
昨晚,DeppSeek 同时发布了两个正式版模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。发布即火。
新模型技术报告已同步发布:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolve/master/assets/paper.pdf
“如果说 Gemini-3 证明了预训练可以持续扩展,那么 DeepSeek-V3.2-Speciale 则证明了“超长上下文下的强化学习同样可以持续扩展。我们花了一年时间把 DeepSeek-V3 推到极限,最大的体会是:后训练阶段的瓶颈,不是靠等一个更好的基座模型来解决,而是靠不断打磨方法和数据本身。”DeppSeek 研究员 Zhibin Gou 在 x 上说道,“持续扩展模型、数据、上下文和强化学习。不要让‘遇到瓶颈’之类的说法阻碍你前进。”
新模型的能力不必多说,DeepSeek 写得很清楚:
DeepSeek-V3.2:以平衡推理能力与输出长度为目标,适配日常问答、通用 Agent 任务等场景。在推理类 Benchmark 测试中达到 GPT-5 水平,仅略低于 Gemini-3.0-Pro,且输出长度大幅短于 Kimi-K2-Thinking,显著降低计算开销与等待时间。
DeepSeek-V3.2-Speciale:作为长思考增强版,融合 DeepSeek-Math-V2 的定理证明能力,聚焦极致推理性能探索。在主流推理基准测试中媲美 Gemini-3.0-Pro,斩获 IMO 2025、CMO 2025、ICPC World Finals 2025、IOI 2025 四大国际赛事金牌(ICPC、IOI 成绩分别达人类选手第二、十名水平)。该版本仅供研究使用,Tokens 消耗更高,不支持工具调用,未针对日常对话优化。
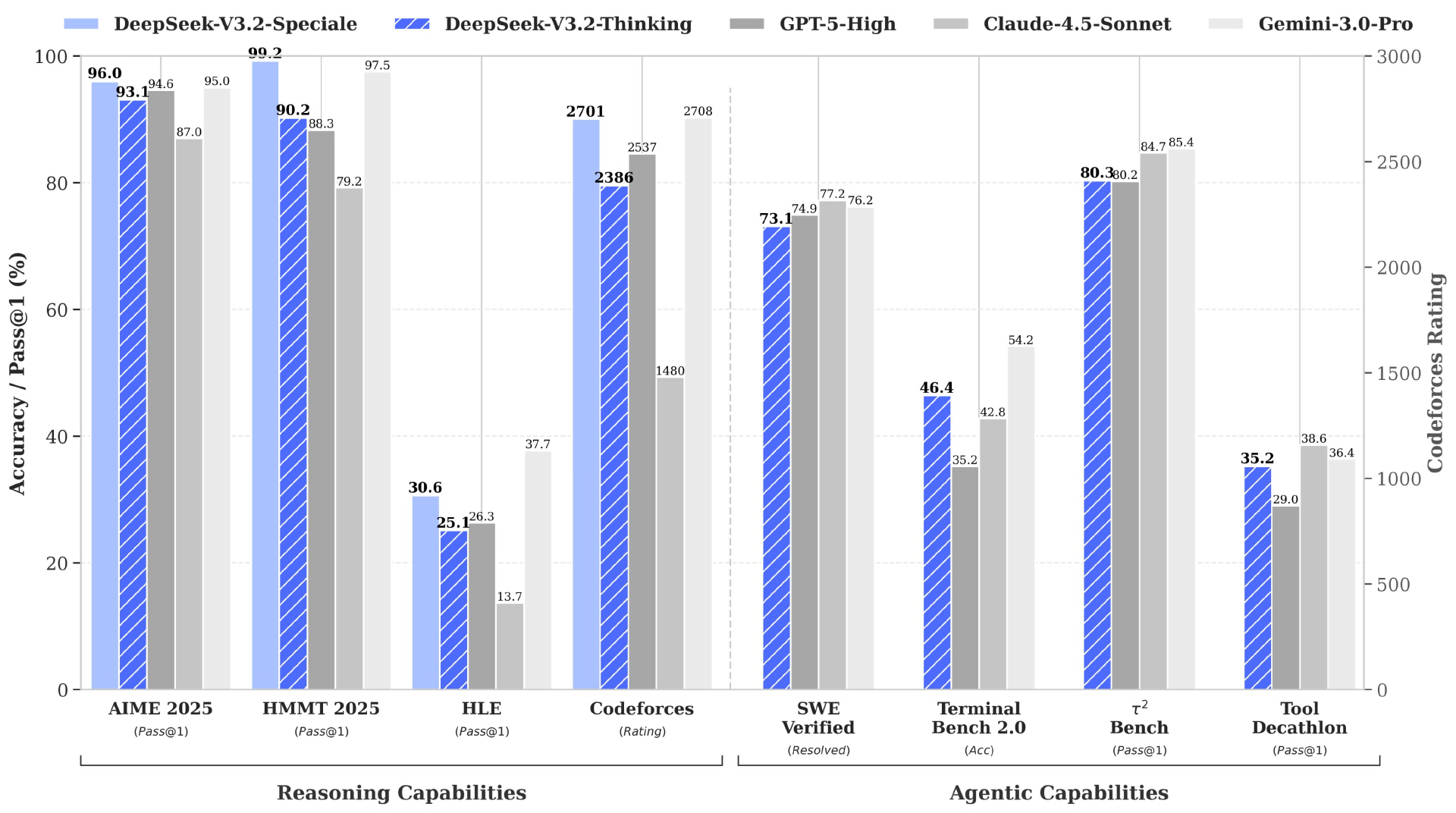
DeepSeek-V3.2 还是首个将思考融入工具使用的模型,同时支持思考模式与非思考模式的工具调用:通过大规模 Agent 训练数据合成方法(1800 + 环境、85,000 + 复杂指令)提升泛化能力;其次,在 ToolUse 相关评测集(T2-Bench、MCP-Universe 等)中表现亮眼,达到当前开源模型顶尖水平,大幅缩小与闭源模型的差距,且未针对测试集工具特殊训练,真实场景适应性更强。
发布后,DeepSeek 论文迅速引发关注。
技术上,谷歌 Deepmind Susan Zhang 总结了两个模型的亮点:
DeepSeek 通过“热启动”(独立初始化 + 独立优化动态),并在约 1 万亿 token 的训练过程中逐步适配,把注意力机制的复杂度从二次方降到了近似线性。
在预填充和解码阶段使用了不同的注意力模式
Susan 称它们在稳定 RL 训练方面也做了不少创新(远超那个号称“开放贝尔实验室”在博客里写的那些👀):
1)无偏的 KL 估计,针对不同领域使用不同的 KL 回归(!)
2)屏蔽显著负向的优势序列(adv sequences),以免“带偏”模型
3)解决 MoE 在不同框架之间训练/推理不一致的问题,具体包括:保留专家路由、保留 top-p 采样掩码
最值得关注的,可能是他们如何把 “Agent 能力”规模化:
1)更强的上下文管理能力,以及在此基础上的进一步优化
2)多样化的 Agent 配置(包括不同的 checkpoint、系统提示词)
3)规模化地创建任务/环境,最终产出了成千上万条由 “环境、工具、任务、验证器>”构成的组合。
“就连他们在“局限性”一节的表述,都有点扮猪吃老虎的味道:他们还会继续扩大预训练规模、更加专注于 token 效率、会继续追逐最前沿能力。”
“更厉害的是,他们选在 NeurIPS 开幕当天凌晨,用 ChatGPT 式的发布节奏亮出 DeepSeek Speciale,这是冲着那些只会重新包装别人成果的欧洲玩家来的 👀事实证明,最高级的‘光环收割’,永远是真刀真枪把成果开源给你看。🫡”Susan 评价道。
相关链接:
https://mp.weixin.qq.com/s/ohsU1xRrYu9xcVD7qu5lNw




