
闫俊杰在商汤敲钟前夕离开,创立了 MiniMax(上海希宇科技),也造就了全球从创立到 IPO 用时最短的 AI 企业——4 年,进程明显快于行业常态。
就在刚刚,1 月 9 日,MiniMax 紧随其后挂牌上市,股票代码 00100。招股书显示,MiniMax 的 ToC 收入已经反超 ToB,这在中国大模型公司中极为罕见。
其招股书还透露了一堆硬核数据,截至 2025 年 9 月 30 日:
累计个人用户:超过 2 亿
覆盖 200+国家和地区
AI 原生产品 MAU:约 2760 万
企业与开发者客户:超过 10 万家
在这次 IPO 中,Mini Max 计划发行约 2540 万股 H 股,开盘价 235.4 港元,截至上午 10:30,股价已飙升超 60%,市值超 820 亿港元(约合人民币 738 亿元)。
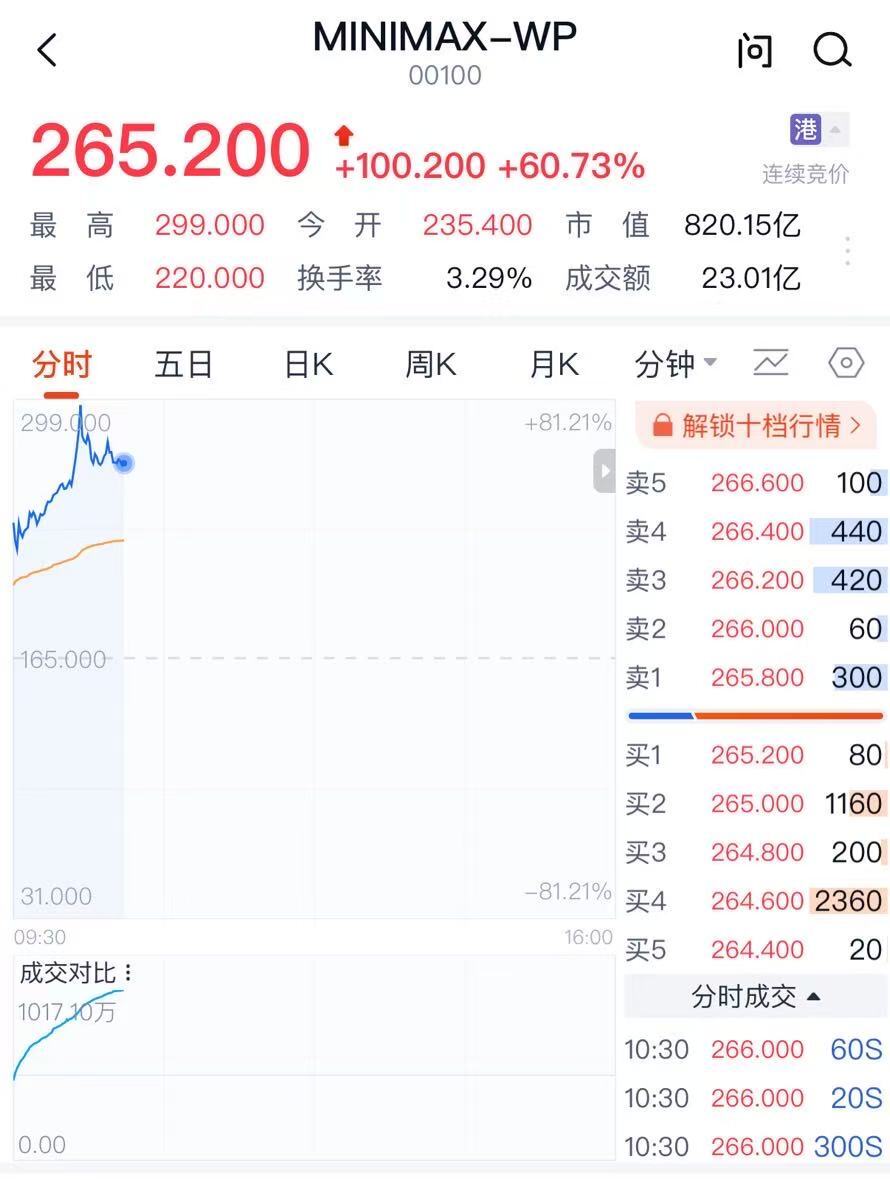
据富途证券数据,MiniMax 此次 IPO 超级火爆,公开发售部分的超额认购倍数高达 1209 倍,投资者通过保证金方式认购的金额累计超过 2533 亿港元。
资本市场为 MiniMax 的技术野心“买单”
在国内近年来涌现的一批 AI 独角兽中,唯二高频更新技术论文、投资开发者生态的,是 MiniMax 和 DeepSeek 背后的深度求索。
闫俊杰曾在各种场合明确表达: MiniMax 是一家技术驱动的公司。据招股书显示,MiniMax 最大的成本就是研发成本,为了在基础模型技术上集中注意力,海外版 App 甚至没有第一时间做英文化。投资人的评价大体也能回归到技术要素,即闫俊杰是一个真正对 AGI 有信仰的人,“他很真”。
这是除市场数据外,MiniMax 市值最明确的支点。
仅在 2025 年,MiniMax 已通过至少两篇公开科研论文系统阐述其大模型架构与推理优化方案,其核心成果包括 MiniMax-01,即基于 Lightning Attention 与 MoE 的超长上下文大模型;以及 MiniMax-M1,即针对推理计算效率进一步优化的模型版本。
相关论文不仅披露了核心机制,还在处理百万级 token 上下文和推理效率上提出可复现技术路径,而非简单参数展示。
回到 2024 年初,在稠密模型仍占主流的背景下,MiniMax 率先推出了中国首个混合专家系统(MoE)大模型 abab6——比 DeepSeek 火出圈 R1 早了约一整年。
在行业仍普遍依赖 Softmax Attention、并为其二次计算复杂度付出高昂算力成本时,MiniMax 开始在模型中大量引入自研的 Lightning Attention(线性注意力)。
具体做法,简单来说就是在每 8 层模型结构中,只保留 1 层传统注意力,其余 7 层改用线性注意力,从而把长上下文推理的计算压力“削薄”。
改动后的直接效果是:模型在面对超长文本、长代码或多轮复杂推理时,不再随着上下文变长而指数级变慢。
这套注意力设计与 MoE 架构叠加后,进一步放大了效率优势,使模型在保持推理能力的前提下,大幅提升了长文本、长代码和复杂任务场景下的计算效率。
相比智谱以 GLM 系列基座模型为核心,在 ToB 与 ToG 侧已跑出较为稳健盈利能力的路径;MiniMax 展现出的是另一种取向:模型更强调产业化落地,已在 ToC 端取得了不错的成果。
围绕自研大模型,MiniMax 已形成包括 MiniMax Agent、海螺 AI、MiniMax 语音、星野以及开放平台在内的产品矩阵。
同时在海外市场亦已有实质进展:其产品和服务已覆盖 200 多个国家和地区,累计触达超过 2.12 亿名个人用户,并服务超过 13 万家海外企业与开发者(包括订阅、API 调用等渠道)。
按 2024 年基于模型的收入计算,MiniMax 是全球第四大 pure-play 大模型技术公司,还是全球第十大大模型公司,覆盖文本、视觉、音频、视频的全模态模型体系。
在上市前的近一年内,MiniMax 完成了从 MoE 架构探索(abab 6 / 6.5)到基础大模型开源(MiniMax-01),再到高级推理模型(MiniMax-M1)的连续迭代。
以 MiniMax-01 系列为例,模型总参数规模已达数千亿量级,但单个 token 实际参与计算的参数仅为几十亿,使得模型可以在控制成本的前提下,原生支持百万级乃至更长的上下文窗口。
在 2025 年 12 月 23 日,MiniMax 还对外发布了最新旗舰级 Coding & Agent 模型 M2.1。
在衡量多语言软件工程能力的 Multi-SWE-bench 测试中,该模型在仅约 10B 激活参数的前提下取得 49.4%的成绩,超越了 Claude Sonnet 4.5 等国际顶尖竞品,拿下全球 SOTA。
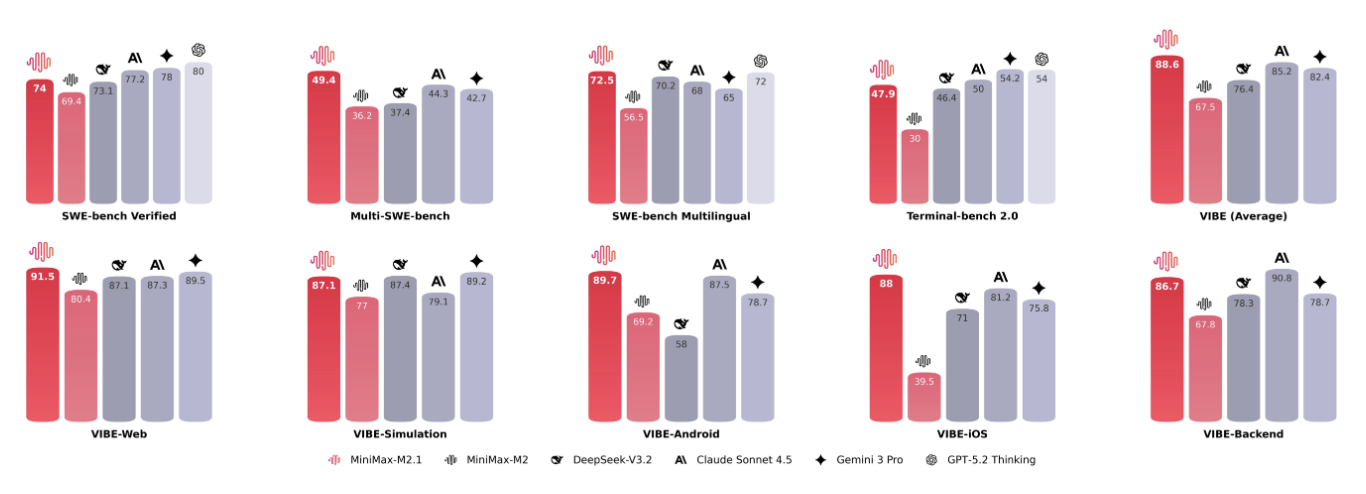
M2.1 要补上的,是此前不少模型在工程能力上的短板——过去的模型在编写简单脚本或前端代码时尚可应付,但一旦进入后端工程、系统架构或底层逻辑层面,表现往往迅速失稳。
这个模型的关键变化在于,其能力边界首次延伸至更完整的后端开发规范。
这些技术实现背后,是一支极其年轻的团队。据每日经济新闻消息,截至 2025 年 9 月底,MiniMax 员工 385 人,平均年龄 29 岁,研发人员占比近 74%,董事会平均年龄 32 岁。
其核心团队由一批来自商汤科技、全球一流高校和顶级科研机构的技术骨干组成,以创始人闫俊杰为首,包括杨斌、周彧聪等联合创始人。
闫俊杰拥有东南大学、本科到中科院自动化所博士及清华博士后背景,曾担任商汤副总裁与研究院副院长。

杨斌具备加拿大博士及 Uber ATG 与国际初创工程经验;周彧聪则是商汤早期算法团队核心成员。
团队多数来自 AI 与深度学习前沿领域,在 NLP、语音、视觉、生成模型等方向拥有丰富经验和多项全球发明专利。
站在年轻团队另一面的,是 AI 投资界的“老炮”们。
早期有阿里、腾讯、红杉中国、高瓴、IDG、云启、米哈游等产业与风投参与;IPO 前夕,阿布扎比投资局、Mirae Asset、Aspex、易方达等长线机构接力。
尤其是阿里,持有的 MiniMax 股权占比还要大于在智谱的比重。连续两场 IPO 后,一场投资界和 AI 创业团队之间的化学反应和默契已经诞生。
上市之后,还需直面 Claude Code 等问题
需要指出的是,由商汤的 ToB/ToG 模式,转到如今的 ToC/ToB 模式,闫俊杰麾下的 MiniMax 还未实现整理盈利;至少想赢得全球 AICoding 市场,绕不开和 Claude Code 的直接竞争。
Claude Code 是一个面向真实软件工程的 Coding / Agent 模型,由 Anthropic 公司推出。该模型的重点是在 AI 生成代码以外,确保模型在工程约束下不失控,堪称 AICoding 神器。近日, Anthropic 宣布,Claude Code 上线仅 6 个月,已经创造了近 10 亿美元年化营收。
从公开信息看,MiniMax 并没有试图直接复刻 Claude Code 的路径,而是选择了另一种更偏效率驱动的技术路线。
MiniMax 在 Lightning Attention + MoE 上的投入,本质上是在解决一个问题:如何在成本可控的前提下,把上下文和工程复杂度拉到“真实软件世界”的尺度。
对于 Coding 模型来说,长上下文不是加分项,而是入场券。 没有足够高效的注意力结构,就无法在真实代码库上长期运行 Agent。
M2.1 针对 Multi-SWE-bench 的表现,某种程度上正是在回应 Claude Code 的“主战场”——不是写某一段代码,而是完成跨语言、跨模块、带验证的软件工程任务。
这意味着 MiniMax 正在补的,并不是单点能力,而是:后端规范、工程一致性,和多语言协作能力,这正是 Claude Code 最难被替代的部分。
MiniMax 若想在全球市场正面竞争,最终比拼的也不会只是 Benchmark,而是 Agent 是否可控、错误是否可解释,以及是否敢被放进 CI / CD 流程。
从招股书来看,MiniMax 的研发投入在过去三年中持续攀升:
2022 年为 1060 万美元,2023 年增至 7000 万美元,2024 年进一步扩大至 1.89 亿美元;截至 2024 年及 2025 年 9 月 30 日止的九个月,研发开支分别达到 1.387 亿美元和 1.803 亿美元。相关投入主要用于模型训练过程中产生的云服务费用。
另外,在头部云厂商和海外独角兽的夹击之下,MiniMax 同时承受着 ToB 与 ToC 两个市场的竞争压力。
模型技术仍在快速演进,这场拼性能、拼效率、拼工程化的技术马拉松还在继续;上市,只是把比赛带入了下一个赛段。
在一次采访中,闫俊杰提到,MiniMax 确实放弃过一些 ToB 订单,是基于对自身交付能力的判断,避免分散注意力。那么,如果 ToB 领域的工程化交付,当下还不是 MiniMax 的“长板”,短期来看,就只剩“技术登顶”一条路能帮 MiniMax 走到终局。
闫俊杰说他在 Dota2 游戏里爱玩小精灵,因为这个英雄实现过从五号位(辅助)转型成为一号位(核心),最终主宰比赛。
目前看来,对于 MiniMax 而言情况类似,能否在 Benchmark 上五转一,保持模型能力长期领先,是上市后走向 AGI 的关键。
参考链接:
https://www1.hkexnews.hk/listedco/listconews/sehk/2025/1231/2025123100026_c.pdf




