
TL;DR
ClickHouse 表过去只能拥有一个主索引。
现在它们可以拥有多个索引,这些索引通过轻量级投影实现,其行为与主索引一致,而且不会复制数据。
想快速了解一下?
观看 Mark 讲解投影如何在 ClickHouse 中充当二级索引:
https://www.youtube.com/watch?v=Fe6DqnWBs1I
为什么投影如此重要
主索引是 ClickHouse 用来加速带过滤条件查询的核心机制。通过按照表的排序键顺序将数据行写入磁盘,引擎维护了一个稀疏索引,可以快速定位相关的数据范围。然而,由于该索引依赖于表在磁盘上的物理排序顺序,每个表只能定义一个主索引。
为了加速那些过滤条件无法很好匹配这唯一主索引的查询,ClickHouse 引入了投影 —— 由系统自动维护的、对用户透明的表结构副本,它们采用不同的排序顺序,因此拥有不同的主索引。这些替代布局可以显著加速受益于这些排序方式的查询。过去的主要代价在于存储成本:投影会在磁盘上完整复制基表的数据。
作为二级索引的轻量级投影
不过,从 25.6 版本开始,ClickHouse 可以创建更加轻量的投影,它们在功能上等同于二级索引,但不再复制完整的数据行。这类投影不存储完整的数据副本,而是只保存自身的排序键以及一个_part_offset 指针,用于指向基表中的对应位置,从而显著降低存储开销。
在合适的场景下,ClickHouse 会将这类投影的主索引当作二级索引使用,用于定位匹配的行,同时实际的行数据仍然从基表中读取。多个轻量级投影可以同时生效,因此当查询包含多个过滤条件时,可以同时利用所有适用的投影;如果其中某个过滤条件还能匹配基表自身的主索引,该主索引也会一并参与。
从 part 级裁剪演进到 granule 级裁剪
在此之前,这种机制只能在 part 级别进行裁剪,也就是整块数据文件的排除,尚不支持 granule 级别的精细裁剪。
而在本次发布中,基于 _part_offset 的投影已经真正演进为二级索引,支持 granule 级裁剪,使过滤粒度更加精细,查询性能也随之大幅提升。
示例:组合使用多个投影索引
为了说明这一点,我们再次使用英国房产成交价格数据集。这一次,我们定义了一个包含两个轻量级、基于 _part_offset 的投影的表:by_time 和 by_town:
CREATE OR REPLACE TABLE uk.uk_price_paid_with_proj( price UInt32, date Date, postcode1 LowCardinality(String), postcode2 LowCardinality(String), type Enum8( 'terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0), is_new UInt8, duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0), addr1 String, addr2 String, street LowCardinality(String), locality LowCardinality(String), town LowCardinality(String), district LowCardinality(String), county LowCardinality(String), PROJECTION by_time ( SELECT _part_offset ORDER BY date ), PROJECTION by_town ( SELECT _part_offset ORDER BY town ))ENGINE = MergeTreeORDER BY (postcode1, postcode2, addr1, addr2);随后,我们按照这里提供的说明加载数据(https://clickhouse.com/docs/getting-started/example-datasets/uk-price-paid)。
下图展示了基表以及它的两个轻量级、基于 _part_offset 的投影结构:
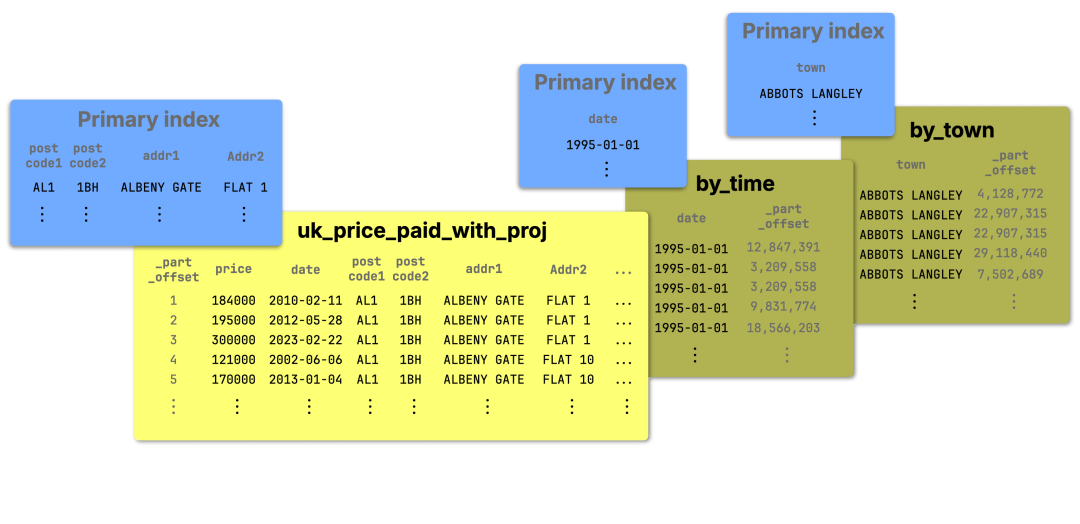
① 基表按照 (postcode1, postcode2, addr1, addr2) 进行排序,这一排序定义了它的主索引,使得按这些列进行过滤的查询非常高效。
② by_time 和 ③ by_town 投影仅保存各自的排序键以及 _part_offset,用于回溯到基表中的行位置,从而大幅减少数据复制。它们的主索引作为基表的二级索引使用,加速了按日期和 / 或城镇过滤的查询。
我们在一台 AWS m6i.8xlarge EC2 实例 (32 核,128 GB 内存) 上进行了基准测试,底层存储为 gp3 EBS 卷 (16k IOPS,最大吞吐量 1000 MiB/s)。
我们将执行一个按日期和城镇列进行过滤的查询。需要注意的是,这些列并不包含在基表的主键中。
首先,我们在关闭投影支持的情况下运行该查询,以获得基线性能。同时,我们禁用了查询条件缓存以及 PREWHERE,从而完全隔离基于索引的数据裁剪效果:
SELECT *FROM uk.uk_price_paid_with_projWHERE (date = '2008-09-26') AND (town = 'BARNARD CASTLE')FORMAT NullSETTINGS use_query_condition_cache = 0, optimize_move_to_prewhere = 0, optimize_use_projections= 0;三次运行中最快的一次耗时 0.077 秒:
0 rows in set. Elapsed: 0.084 sec. Processed 30.73 million rows, 1.29 GB (363.92 million rows/s., 15.26 GB/s.)Peak memory usage: 129.07 MiB.0 rows in set. Elapsed: 0.076 sec. Processed 30.73 million rows, 1.29 GB (406.96 million rows/s., 17.07 GB/s.)Peak memory usage: 129.29 MiB.0 rows in set. Elapsed: 0.077 sec. Processed 30.73 million rows, 1.29 GB (398.51 million rows/s., 16.71 GB/s.)Peak memory usage: 129.27 MiB.可以看到,这是一次全表扫描,读取了整个表 (约 3000 万行)。
接下来,我们在启用投影支持的情况下再次运行查询:
SELECT *FROM uk.uk_price_paid_with_projWHERE (date = '2008-09-26') AND (town = 'BARNARD CASTLE')FORMAT NullSETTINGS use_query_condition_cache = 0, optimize_move_to_prewhere = 0, optimize_use_projections= 1; -- default value三次运行中最快的一次耗时仅为 0.010 秒:
0 rows in set. Elapsed: 0.010 sec. Processed 16.38 thousand rows, 644.86 KB (1.60 million rows/s., 63.06 MB/s.)Peak memory usage: 4.89 MiB.0 rows in set. Elapsed: 0.010 sec. Processed 16.38 thousand rows, 644.86 KB (1.69 million rows/s., 66.36 MB/s.)Peak memory usage: 4.88 MiB.0 rows in set. Elapsed: 0.011 sec. Processed 16.38 thousand rows, 644.86 KB (1.54 million rows/s., 60.57 MB/s.)Peak memory usage: 4.89 MiB.最终结果是:0.077 秒 对比 0.010 秒,查询耗时下降了约 90%。
同时可以看到,这一次实际扫描的行数只有约 1.6 万行,而不是全部约 3000 万行。
通过 EXPLAIN 可以观察到,ClickHouse 正在将两个投影的主索引作为二级索引,用于裁剪基表中的 granule:
EXPLAIN projections = 1SELECT *FROM uk.uk_price_paid_with_projWHERE (date = '2008-09-26') AND (town = 'BARNARD CASTLE')SETTINGS use_query_condition_cache = 0, optimize_move_to_prewhere = 0, optimize_use_projections= 1; -- default value┌─explain────────────────────────────────────────────────────────────┐ 1. │ Expression ((Project names + Projection)) │ 2. │ Filter ((WHERE + Change column names to column identifiers)) │ 3. │ ReadFromMergeTree (uk.uk_price_paid_with_proj) │ 4. │ Projections: │ 5. │ Name: by_time │ 6. │ Description: Projection has been analyzed... │ 7. │ Condition: (date in [14148, 14148]) │ 8. │ Search Algorithm: binary search │ 9. │ Parts: 5 │10. │ Marks: 7 │11. │ Ranges: 5 │12. │ Rows: 57344 │13. │ Filtered Parts: 0 │14. │ Name: by_town │15. │ Description: Projection has been analyzed... │16. │ Condition: (town in ['BARNARD CASTLE', 'BARNARD CASTLE']) │17. │ Search Algorithm: binary search │18. │ Parts: 5 │19. │ Marks: 5 │20. │ Ranges: 5 │21. │ Rows: 40960 │22. │ Filtered Parts: 0 │ └────────────────────────────────────────────────────────────────────┘ 在 EXPLAIN 输出的第 10 行可以看到,by_time 投影 (更准确地说是它的主索引) 首先将搜索范围缩小到 7 个 granule (即 “Marks”)。由于每个 granule 包含 8,192 行数据,这意味着需要扫描 7 × 8192 = 57,344 行 (如第 12 行所示)。这 7 个 granule 分布在 5 个数据 part 中 (第 9 行),因此引擎需要读取 5 个对应的数据范围 (第 11 行)。
随后,从第 14 行开始应用 by_town 投影的主索引。它进一步从 by_time 投影筛选出的 7 个 granule 中排除了其中的 2 个。最终,查询只需要扫描 5 个 granule,它们分别位于基表的 5 个 part 中的 5 个数据范围内,因为这些 granule 可能包含同时满足时间和城镇过滤条件的行。
为控制这一优化过程,引入了两个新的设置参数:
max_projection_rows_to_use_projection_index:当从投影中估算需要读取的行数小于或等于该值时,允许使用投影索引。
min_table_rows_to_use_projection_index:当从基表中估算需要读取的行数大于或等于该值时,才会考虑使用投影索引。
关键结论
ClickHouse 表过去只能拥有一个主索引。
而现在,它们可以拥有多个索引,每一个都具备主索引级别的能力。当查询包含多个过滤条件时,ClickHouse 会同时利用这些索引。





