
12 月 20 日,数据库国际顶会 VLDB2024 公布新一批论文,阿里云旨在实现将 AI 算法在数据库“一键部署”的 PilotScope 中间件相关论文成功入围。同日,阿里云宣布将 PilotScope 全部技术免费开源。
开源地址:https://github.com/alibaba/pilotscope
在 AI 和 DB 之间“搭桥”
AI 和数据库的结合在业内已经探索了很长一段时间,其中 AI for DB 是利用 AI 技术替换数据库里的某些功能,使其性能得到提升。
这个方案需要依赖深度学习或者说大模型。但难点在于,AI 开发和数据库开发基本是两拨人,数据库特别复杂,AI 开发人员很难梳理清楚其中的结构,得到嵌入效果的同时还要保证数据库的稳定性。同时,AI 方法非常多样,数据库底层架构也不尽相同,这导致嵌入的模式、交互需求、具体底层实现方式都各不相同,如果做定制化就会带来很大的时间成本,不利于大规模应用。
“AI 做了很多,DB 做了很多,但中间的桥梁没有人干,这个桥是不通的。我们现在做的事情就是要把这个桥搭建起来。”PilotScope 项目负责人朱鎔说道。
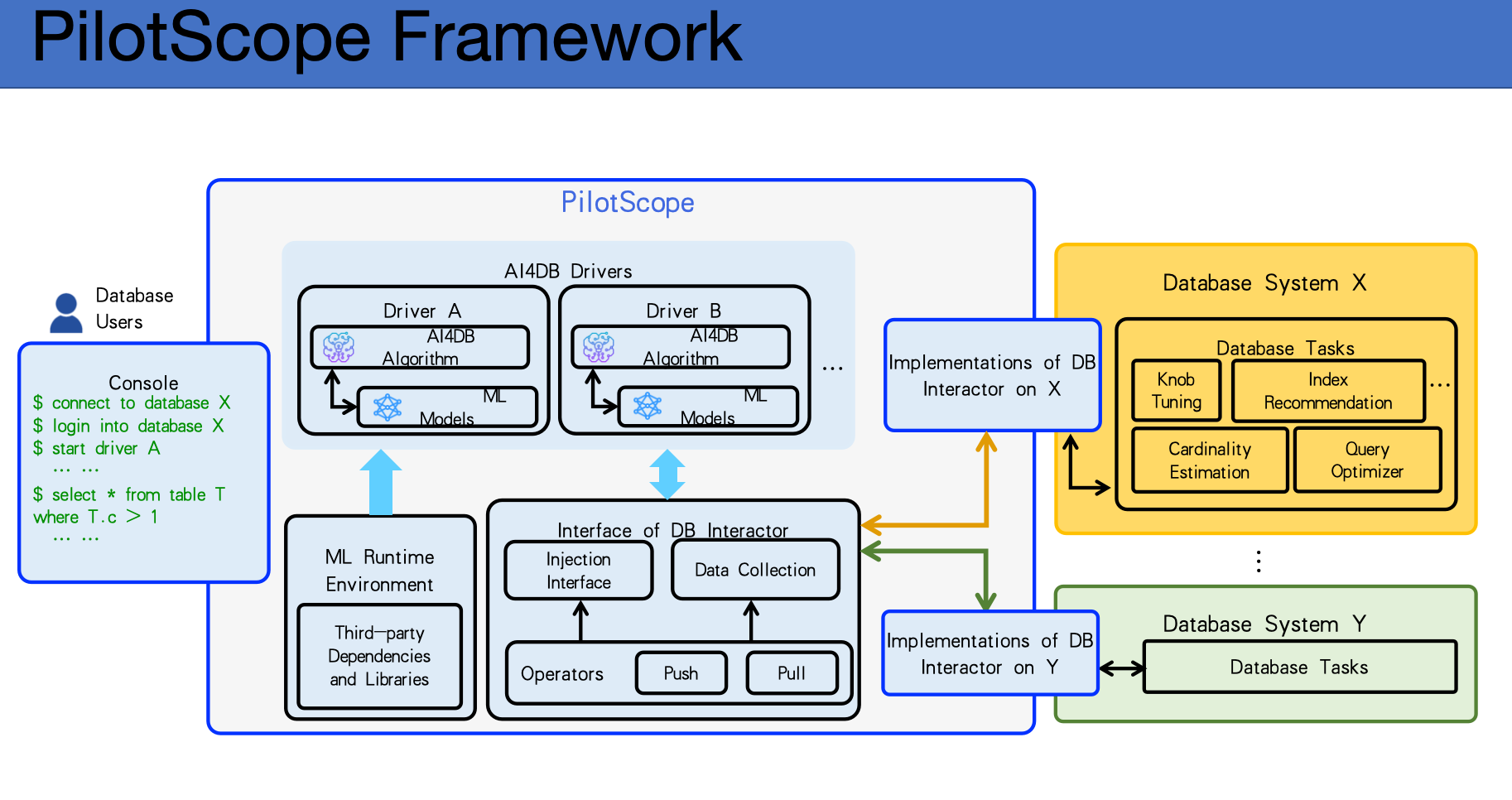
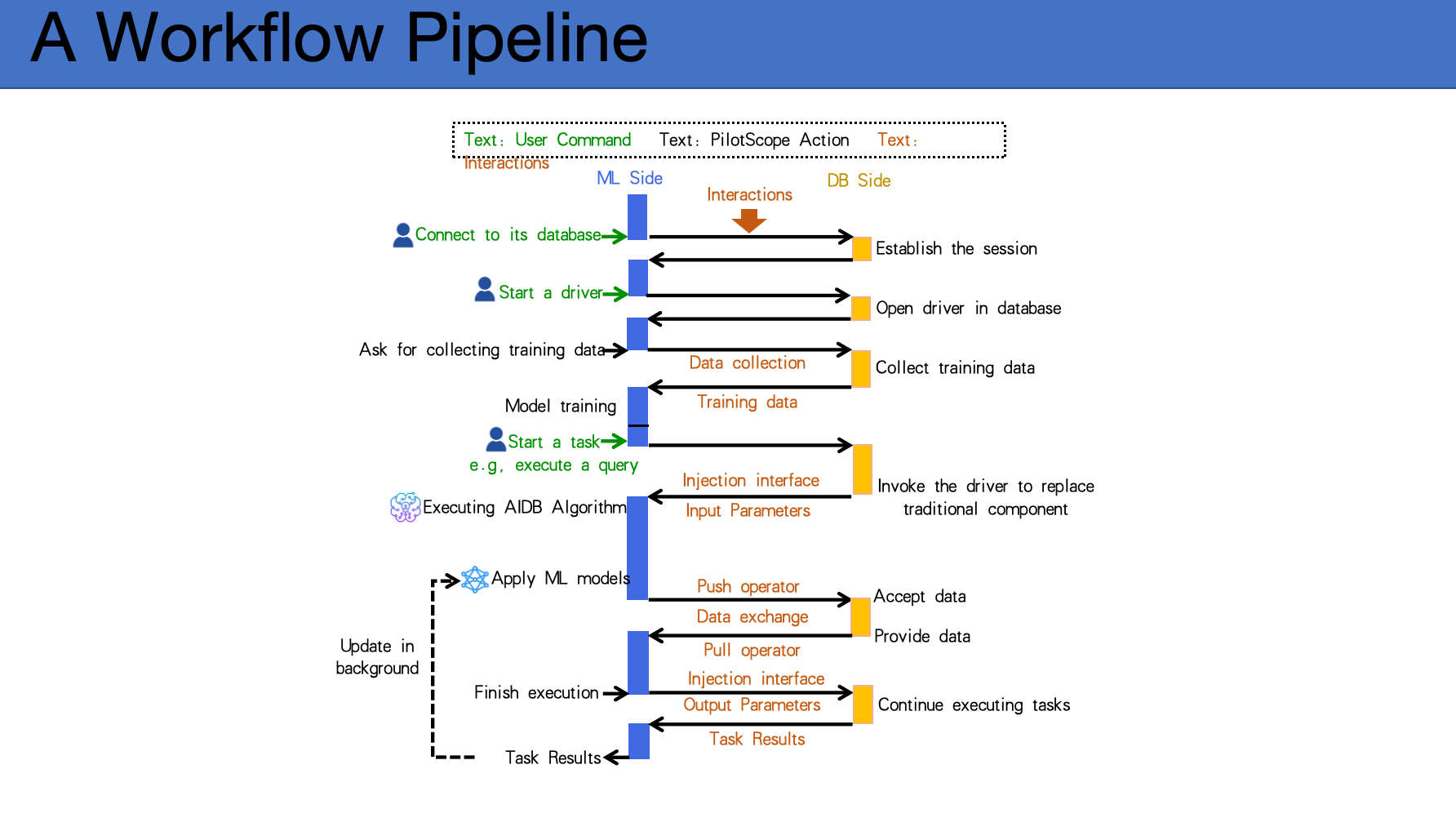
根据朱鎔的介绍,PilotScope 屏蔽不同数据库异构的细节,提供了抽象的、可对 AI 调用的一整套接口。PilotScope 把数据库交互需求及嵌入过程,抽象成了一个个的接口,将最难的底层细节开发部分屏蔽掉,用户可以直接使用,AI 工程师不用关注数据库的细节。
理论上,用户只要支持这个接口,同一个 AI 方法可以支持各种数据库,包括阿里云、微软、AWS 以及 PostgreSQL 等数据库,开发者可以用一个方法、写一次代码就支持所有类型数据库在上面的运行。接口还可以不断扩展,支持不同 AI 方法的需求,同时通过开源的方式来增加支持 AI 算法的多样性。
另外,PilotScope 对 AI 算法的嵌入做了最小的扰动和侵入,不对系统的稳定性造成影响。用户不开启 PilotScope 时可以直接忽略它的存在,而使用 PilotScope 并把某些 AI 算法进行了相应运行后,PilotScope 的检测机制会处理和限定模型的异常输出,对于不正常的结果会直接打断,让数据用原来的模块运行。
据了解,当前 PilotScope 针对参数调优、索引推荐、基数估计、查询优化等数据库主流任务,预置了 10 多种 AI 算法,并完成 PostgreSQL 和 Spark 等两大主流开源数据库的适配打样。根据团队的实验数据,使用 PilotScope 将 AI 算法嵌入数据库,较传统“硬植入”方法,查询优化等任务提速 1-2 倍不等,并且 PilotScope 本身对部署产生的额外代价基本可忽略。
十多人,用了两年做研发
PilotScope 项目是一个深度交叉的领域:要有懂算法的研发人员明确算法具体需求,也要有懂系统的研发将需求真正抽象成系统化设计;除了要有懂 AI 的人,还要有懂数据库的人,了解数据库架构、嵌入模式、与数据库的交互等;在系统设计的人员抽象出系统模式后,还需要开发人员用实际的代码把构思实现出来;AI for DB 是学界想做的算法探索研究,业界想做一些实际落地,两者的综合平衡对满足开源社区是比较重要的。
从上可以看出,这样的研发难度是不小的。朱鎔表示,从有做 PilotScope 的想法开始到今天正式搞出来,十几个人的团队差不多用了两年时间才基本完成。
做 PilotScope 的想法来源于阿里云团队在做 AI for DB 中遇到了测试、部署、落地等各种痛点问题。2021 年夏季之前,团队是点对点地解决,然后发现通用性差、成本高,很难持续下去。之后,团队开始构思这样的一个中间件,在与业务部门沟通、研究了学界最新进展后,才将最终需求确认下来,包括要支持哪些主流方法、支持到什么程度等。
整个 2022 年,团队一直在解决“两端解耦、让桥顺畅”的难题,到了 9 月份左右才开始做真正的系统研发。考虑到两个数据库的适配,团队要做很多细小的修改、打磨、迭代,陆陆续续到今年八九月份才算基本成熟。
据悉,PilotScope 目前已在阿里云内部展开试点应用。朱鎔表示,未来将做一些产业化部署,希望通过这个工具,把 AI for DB 的算法真正大规模的地应用到数据库系统里,提升数据库系统的效率和效果。




