
具身智能蓬勃发展的当下,具有泛化性的具身能力至关重要。为了追求这个终极目标,业界发展出了两条技术路线。一条路线从机器人末端动作输出入手,发展出可以直接操作物理世界的 VLA 模型。但是 VLA 模型由于其数据稀缺性无法实现泛化。因此有了第二条路线,从本身拥有泛化能力的 VLM 入手,加速 VLM 从数字世界迈向物理世界。我们将在此路线上探索的模型称之为具身基础模型。
诚然,已经有一些研究开始了对具身基础模型的初步探索。例如,RoboBrain 系列模型在单个视觉语言模型中统一了理解、定位和规划,以促进复杂的具身任务。Robix 模型为任务执行期间更自然的人机交互做出了贡献。 然而,这些当前的具身基础模型动态认知受限,且普遍存在物理幻觉,难以适应人形机器人上的复杂任务。
主页:https://alibaba-damo-academy.github.io/RynnBrain.github.io/
简介
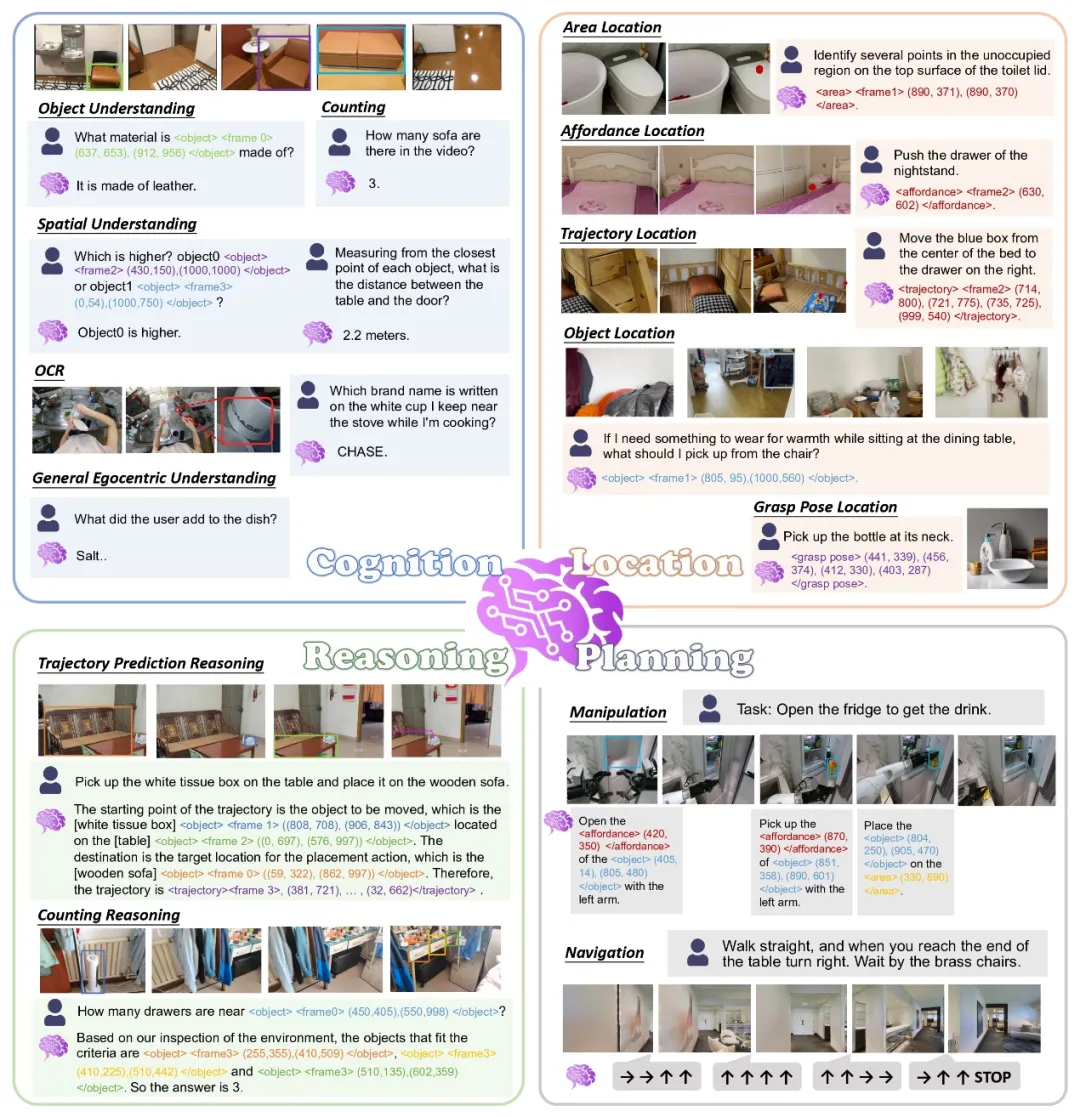
我们提出了 RynnBrain,首个可移动操作的具身基础模型。其具有以下三个关键要点:
(1)时空记忆:RynnBrain 能够在其完整的历史记忆中定位物体、目标区域,甚至预测运动轨迹,从而赋予机器人全局时空回溯能力。
(2)物理空间推理:不同于传统的纯文本推理范式,RynnBrain 采用文本与空间定位交错进行的推理策略,确保其推理过程紧密扎根于物理环境。大大减弱了具身任务中的幻觉问题。
(3)良好的可拓展性:我们在 RynnBrain 基础模型上微调了视觉语言导航和精准操作规划模型,效果轻松实现 SOTA。
通过完备的实验,RynnBrain 在 16 项具身任务 Benchmark 上全面超越了 Cosmos Reason 2 和 Gemini Robotics ER 1.5 等强大模型实现了 SOTA,并且在 8 项域外 Benchmark 上验证了超越其他具身基础模型的通用泛化性。特别的,我们开源了业界首个 MOE 具身基础模型 RynnBrain-30B-A3B,其只需要 3B 的推理激活参数就全面超越了当前规模最大的具身基础模型 Palican-VL-72B。使用我们的 MOE 模型可以让机器人在保持最强大感知和规划能力的基础上拥有更加快速的动作响应和更加丝滑的行为模式。
为推动领域发展,我们同步开源:
✅ 全系列模型(含全尺寸基础模型与后训练专有模型)
✅ 全新评测基准 RynnBrain-Bench(评测时空细粒度具身任务)
✅ 完整的推理与训练代码
RynnBrain 首次实现了“大脑”对物理世界的深度理解与可靠规划,为大小脑分层架构下的通用具身智能迈出关键一步。我们期待它加速 AI 从数字世界走向真实物理场景的落地进程。
RynnBrain 模型体系架构
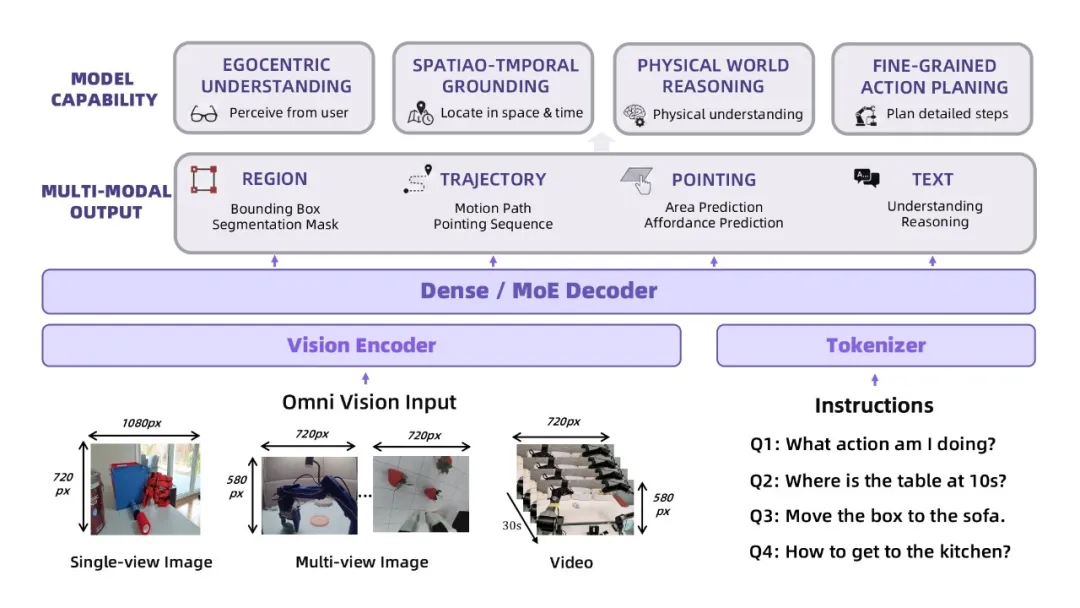
(1)模型结构
RynnBrain 在 Qwen3-VL 基础上进行训练。 使用自研的 RynnScale 架构对 Dense 模型和 MOE 模型均进行了训练速度的优化,使得在同等资源下训练加速两倍。在输入端 RynnBrain 可以接受任意分辨率的图片、多图和视频输入,满足用户任意形式的视觉输入的需求。同时 RynnBrain 可以输出区域、轨迹、点集、夹爪位姿、文本等多种具身相关模态,从而支持多样化具身任务的执行。
(2)训练优化
RynnBrain 是一款面向高泛化的具身基础模型,使用视频、图像和文本等多模态数据进行训练,覆盖从定位、空间感知等短任务到长篇多模态描述与复杂推理等多种场景。由于样本序列长度差异大且呈长尾分布,直接在数据并行训练中平均分配样本会引发“拖尾效应”,影响整体吞吐。
为此,我们引入在线负载均衡:训练时根据图像大小与文本 token 数预估序列长度,将同一 DP 组内样本统一重分配,使每个 worker 的累计序列长度尽量均衡,并用优先分配长序列的贪心策略在数据预取阶段快速完成,避免训练卡顿且无需额外数据预处理。
同时,由于重分配会造成各 worker 样本数不均,我们采用按样本的损失归约方式,保证训练前后损失一致性与收敛稳定,并显著提升训练效率。
在工程实现上,我们结合 ZeRO、梯度检查点、输出 token 过滤等技术降低显存占用;在更大规模模型中引入 ZeRO-2 与专家并行(EP),并通过优化 MoE 计算与跨卡分发提升吞吐。训练与推理框架基 HuggingFace Transformers,并已开源。
根植于物理世界的时空预训练
要制造出一种能够与周围环境进行自然互动的通用型机器人,需要具备两项基本能力:一、时空记忆:通过历史视觉记忆,机器人必须建立涵盖空间、位置、事件、轨迹等多维度的表征,从而能够适应复杂多变的环境。二、忠实于物理世界:所有机器人的认知过程都必须从根本上扎根于物理世界的客观现实之中。本章主要介绍了 RynnBrain 的预训练,该方法正是基于上述两点见解而制定的。
(1)训练策略
为赋予 RynnBrain 以上所述的时空记忆与物理世界落地能力,我们设计了一个统一的预训练框架,将多模态输入整合到共享的语义空间中。我们的训练方案聚焦于两大核心支柱:统一的输入输出表示,以及物理感知的优化策略。
统一的时空表示
为培养时空记忆,我们将图像与视频视为统一的输入模态。这样,RynnBrain 能够在视频序列中学习时间因果关系与轨迹动态,这对于理解运动与事件至关重要。
根植于物理世界的输出空间
为实现物理世界,我们对输出空间进行严格形式化,以连接高层认知与低层执行。不同于标准视觉语言模型将数字作为自由文本处理,我们引入离散的坐标 token 来表示物理位置。我们将所有空间坐标归一化到固定区间,并用整数 token 表示。这种量化将连续的物理控制转化为离散的分类问题,使模型能够使用与语言生成相同的自回归机制输出精确位置(例如抓取点或导航目标)。
(2)数据准备
我们为 RynnBrain 的预训练准备了两千万的数据对,具体数据细节如下:
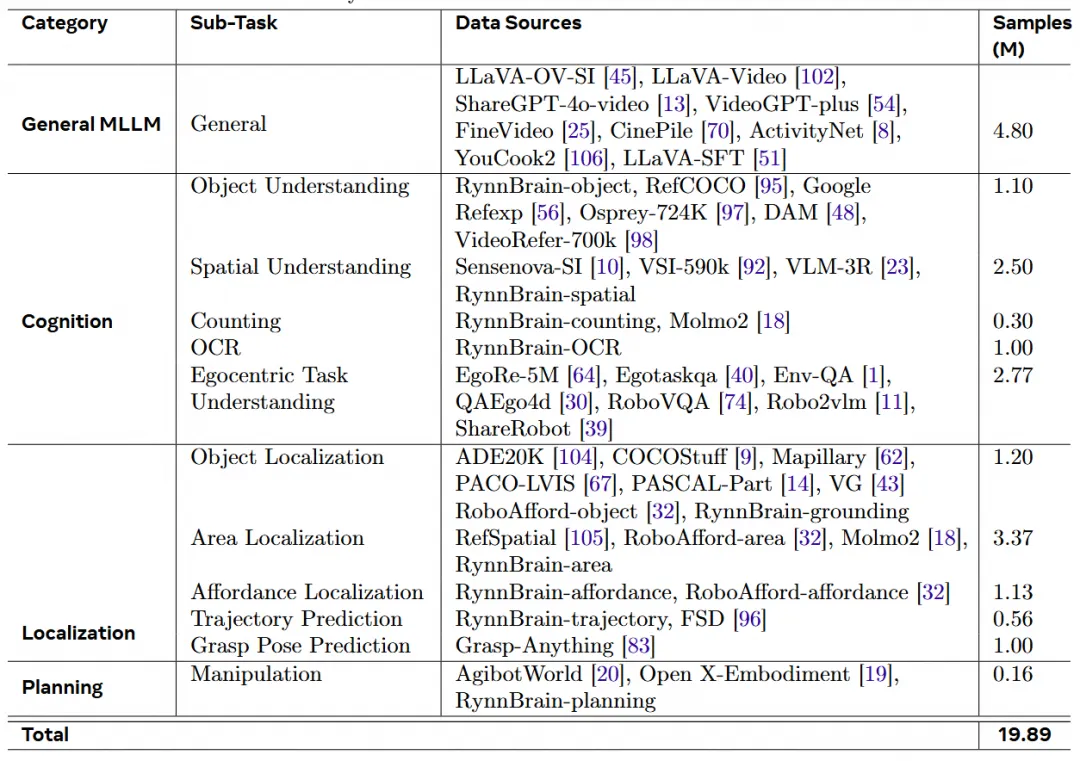
通用多模态训练数据
我们复用了团队自研的 Video-Llama 3 视频大模型的训练数据,并融合了 LLaVA-OV-SI、LLaVA-Video 等多个开源视频问答数据。
具身认知数据
物体认知、空间认知和计数相关数据复用了团队自研的 RynnEC 模型训练数据,并且引入了 Sensenova-SI、VSI-590k、Molmo2 等提高模型的空间理解和动态计数能力。此外,我们自己生成了 100 万对自我为中心的 OCR 问答数据,其中即有直接的 OCR 问题,也有需要识别视频中多个文字才能回答的情景问题。我们还收集了 EgoRe-5M、Egotaskqa 和 RoboVQA 等自我为中心的多样化问答数据以增强 RynnBrain 的自我为中心任务理解能力。
具身定位数据
RynnBrain 拥有 5 项具身定位能力,分别为:物体定位、区域定位、操作点定位、轨迹定位和夹爪位姿定位。我们为每项定位任务标注了大量额视频以及图像数据,使得 RynnBrain 在室内的定位能力上拥有突出的泛化性。我们还用 ADE20K、Grasp-Anything、PACO-LVIS 等开源数据平衡整体数据集。
规划数据
规划任务包含导航和操作两类。导航使用了 R2R 和 RxR 数据和 ScaleVLN 的开源数据。并且将数据格式变成了流式的格式。操作规划数据源来自 OpenX-Embodiment 和 AGIBot。首先,我们将这两个数据集中所有的规划数据都整合成时间段和子任务标注一对一匹配的格式。然后我们让人工标注出每个子任务规划中跟物体、区域和操作相关的名字。例如:“拿起香蕉放到桌子的左下角”,在这句话中与物体相关的词语是“香蕉”,与区域相关的词语是“桌子的左下角”,与操作相关的词语是“拿起”。然后人工再将这些词语和图像中的位置信息做对应,操作词语与图像中的操作点对应,物体词语与图像中物体的检测框对应,区域词语与图像中的区域点对应。最终得到文本和定位信息穿插的子任务标注数据。
基于 RynnBrain 的后训练-让具身拓展无限可能
(1)物理空间推理模型
目前,大多数多模态推理模型采用纯文本推理范式。虽然一些方法通过工具使用(例如放大)来缓解视觉识别中的挑战,但这种推理范式存在泛化能力有限的问题,只能解决一小部分问题。此外,探索在推理过程中进行视觉想象的替代方法通常会受到生成图像中严重幻觉的困扰。
鉴于具身大脑在现实世界中运行,进行物理空间推理的能力变得至关重要。因此,在 RynnBrain 中,我们提出了一种交错推理方法,该方法将实体化与文本信息直接结合在以自我为中心的视频流中。这种范式有效地弥合了语言与物理世界之间的认知鸿沟,确保推理过程牢固地扎根于现实之中。下面详细介绍了 RynnBrain 在物理空间推理领域的贡献和探索。
我们设计了 5 类空间推理任务——计数、物体定位、操作点定位、区域定位和轨迹预测,来验证 RynnBrain 新提出的“文本-空间交织”推理范式。
训练策略:
我们采用组相对策略优化(GRPO)来使模型与物理空间推理任务对齐。不同于标准 PPO 需要价值函数来估计优势项,GRPO 通过对同一提示下生成的多个采样输出的组内得分来估计基线。这显著降低了显存占用与训练复杂度。
训练从我们的冷启动模型初始化。我们使用 SGLang 推理引擎以高效生成 rollout,组大小设为 5。训练共进行 10 个 epoch,batch size 为 128。我们采用余弦学习率调度进行策略优化,并进行 3% 的 warmup。为保证稳定性,我们将截断范围设为[0.2, 0.28],KL 系数 0.02。最大序列长度设为 16,384 个 token,以适配长上下文的第一视角视频推理。
数据构建采用“AI 生成+人工精标”策略:
从自采第一人称视频中抽取样本;
多模态大模型生成初步推理链,并用方括号标记关键实体(如“[白色花图案的墙纸]”);
由大语言模型初步分类实体为“物体”或“区域”;
人工标注员最终审核并精标:
对“对象”标注边界框,
对“区域”标注代表性点集,
并选择最清晰的视频帧作为参考帧。
所有定位结果以结构化格式