

元脑 HC1000 超扩展 AI 服务器
刘军表示:“我们看到原来的 AI 计算是瞄着大而全去建设的,五脏俱全,各种各样的东西都在里面。但是当我们聚焦降低 token 成本这一核心目标之后,我们重新思考系统架构设计,找到系统瓶颈,重构出一个极简设计的系统。”
元脑 HC1000 创新设计了 DirectCom 极速架构,每计算模组配置 16 颗 AIPU,采用直达通信设计,解决传统架构的协议转换和带宽争抢问题,实现超低延迟;计算通信 1:1 均衡配比,实现全局无阻塞通信;全对称的系统拓扑设计,可以支持灵活的 PD 分离、AF 分离方案,按需配置计算实例,最大化资源利用率。
全对称 DirectCom 极速架构
同时,元脑 HC1000 支持超大规模无损扩展,DirectCom 架构保障了计算和通信均衡,通过算网深度协同、全域无损技术实现推理性能 1.75 倍提升,并且通过对大模型的计算流程细分和模型结构解耦,实现计算负载的灵活按需配比,单卡 MFU 最高可提升 5.7 倍。

超大规模无损扩展
此外,元脑 HC1000 通过自适应路由和智能拥塞控制算法,提供数据包级动态负载均衡,实现 KV Cache 传输和 All to All 通信流量的智能调度,将 KV Cache 传输对 Prefill、Decode 计算实例影响降低 5-10 倍。
刘军强调,当前“1 元/每百万 token”还远远不够,面对未来 token 消耗量的指数级增长,若要实现单 token 成本的持续、数量级下降,需要推动计算架构的根本性革新。这也要求整个 AI 产业的产品技术创新,要从当前的规模导向转为效率导向,从根本上重新思考和设计 AI 计算系统,发展 AI 专用计算架构,探索开发大模型芯片,推动算法硬件化的专用计算架构创新,实现软硬件深度优化,这将是未来的发展方向。




