
信息技术时代,数据中心是一座严谨的图书馆,价值在于“存得进、找得到”。但现在,行业已进入 Data Intelligence 时代,数据的价值正在从“被检索”进化为“被计算”,数据中心必须从图书馆进化为日夜轰鸣的 AI 工厂。
在这一背景下,1 月 15 日,XSKY 星辰天合宣布公司战略重心从“信息技术(IT)”全面跨越至“数据智能(Data Intelligence)”,并正式发布全栈 AI 数据方案 AIMesh,通过 MeshFS、MeshSpace、MeshFusion 三大核心产品,分别打破制约 AI 效率的 IO 墙、数据重力墙和内存墙,以中立、解耦的‘数据常青’底座,助力企业构建高效、可控的 AI 工厂。
XSKY 认为,在大模型时代,算法正在同质化,企业真正的差异化竞争优势在于自身拥有的专有数据,这是 AI 时代真正的护城河。出于安全和合规考虑,这些核心数据不能“外溢”到公有云,必须掌握在企业自己手中。
GenAI 与大模型训练和推理属于典型的“数据密集+计算密集”型负载,传统存储协议速率不足、硬件介质 IOPS 与吞吐量有限,加之数据传输通道存在阻力且存算协同不足,导致 AI 训练与推理过程中 GPU 利用率仅 30%-50%,其间横亘着三道无形的墙。
这正是 XSKY 所指出的“IO 墙”——算力吞吐速度远大于存储读写速度,导致计算单元空转;“内存墙”——模型参数量的爆发式增长受限于显存容量的物理限制;“重力墙”——数据体量几何级数增长造成跨域流动成本高企,形成新的数据孤岛。

XSKY AIMesh 数据与内存网
墙是用来打破的,但怎么打破?靠堆硬件只会带来成本的指数级上升。XSKY 给出的答案是架构创新。
AIMesh 是专为 AI 场景打造的全栈 AI 数据方案,定位为面向“AI 工厂”的数据与内存网,由三大核心组件构成:训练数据网 MeshFS、全局对象网 MeshSpace、推理内存网 MeshFusion。通过“三网合一”的创新架构,AIMesh 精准击破 AI 数据处理中的“IO 墙、重力墙、内存墙”三大痛点,实现“快、通、省”的核心价值。
MeshFS 是专为 AI 训练而生的并行文件系统,它结合了 XGFS 的功能全面性与 XSEA 全闪底座的极致性能,以全协议兼容、线性极致性能与企业级智能分层能力,让训练数据极速供给 GPU,彻底解决 I/O 等待导致的算力浪费问题,让数据像电流⼀样极速供给 GPU。实测数据显示,MeshFS 在顺序读带宽上比行业通用方案提升 30%,顺序写带宽超出 50%,彻底解决训练数据供给滞后问题。
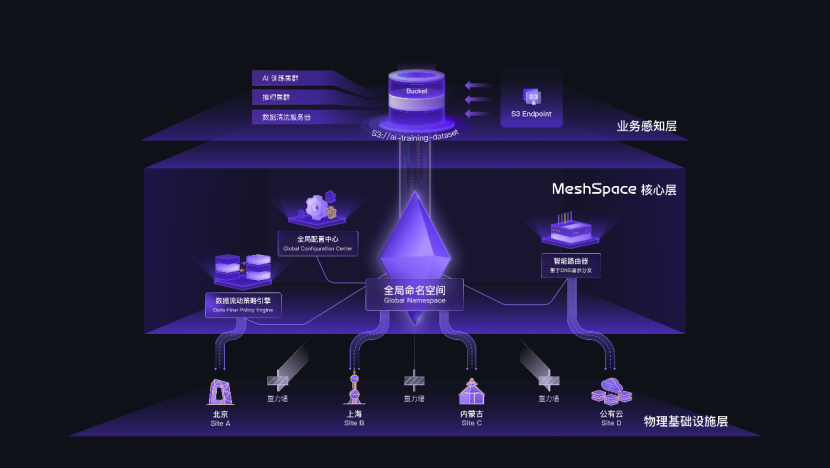
MeshSpace 是面向 EB 级数据的全局非结构化数据平台。通过统一的全局命名空间,MeshSpace 打破了物理集群的边界,实现了跨地域、跨异构存储的数据自由流动与统一纳管,让企业从“单桶千亿”迈向“无限底座”。 升级后的 XScale 引擎迈入“单桶百万 OPS 时代”,单个对象存储桶每秒支持高达一百万对象写入,大块写性能提升近 50%,延迟降低 30%,让 EB 级数据自由流动成为现实。
MeshFusion 是面向 KVCache 的“持久化内存”方案。它将服务器本地 NVMeSSD 转化为 L3 级外部内存,以 1%的硬件成本实现近乎无限的上下文窗口,大幅降低 AI 推理的硬件投入成本。实测显示,其与纯 DRAM 的性能差距控制在 10%以内,高并发场景下吞吐量线性增长,资源受限状态下甚至能实现 20%的性能反超,大幅降低 AI 推理硬件投入成本。
数据显示,目前 XSKY 产品已历经 3000 余家客户严苛场景验证,在金融生产系统、运营商海量并发场景、自动驾驶算力中心等对性能和可靠性要求近乎偏执的领域实现规模化落地。面向未来,XSKY 的使命是“做数据资产的守门人,做 AI 之路的加速器。”




