导读:下一代人工智能应用程序需要不断地与环境交互,并从这些交互中学习。这对系统的性能和灵活性提出了新的要求,而现有的机器学习计算框架大多无法满足这些要求。为此,UC Berkeley 项目组开发了一个新的分布式框架 Ray,并于近日在 Arvix 上发表了相关论文:《Ray: A Distributed Framework for Emerging AI Applications》。
论文第一作者为 Philipp Moritz 及 Robert Nishihara,是 UC Berkeley AMP Lab 的博士生,而 Michael I. Jordan 和 Ion Stoica 的名字也赫然列于其中。
Michael I. Jordan :UC Berkeley 电气工程与计算机科学系和统计系杰出教授,是美国国家科学院、美国国家工程院、美国艺术与科学院三院院士,是机器学习领域唯一获此成就的科学家。2016 年,他被 Semantic Scholar 评为“最具影响力的计算机科学家”。
Ion Stoica :UC Berkeley 计算机系教授,AMPLab 共同创始人,弹性 P2P 协议 Chord、集群内存计算框架 Spark、集群资源管理平台 Mesos 核心作者。
目前的计算框架存在的短板
如今大部分人工智能应用都是基于局限性较大的监督学习的范式而开发的,即模型在线下进行训练,然后部署到服务器上进行线上预测。随着该领域的成熟,机器学习应用需要更多地在动态环境下运行,响应环境中的变化,并且采用一系列的动作来完成既定目标。这些要求自然地建立在增强学习(Reinforcement Learning,RL)范式中,即在不确定的环境中连续学习。
RL 应用与传统的监督学习应用有三个不同之处:
1)RL 应用严重依赖仿真来探索所在状态及操作结果。这需要大量的计算,现实情况下,一个应用大概需要进行亿万次仿真。
2)RL 应用的计算图是异质的、动态变化的。一次仿真可能会花掉几毫秒到几分钟的时间,仿真的结果又决定未来仿真的参数。
3)许多 RL 应用程序,如机器人控制或自主驾驶,需要迅速采取行动,以响应不断变化的环境。
因此,我们需要一个能支持异质和动态计算图,同时以毫秒级延迟每秒处理数以百万计任务的计算框架。而目前的计算框架或是无法达到普通 RL 应用的延迟要求(MapReduce、Apache Spark、CIEL),或是使用静态计算图(TensorFlow、Naiad、MPI、Canary)。
RL 应用对系统提出了灵活性、表现性能以及易开发的要求,Ray 系统则是为满足这些要求而设计的。
示例

经典RL 训练应用伪代码

用Ray 实现的python 代码样例
在Ray 中,通过@ray.remote 声明remote 函数和actor。当调用remote 函数和actor methods 时会立即返回一个future(对象id),使用ray.get()可以同步获取该id 对应的对象,可以传递给后续的remote 函数和actor methods 来编码任务依赖项。每个actor 有一个环境对象 self.env,在任务之间共享状态。

上图是调用train_policy.remote() 对应的任务图。remote 函数和actor methods 调用对应任务图中的任务。图中有2 个actor,每个actor 之间的状态边(stateful edges)意味着他们共享可变状态。从train_policy 到它所调用的任务之间有控制边(control edges)。要并行训练策略(policy),可以多次调用train_policy.remote()。
原理
为了支持RL 应用所带来的异质和动态工作负荷要求,Ray 采用与CIEL 类似的动态任务图计算模型。除了CIEL 的任务并行简化外,Ray 在执行模型顶层提供了代码简化,能够支持诸如第三方仿真的状态结构。
Ray 系统结构
为了在支持动态计算图的同时满足严格的性能要求,Ray 采取一种新的可横向扩展的分布式结构。Ray 的结构由两部分组成:application 层和 system 层。Application 层实现 API 和计算模型,执行分布式计算任务。System 层负责任务调度和数据管理,来满足表现性能和容错的要求。

Ray 系统结构
该结构基于两个关键想法:
1)全局状态存储 GSC(Global Control Store)。系统所有的控制状态存储在 GSC 中,这样系统其他组件可以是无状态的。不仅简化了对容错的支持(出现错误时,组件可以从 GSC 中读取最近状态并重新启动),也使得其他组件可以横向扩展(该组件的复制或碎片可以通过 GSC 状态共享)。
2)自底向上的分布式调度器。任务由 driver 和 worker 自底向上地提交给局部调度器(local scheduler)。局部调度器可以选择局部调度任务,或将任务传递给全局调度器。通过允许本地决策,降低了任务延迟,并且通过减少全局调度器的负担,增加了系统的吞吐量。
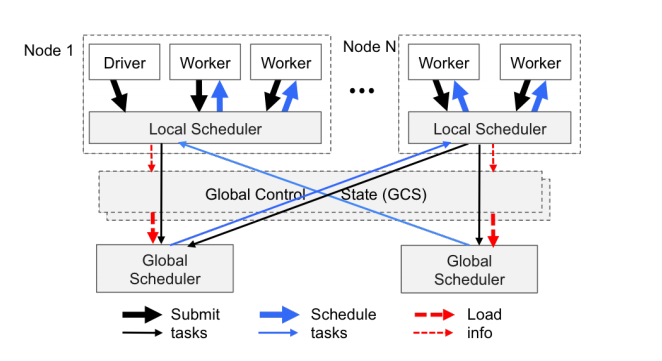
自底向上的分布式调度器
性能表现
1)可扩展性和表现性能
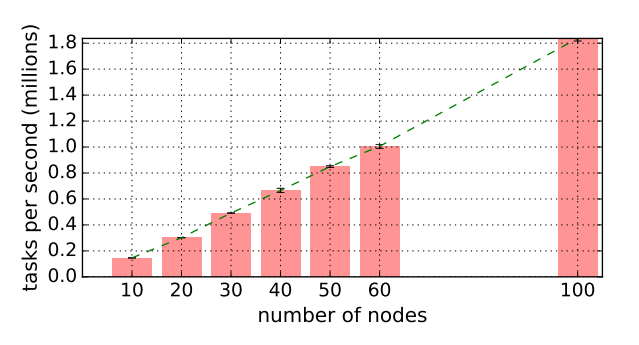
端到端可扩展性。 GCS 的主要优势是增强系统的横向可扩展性。我们可以观察到几乎线性的任务吞吐量增长。在 60 节点,Ray 可以达到超过每秒 100 万个任务的吞吐量,并线性地在 100 个节点上超过每秒 180 万个任务。最右边的数据点显示,Ray 可以在不到一分钟的时间处理 1 亿个任务(54s)。
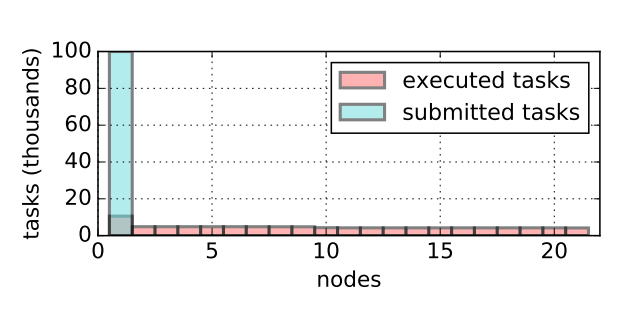
全局调度器的主要职责是在整个系统中保持负载平衡。Driver 在第一个节点提交了100K 任务,由全局调度器平衡分配给21 个可用节点。
对象存储性能。对于大对象,单一客户端吞吐量超过了15GB/s(红色),对于小对象,对象存储IOPS 达到18K(青色),每次操作时间约56 微秒。

2)容错性
从对象失败中恢复。随着 worker 节点被终结,活跃的局部调度器会自动触发丢失对象重建。在重建期间,driver 最初提交的任务被搁置,因为它们的依赖关系不能满足。但是整体的任务吞吐量保持稳定,完全利用可用资源,直到丢失的依赖项被重建。
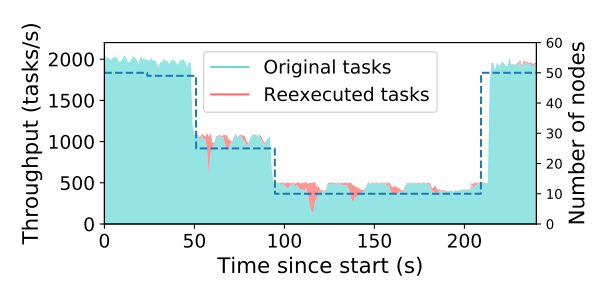
分布式任务的完全透明容错。虚线表示集群中的节点数。曲线显示新任务(青色)和重新执行任务(红色)的吞吐量,到210s 时,越来越多的节点加回到系统,Ray 可以完全恢复到初始的任务吞吐量。
从actor 失败中恢复。通过将每个actor 的方法调用编码到依赖关系图中,我们可以重用同一对象重构机制。
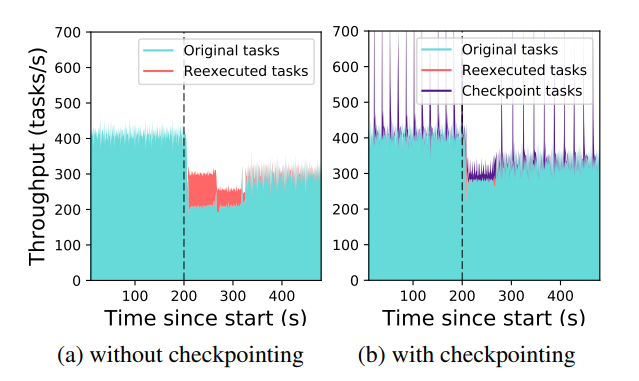
t=200s 时,我们停止 10 个节点中的 2 个,导致集群中 2000 个 actor 中的 400 个需要在剩余节点上恢复。(a)显示的是没有中间节点状态被存储的极端情况。调用丢失的 actor 的方法必须重新串行执行(t = 210-330s)。丢失的角色将自动分布在可用节点上,吞吐量在重建后完全恢复。(b)显示的是同样工作负载下,每 10 次方法调用每个 actor 自动进行了一次 checkpoint 存储。节点失效后,大部分重建是通过执行 checkpoint 任务重建 actor 的状态(t = 210-270s)。
GCS 复制消耗。为了使 GCS 容错,我们复制每个数据库碎片。当客户端写入 GCS 的一个碎片时,它将写入复制到所有副本。通过减少 GCS 的碎片数量,我们人为地使 GCS 成为工作负载的瓶颈,双向复制的开销小于 10%。
3)RL 应用
我们用 Ray 实现了两种 RL 算法,与专为这两种算法设计的系统进行对比,Ray 可以赶上甚至超越特定的系统。除此之外,使用 Ray 在集群上分布这些算法只需要在算法实现中修改很少几行代码。
ES 算法(Evolution Strategies)
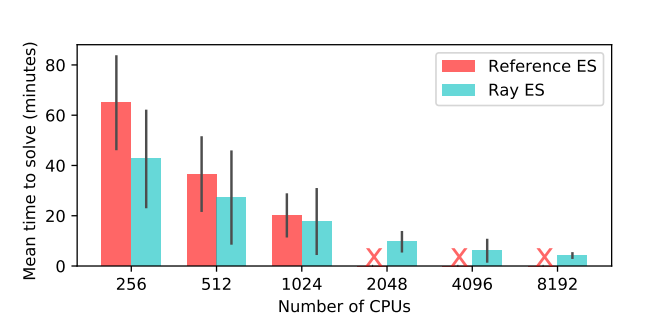
Ray 和参考系统实现 ES 算法在 Humanoid v1 任务上达到 6000 分所需时间对比。
在 Ray 上实现的 ES 算法可以很好地扩展到 8192 核,而特制的系统在 1024 核后便无法运行。在 8192 核上,我们取得了中值为 3.7 分钟的效果,比目前最好效果快两倍。
PPO 算法(Proximal Policy Optimization)
为了评估 Ray 在单一节点和更小 RL 工作负载的性能,我们在 Ray 上实现了 PPO 算法,与 OpenMPI 实现的算法进行对比。
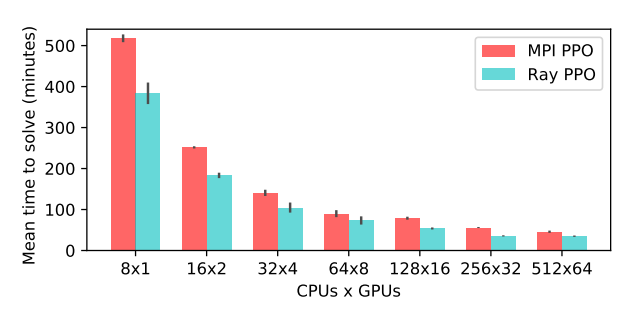
MPI 和 Ray 实现 PPO 算法在 Humanoid v1 任务上达到 6000 分所需时间对比。
用 Ray 实现的 PPO 算法超越了特殊的 MPI 实现,并且使用 GPU 更少。
控制仿真机器人
实验表明,Ray 可以达到实时控制模拟机器人的软实时要求。Ray 的驱动程序能运行模拟机器人,并在固定的时间间隔采取行动,从 1 毫秒到 30 毫秒,以模拟不同的实时要求。
未来工作
考虑到工作负载的普遍性,特殊的优化是比较难的。例如,必须在没有计算图的全部知识情况下采取调度决策。Ray 的调度决策或许需要更复杂的设置。除此之外,每个任务的存储谱系需要执行垃圾收集策略,以在 GCS 中限制存储成本,这是目前正在开发的功能。
当 GCS 的消耗成为瓶颈时,可以通过增加更多的碎片来扩展全局调度器。目前还需要手动设置 GCS 碎片和全局调度器的数量,未来将开发自适应算法来自动调整它们的数量。考虑到 GCS 结构为该系统带来的优势,作者认为集中化控制状态是未来分布式系统的关键设计元素。
查看论文原文: Ray: A Distributed Framework for Emerging AI Applications




