
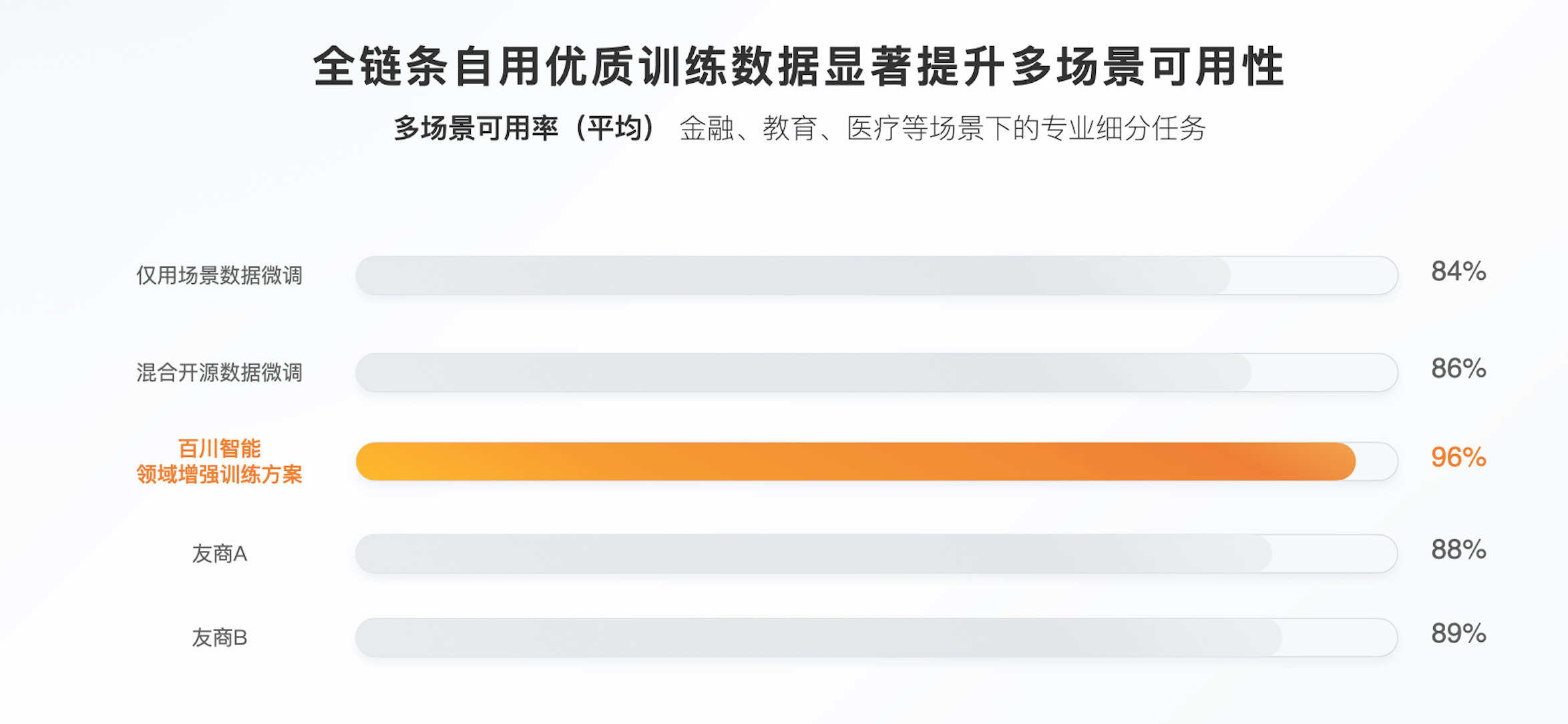
10 月 31 日,百川智能推出一站式大模型商业化解决方案,即 1+3 产品矩阵(全链路优质通用训练数据,Baichuan4-Turbo、Baichuan4-Air 两款模型和全链路领域增强工具链),支持企业将专有数据与百川智能自用的全链路优质训练数据混合,对 Baichuan4-Turbo、Baichuan4-Air 两款模型进行调优和增强,实现行业最高的 96%多场景可用率,并帮助企业以最低成本实现效果最佳的私有化部署。
如何更好进入业务场景?
尽管大模型具备良好的泛化能力,但由于每个企业都有自身独特的专业知识和应用场景,直接应用通用模型无法达到理想效果,必须对模型进行定制化优化使其适应特定领域和场景需求,而优化后模型在多场景下的可用率是评估其价值的关键标准。
此前行业的主流做法是将企业专有数据和通用数据混合定向调优、增强通用模型,但受限于诸多因素,企业很难获得与原模型高度匹配的通用训练数据,因此即便经过调优,模型也有很大概率会失去通用性,变成无法应对多个场景的专用模型。
为解决这一关键难题,百川智能将自用的优质预训练数据、SFT 微调数据、强化学习中的通用训练数据,以及自研的超参自动化搜索和调优技术、数据动态自适应配比技术等统一封装,打造了一套全链路优质通用训练数据方案。
由于 Baichuan4-Turbo、Baichuan4-Air 均为百川智能自研,所以这些优质通用训练数据与两者的数据分布高度一致,结合超参动态搜索和自适应配比等算法,与企业私有数据混合微调,显著提升了两个模型多场景下的可用率,在金融、教育、医疗等场景下的专业细分任务平均可用率高达 96%,位居行业首位。
推理成本行业同梯队最低?
成本是影响企业应用大模型的另一个重要因素。不同场景阶段,企业对模型性能和成本的要求各不相同。为更好满足行业用户的多样化需求,百川智能对两个模型进行了差异化定位。
根据百川介绍,Baichuan4-Turbo 的文本生成、知识问答、多语言处理等核心能力相比 Baichuan 4 均有显著提升,只需 2 卡 4090 的算力即可完成部署,在 GPT—4o 同档位效果的模型中部署成本最低,适合企业探索复杂场景;而 Baichuan4-Air 则更适用于已经验证过的较大规模流量场景,其效果与 Baichuan 4 基本持平,但推理成本行业最低,仅为 Baichuan 4 的 1%,百万 Token 只需 0.98 元。
此外,两款模型的响应速度也均提升显著,相比 Baichuan 4,Baichuan4-Turbo 首 Token 速度提升 51%、Token 流速提升 73%;Baichuan4-Air 的首 Token 速度提升 77%、Token 流速提升 93%。
值得一提的是,作为百川智能的首个 MoE(Mixture of Experts)模型,Baichuan 4-Air 首创了 PRI(Pyramid、Residual、Interval)架构。与标准的 MoE 架构相,Baichuan4-Air 保持了 MLP(多层感知机)和 Attention(注意力机制)的内部结构不变,仅对混合专家 MLP 层的配置方式进行优化,通过合理配置专家数量和激活策略,能够更好地平衡计算负载,减少计算量,提高推理速度。在相同训练数据下,Baichuan4-Air 不仅时效率更高,性能也大幅领先于 GPT4-style、Mixtral-style 结构的 MoE 模型。
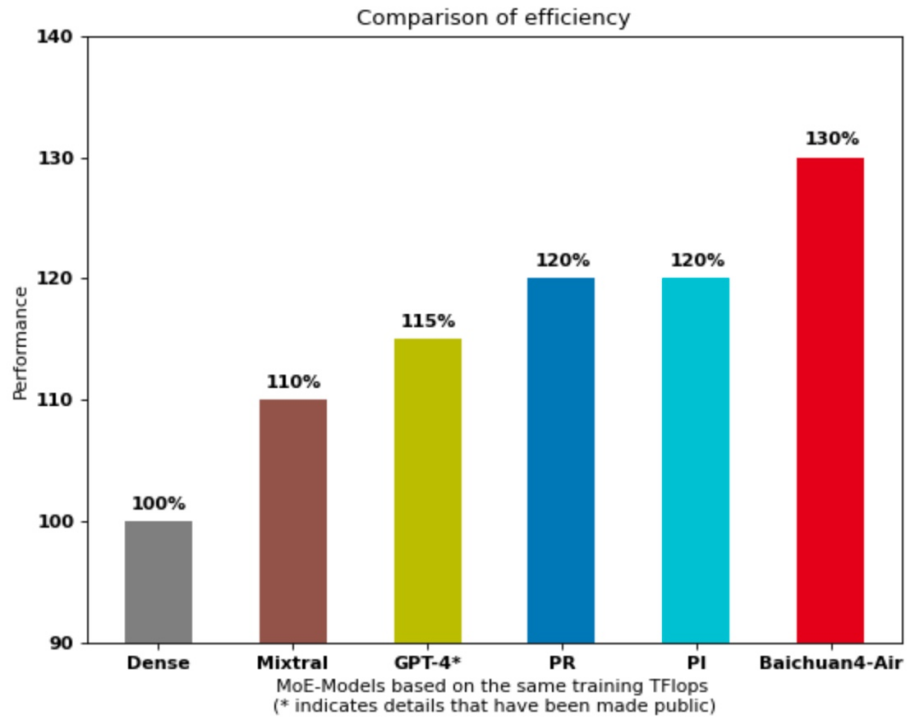
Baichuan4-Air 的时效率对比测试效果图
模型全链路部署工具链
企业在部署模型过程中还面临着专业算法人才稀缺,模型调优技术门槛高等阻碍。为此,百川智能打造了简单易用的全链路领域增强工具链。该工具链集成了数据抓取、数据清洗、数据增强、模型训练、模型评测、模型压缩和模型部署等诸多工具,企业可以根据自身需求自由选择相应工具,对模型进行加密部署和训练。
此外,百川智能还通过大量适配工作解决了不同硬件的适配问题,目前能够高效适配英伟达 4090/A/H 系列、华为昇腾、寒武纪、高通、MTK、天数等多种主流芯片。
根据百川智能客户信雅达的说法,Baichuan4-Turbo 仅需 2 张 4090 就能运行,可以大大降低硬件投入。“部署 Baichuan4-Turbo 以来,我们的客户满意度提升了 15%,运营效率提高了近 30%。”
据悉,目前百川智能客户包括北电数智、完美世界游戏、爱奇艺、360 集团、生学教育、爱学堂等,并且与信雅达、用友、软通动力、新致软件、达观数据、华胜天成等多家行业生态伙伴,以及华为、中科曙光等硬件厂商,中国移动、中国电信、中国联通等运营商达成合作。




