
最大化生成式 AI 投资回报率:借助 vLLM 在 Snowflake 上托管开源模型
随着生成式 AI 从“探索阶段”走向“生产核心阶段”,许多数据团队面临的问题不再是“是否应该使用 LLM”,而是“如何高效部署 LLM”。尽管 GPT-5 和 Claude 等商业 API 功能强大,但一种新范式正在兴起:将开源模型直接托管在企业的数据平台内部。
本文将探讨为何要让模型“靠近”数据、Snowflake 容器服务(SPCS)如何实现这一目标,以及如何通过 vLLM 等特定架构实现快速且经济高效的部署。
Token 与 GPU:为何选择托管开源模型?
许多企业的默认选择是调用商业 API(如 OpenAI、Anthropic)。尽管这种方式便捷,但对于企业级工作负载而言,这种“Token”模式存在三个明显弊端:
成本扩展性:使用商业 API 需按 Token 付费。当企业的使用量从数千笔交易增长到数百万笔时,成本会呈线性增长且无明确上限。
数据隐私:将敏感个人身份信息(PII)或专有数据发送到外部 API 端点,往往会违反严格的合规与安全治理要求。
“通用型”额外开销:商业模型是庞大的“无所不知”的通用型模型。通常,一个较小的、针对您特定数据微调的开源“专业型”模型(如 Llama 3 8B 或 Mistral),在执行您的特定任务(例如总结您的财务报告)时,可能比通用的大型模型更快、更准确。
GPU 的优势
在 Snowflake 上托管模型将颠覆传统的财务模式:您只需为基础设施(计算资源)付费,而非按 token 计费。如果您 24 小时不间断地运行 GPU,无论您处理的是 100 万还是 1 亿个 token,成本都是固定的。对于高容量工作负载,这能带来巨大的投资回报率。
核心引擎:SPCS 与 GPU 推理
过去,托管 LLM 需要复杂的外部基础设施(如 Kubernetes 集群、AWS Sagemaker),这会迫使数据离开企业的安全环境。
Snowflake 容器服务(SPCS)改变了这一现状。它让企业能够在 Snowflake 的安全边界内,直接运行容器化工作负载(Docker 镜像)。
计算池:这些是为容器提供动力的虚拟机集群。关键在于,Snowflake 提供 GPU 加速计算池(采用 NVIDIA A10 和 A100 显卡),专为 AI 推理设计。
零数据迁移:由于容器在 Snowflake 内部运行,您的 LLM 可以直接查询 Snowflake 表,数据无需经过公共互联网。
参考资料:有关架构的深入了解,请参阅 Snowflake 容器服务文档。
Ollama 与 vLLM:选择合适的推理引擎
如果您尝试使用标准的“Hugging Face Transformers”Python 代码运行 Llama 3,对于生产环境来说可能太慢。这正是 vLLM 的优势所在。

结论:对于生产环境的 SPCS 部署,务必将您的 Llama 或 Mistral 模型封装在 vLLM 容器中。
硬件选型:GPU 与扩展策略
部署前,您必须将模型大小与合适的 Snowflake 计算池匹配。如果模型无法适配 GPU 的显存(VRAM),则无法运行。可使用 CanLLMRun.me 等计算器估算显存使用量。粗略经验法则:参数数量(十亿级)×2=所需显存容量(GB,FP16 精度)。
策略一:单 GPU(1 节点,1 块 GPU)
适用场景:小型模型(参数<150 亿);
Snowflake 计算池:GPU_NV_S(1 块 NVIDIA A10G,24GB 显存);
vLLM 配置:无需特殊参数;
最适配:Llama 3 8B、Mistral 7B、Gemma 7B。
策略二:单节点,多 GPU(张量并行)
适用场景:中大型模型(700 亿参数)。单块 GPU 无法承载,但可容纳于单台服务器;
Snowflake 计算池:GPU_NV_M(4 块 NVIDIA A10G 显卡)或 GPU_NV_L(8 块 NVIDIA A100 显卡);
vLLM 配置:— tensor-parallel-size 4(或 8);
工作原理:vLLM 将模型权重拆分至多块显卡,通过高速 NVLink 连接实现通信;
最适配:Llama 3 70B、Mixtral 8x7B。
策略三:多节点多 GPU(超大规模)
适用场景:超大型模型(例如 Llama 3.1 4050 亿参数),超出单台 8GPU 节点的显存容量;
状态:本指南暂不涉及;
原因:该规模模型的部署需编排复杂的分布式集群(通常基于 Ray 框架)、管理高级流水线并行,且需确保机器间超低延迟网络通信。这需要专用硬件配置和运维开销,对绝大多数企业应用场景而言并非必需。
部署流程:Snowflake 模型注册表的“一键部署”方案
传统上,将模型部署至 SPCS 这类容器服务是一个多步骤、DevOps(开发运维)工作负载繁重的过程,需执行以下操作:
手动编写 Dockerfile 文件;
构建镜像并推送至镜像仓库;
编写复杂的 YAML 配置文件;
执行 SQL 命令创建服务。
Snowflake 模型注册表应运而生
模型注册表几乎屏蔽了所有此类复杂流程。无需繁琐调试 Docker 与 YAML 配置,直接通过 Python 代码即可完成模型部署。调用部署 API 时,Snowflake 会自动完成容器构建、端点配置,并在指定 GPU 池中启动服务,所有操作均在后台自动化执行。
可选方案:“点击式操作”与 Python 方案优势对比
在深入代码之前,值得一提的是 Snowflake 还提供无代码 UI 部署路径。如近期技术博客《借助Snowflake实现高性价比AI推理的规模化部署》(Scaling Price-Performant AI Inference with Snowflake)中所述,您通常可以直接通过 Snowsight 网页界面部署标准 Hugging Face 模型。
本文剩余部分将介绍下述“低代码”Python 方案。原因如下:目前,UI 部署适用于标准场景,但如果需要向 vLLM 引擎传递特定的高级参数(例如调整 gpu_memory_utilization、max_model_len 或特定的量化配置),则需要使用 Python SDK。尽管这些高级配置选项已纳入 UI 功能规划,但现在,通过 Python 的 create_service 函数,您就可以获得完全控制权,优化推理引擎以实现最大吞吐量。
只需几行 Python 代码,即可实现从 Hugging Face 模型到 Snowflake 实时推理端点的部署,具体步骤如下:
步骤 1:连接并注册模型
首先,指定要使用的模型。注册表支持直接从 Hugging Face 注册模型。若您可直接访问 Hugging Face 且已配置外部访问权限,即可直接获取该模型并将其注册到模型注册表中。
# Pick your model of choice from HFimport huggingface_hubfrom snowflake.ml.model import HuggingFacePipelineModelfrom snowflake.ml.model import openai_signaturesfrom snowflake.ml.utils import connection_paramsfrom snowflake.snowpark import Sessionfrom snowflake import snowparkfrom snowflake.ml.registry import registry as registry_modulefrom snowflake.ml.utils.connection_params import SnowflakeLoginOptionsmodel = "Qwen/Qwen3-30B-A3B"model_ref = HuggingFacePipelineModel( model="Qwen/Qwen3-30B-A3B", task="text-generation",)# Get a reference to model registry session = session = get_active_session()assert session is not Noneregistry = registry_module.Registry( session=session,)assert registry is not None# Log your model into model registrmodel_name = "Qwen3_30B_A3B_model_final"mv = registry.log_model( model=model_ref, model_name=model_name, signatures=openai_signatures.OPENAI_CHAT_SIGNATURE)mv对于具有严格安全或网络限制的环境(例如隔离网络),可能无法直接访问互联网或 Hugging Face。在此类场景下,可采用跨环境方案:在具备网络访问权限的环境中(如本地机器或开发环境账号)预先下载模型,随后切换会话,将模型注册至受限制的 Snowflake 环境。下方代码演示了如何将模型下载至本地缓存,然后将其注册到无外部网络连接的注册表中。
model = "Qwen/Qwen3-30B-A3B"cache_dir = "Qwen/Qwen3_30B_A3B"repo_snapshot_dir = huggingface_hub.snapshot_download( repo_id=model, cache_dir=cache_dir,)model_ref = HuggingFacePipelineModel( model="Qwen/Qwen3-30B-A3B", task="text-generation", download_snapshot=False,)assert model_ref.repo_snapshot_dir is Nonemodel_ref.repo_snapshot_dir = repo_snapshot_dirassert not model_ref.repo_snapshot_dir is None步骤 2:使用 create_service 部署
这是实现“一键部署”的核心命令。create_service 方法会接收已注册的模型并将其部署到 SPCS,只需指定它要使用的计算池和所需的 GPU 数量即可。
## Take Note of model version printed after logging the model and update the model version in next line! #### TO DO #####model_name = "QWEN3_30B_A3B_MODEL_FINAL"version_name = "WICKED_BADGER_1"mv = registry.get_model(model_name).version(version_name)from snowflake.ml.model.inference_engine import InferenceEnginemv.create_service( service_name="Qwen3_30B_A3B_service_vLLM", service_compute_pool="MAHDI_GPU_COMPUTE_POOL", # Pick a compute pool name with GPU gpu_requests="4", # 4 if the compute pool has 4 GPUs ingress_enabled=True, # set a False if you don't want to create a service endpoint image_repo="MAHDI_PLAYGROUND.LLMS.Qwen3_30B_A3B_image_repo", # Optional: specify a container services image repo name inference_engine_options={ "engine": InferenceEngine.VLLM, "engine_args_override": [ "--tensor-parallel-size=4", "--gpu-memory-utilization=0.85", "--max-model-len=1024", "--max-num-seqs=2" ], },)后台是如何进行的?
当您运行 create_service 时,Snowflake 会自动执行以下操作:
容器化:动态生成 Docker 镜像,包含您的模型、正确的 Python 环境(Conda)和推理服务器逻辑;
镜像仓库:在需要时,后台构建并推送该镜像到您的内部 Snowflake 镜像仓库!使用 vLLM 引擎时,create_servic 会跳过构建步骤,因为系统仓库中的镜像已足以启动推理服务器。构建推理镜像通常需要约 15 分钟,使用 vLLM 可节省这部分时间;
服务创建:生成必要的服务配置,并在您指定的计算池上执行 CREATE SERVICE 命令。
通过使用模型注册表,您可以有效省去“基础设施搭建”环节,专注于模型及应用。
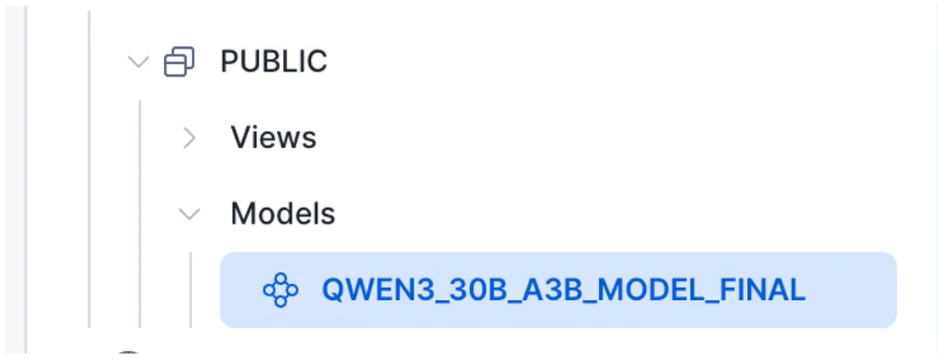
模型注册表
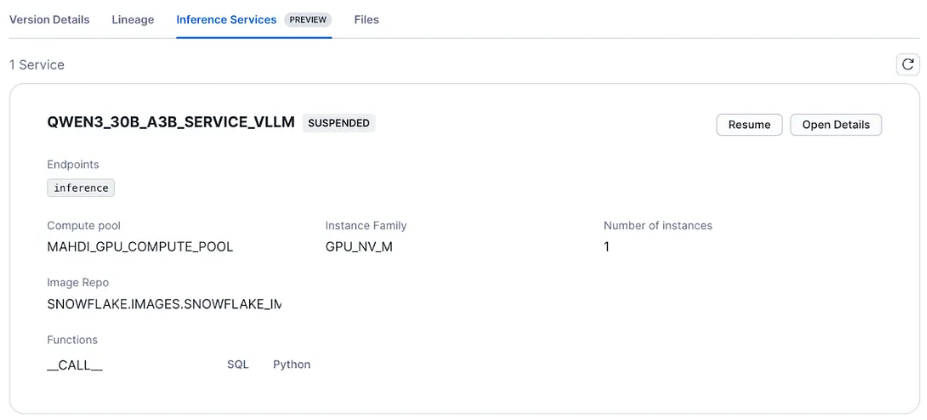
推理服务
推理服务步骤 3:开始推理!
import openaiclient = openai.OpenAI(base_url=url, api_key="not_a_real_key")services_df = mv.list_services()services_dfendpoint = services_df.iloc[-1]["inference_endpoint"] # change index if the model has more than once service## v1 is the current version of inference endpoint for Open AI compatible APIs## no relation with model versioning in Snowflake ML Registryurl = f"https://{endpoint}/v1"url## in next line, you don't need an actual key from openai. ## You can pass any string.. ## the Snowflake PAT is what it is being used for authentication. client = openai.OpenAI(base_url=url, api_key="not_a_real_key")pat = "........."#model_name="Qwen3_30B_A3B_model_final"## CASE SENSITIVE!!!!!model_name="QWEN3_30B_A3B_MODEL_FINAL"messages = [ {"role": "system", "content": "You are a helpful assistant. Answer in a concise manner."}, {"role": "user", "content": "Who is your creator??"},]completions = client.chat.completions.create( model=model_name, messages=messages, extra_headers={"Authorization": f'Snowflake Token="{pat}"'}, max_completion_tokens=250,)completions
示例输出
若您的数据存储在表格中,可使用以下 SQL 代码片段执行批量推理:
-- input table with questions in string formatCREATE OR REPLACE TABLE llm_input_table (question VARCHAR);INSERT INTO llm_input_table (question)VALUES ('What is the capital of France?'), ('What is the capital of India?'), ('What is the capital of Italy?');-- service function callwith chat_inputs as ( select array_construct( object_construct( 'role', 'system', 'content', 'You are a helpful assistant.' ), object_construct( 'role', 'user', 'content', question ) )::ARRAY as messages, 0.9::FLOAT as temperature, 100::NUMBER as max_completion_tokens, NULL::ARRAY as stop, 1::NUMBER as n, False::BOOLEAN as stream, 0.9::FLOAT as top_p, 0.9::FLOAT as frequency_penalty, 0.1::FLOAT as presence_penalty from llm_input_table)SELECT <SERVICE_NAME> ! __CALL__( messages, temperature, max_completion_tokens, stop, n, stream, top_p, frequency_penalty, presence_penalty )from chat_inputs;在您的账户中运行
点击此处获取本教程的完整代码笔记本。该工作流具有良好的灵活性——您可以直接使用 Snowflake 代码笔记本(Snowflake Notebooks, 容器运行时)运行,也可在本地通过您偏好的 IDE(如 VS Code)运行。
成功运行的前提条件:
网络连接:确保您的环境具有访问 Hugging Face 的出站权限,以便下载模型;
基础设施:必须预先配置 GPU 计算池和镜像仓库。(我已在代码笔记本开头的注释单元格中包含了必要的配置 SQL 语句);
Snowflake-ML 版本:1.20
点击链接立即报名注册:Ascent - Snowflake Platform Training - China




