
“我真的厌倦了看到那些急于求成的科技初创公司,为了讨好风投而在数据上撒谎,还贴上‘SOTA’的标签。”有网友吐槽。
事情源于高人气开源智能体记忆项目 Mem0 在今年 4 月底发布的一篇论文。论文中,该项目团队为可扩展的、以记忆为核心的架构 Mem0 提出了增强版本,并声称在 LOCOMO 上打败了所有人,其中,Mem0 在 “LLM-as-a-Judge” 指标上相较于 OpenAI 提高了 26%。(论文地址:https://arxiv.org/abs/2504.19413)
当地时间 8 月 13 日, 另一个高人气的智能体记忆框架 MemGPT 的创始团队 Letta AI ,其联合创始人兼 CTO Sarah Wooders 对此公开指控:
几个月前,Mem0 发布了 MemGPT 的基准测试数据,并声称在记忆方面达到了 “SOTA” 水平。
奇怪的是,我完全不知道他们到底是怎么跑这个基准测试的,如果不对 MemGPT 做重大修改,这个测试根本没法完成(他们没有回应我们关于实验具体运行方式的询问)。
arXiv 并不是经过同行评审的平台,所以不幸的是,近年来公司可以随意发布任何他们想要的“研究”结果来做市场营销。
我们很轻松就用一些简单的文件系统工具超过了他们的基准数据——这也说明这个基准测试本身并没有太大意义。
“Mem0 声称他们在 LOCOMO 上打败了所有人,但结果发现他们完全把竞争对手的实现搞砸了。然后还用这些糟糕的结果来证明自己的优势。等到 Letta 和 Zep 按正确方式跑了基准测试后,两者的得分都比 Mem0 的最佳成绩高出 10%。”网友评价道,“这个行业里的‘空气产品’多到离谱。我理解为了拿到风投,企业会夸大功能,但在科研论文里撒谎实在是可悲。”
两个“顶流”崛起
Mem0 和 Letta 的诞生都是为了解决大模型的长期记忆问题。
自 GPT-4 问世以来,大模型一直受限于固定的上下文长度。没有长期记忆,大模型和智能体会面临显著局限:它们会遗忘信息,无法随着时间学习和改进,并且在长时间、复杂的任务中会失去目标。
为此,在 2023 年,加州大学伯克利分校(UC Berkeley)的研究团队提出的一种创新型系统 MemGPT, 借鉴传统操作系统(OS)的理念,引入了智能体的记忆管理,通过构建记忆层级,让智能体主动管理哪些信息保留在即时上下文(核心记忆)中、哪些存储在外部层(对话记忆、归档记忆和外部文件),以便按需检索。这样,智能体可以在固定的上下文窗口内保持无限的记忆容量。
MemGPT 的研究迅速引起社区关注,MemGPT 论文的帖子在 Hacker News 首页上停留了 48 小时,开源后已累积 17.8k stars。
随着开源项目的推进,团队成立了名为 Letta 的公司,持续维护 MemGPT 开源框架,并推动其商业化和工程化落地。原来的 MemGPT 也升级成了 Letta。
这家由伯克利博士生 Sarah Wooders 和 Charles Packer 创立的 AI 初创公司备受期待。Letta 获得了由 Felicis 的 Astasia Myers 领投的 1000 万美元种子资金,本轮估值为 7000 万美元。此外,还得到了人工智能领域一系列天使投资人的支持,其中包括谷歌的 Jeff Dean、Hugging Face 的 Clem Delangue、Runway 的 Cristóbal Valenzuela 和 Anyscale 的 Robert Nishihara 等。
如今,许多智能体系统都实现了 MemGPT 的设计。
Mem0 则是由印度工程师 Taranjeet Singh 和 Deshraj Yadav 成立,源于他们构建开源检索增强生成(RAG) 框架 Embedchain 的经验,该框架下载量超过 200 万次。
根据 YC 的介绍,Singh 曾作为首位增长工程师加入 Khatabook(YC S18),并迅速晋升为高级产品经理。他的软件工程职业生涯始于 Paytm(印度的 PayPal),亲历了其迅速崛起成为家喻户晓的品牌。他开发了一款由 AI 驱动的辅导应用,曾在 Google I/O 上亮相。他与 Deshraj 共同创建了 EvalAI,这是一个开源的 Kaggle 替代平台,GitHub 上获得了 1.6K stars。他还创立了首个 GPT 应用商店,用户规模突破 100 万。
Yadav 则广泛关注人工智能和机器学习基础设施领域,曾领导特斯拉自动驾驶的 AI 平台,支持特斯拉全自动驾驶开发中的大规模训练、模型评估、监控和可观测性。在此之前,Deshraj 在乔治亚理工学院完成硕士论文时创建了开源机器学习平台 EvalAI,并在 CVPR、ECCV、AAAI 等上发表过论文。
Mem0 认为,单纯地扩大模型的上下文窗口只会延缓问题的发生,模型会变得更慢、成本更高,而且仍然会忽略关键细节。团队选择通过一个通用、可扩展的记忆架构来解决问题,Mem0 充当了 AI 应用程序和大模型之间的记忆层,可以动态地从用户对话中提取、整合和检索重要信息。
Mem0 提供轻量级的记忆层 API 和向量检索,开源不到一天就获得了 9.7k stars,如今已累积 38.2k stars。Netflix、Lemonade 和 Rocket Money 等组织已采用 Mem0 来增强其 AI 系统的长期记忆能力。
此外,业内还出现了多种专用工具,将“记忆”作为可插拔的服务,为智能体提供存储与检索信息的能力,常见方式包括使用知识图谱或向量数据库等方案。
单独评估这些记忆工具的有效性极其困难。智能体的记忆质量往往更多取决于底层智能体系统管理上下文和调用工具的能力,而不是记忆工具本身。比如,即便一个搜索工具理论上性能更强,但如果智能体无法有效使用它,例如提示词设计差或训练数据中缺少相关示例,它在记忆场景下的表现也不会好。
因此,记忆工具的评估主要集中在类似 LoCoMo 这样的检索基准测试,而非真正的智能体记忆能力。
LoCoMo 是一个从长对话中进行检索的问答基准,专门用于评估大模型长期对话记忆能力,由 Snap Research 团队推出。每个样本包含两名虚构说话者和一份 AI 生成的带时间戳的对话记录,任务是回答关于说话者或对话中出现的事实问题。
分歧在哪里?
在 4 月底的论文中,Mem0 团队在之前的基础上引入了基于图的记忆表示,来增强关系建模能力。
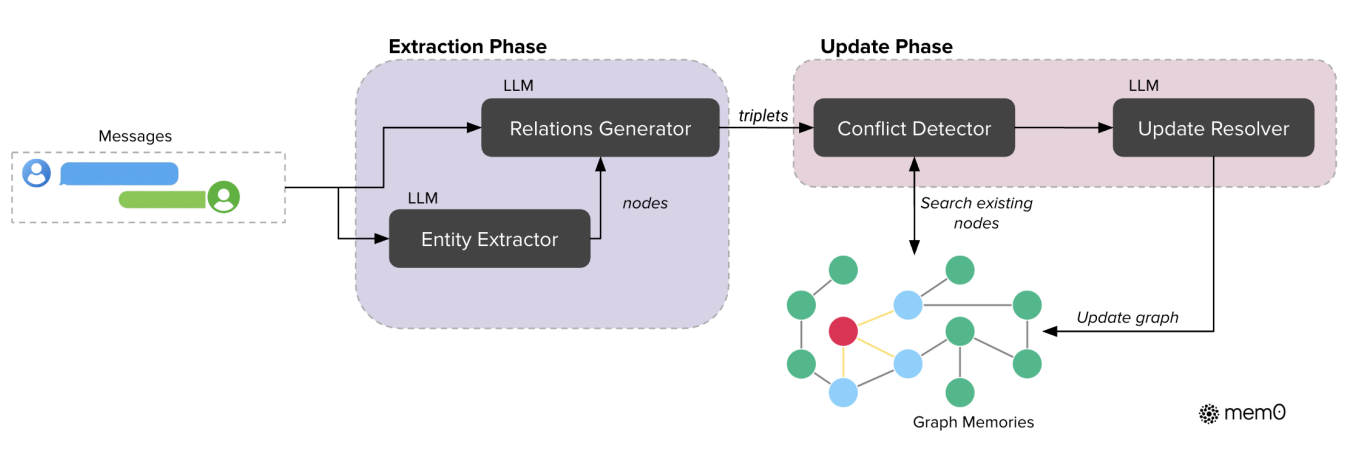
之前,Mem0 的提取阶段处理消息和历史上下文以创建新的记忆;更新阶段则将提取出的记忆与相似的现有记忆进行比对,通过工具调用机制执行相应操作。数据库作为核心存储库,提供处理所需的上下文,并存储更新后的记忆。
引入基于图的记忆后,提取阶段利用大模型将对话消息转换为实体和关系三元组;更新阶段在将新信息整合到已有知识图谱时,采用冲突检测与解决机制。
在实际实现中,Mem0g 使用 Neo4j 作为底层图数据库 ,基于大模型的提取器和更新模块并借助具有函数调用能力的 GPT-4o-mini,从非结构化文本中进行结构化信息提取。通过将基于图的表示与语义嵌入以及基于大模型的信息提取相结合,Mem0 获得了复杂推理所需的结构丰富性和自然语言理解所需的语义灵活性。
在 LOCOMO 基准测试中,Mem0 表示其持续超越六种领先的记忆方法,表现为:响应准确率比 OpenAI 的提升 26% 、延迟比全上下文方法降低 91%、token 使用量节省 90%。
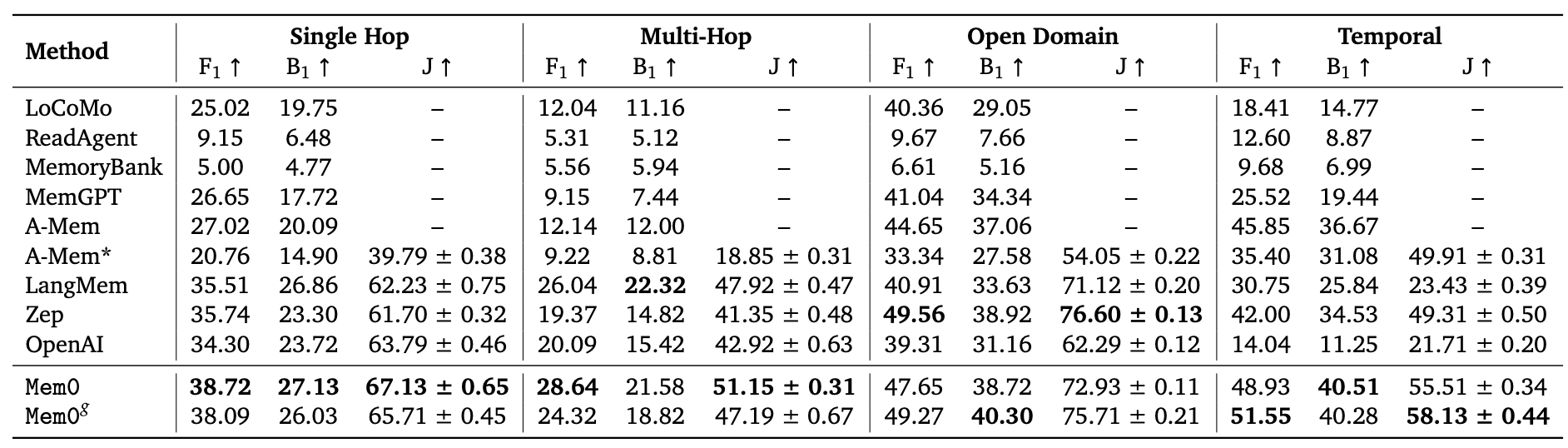
下图是不同记忆方法在 p50 和 p95 的总响应延迟比较,其中包括了大模型推理在内的延迟。
Mem0 团队认为,在 AI 智能体部署中,根据具体推理场景灵活调整记忆结构很重要:
Mem0 的稠密记忆管道擅长快速响应、简单查询,最大限度减少 token 消耗与计算开销;而改进后,Mem0 的结构化图表征能清晰解析复杂关系,支持复杂事件排序和丰富上下文整合,同时不牺牲实际效率。两者合力构建了一个多功能的记忆工具包,能够适应多样的对话需求,并具备大规模部署能力。
6 月时候,Sarah 在 GitHub 上询问 Mem0 是如何获得 MemGPT 的相关数据的,但没有回应。
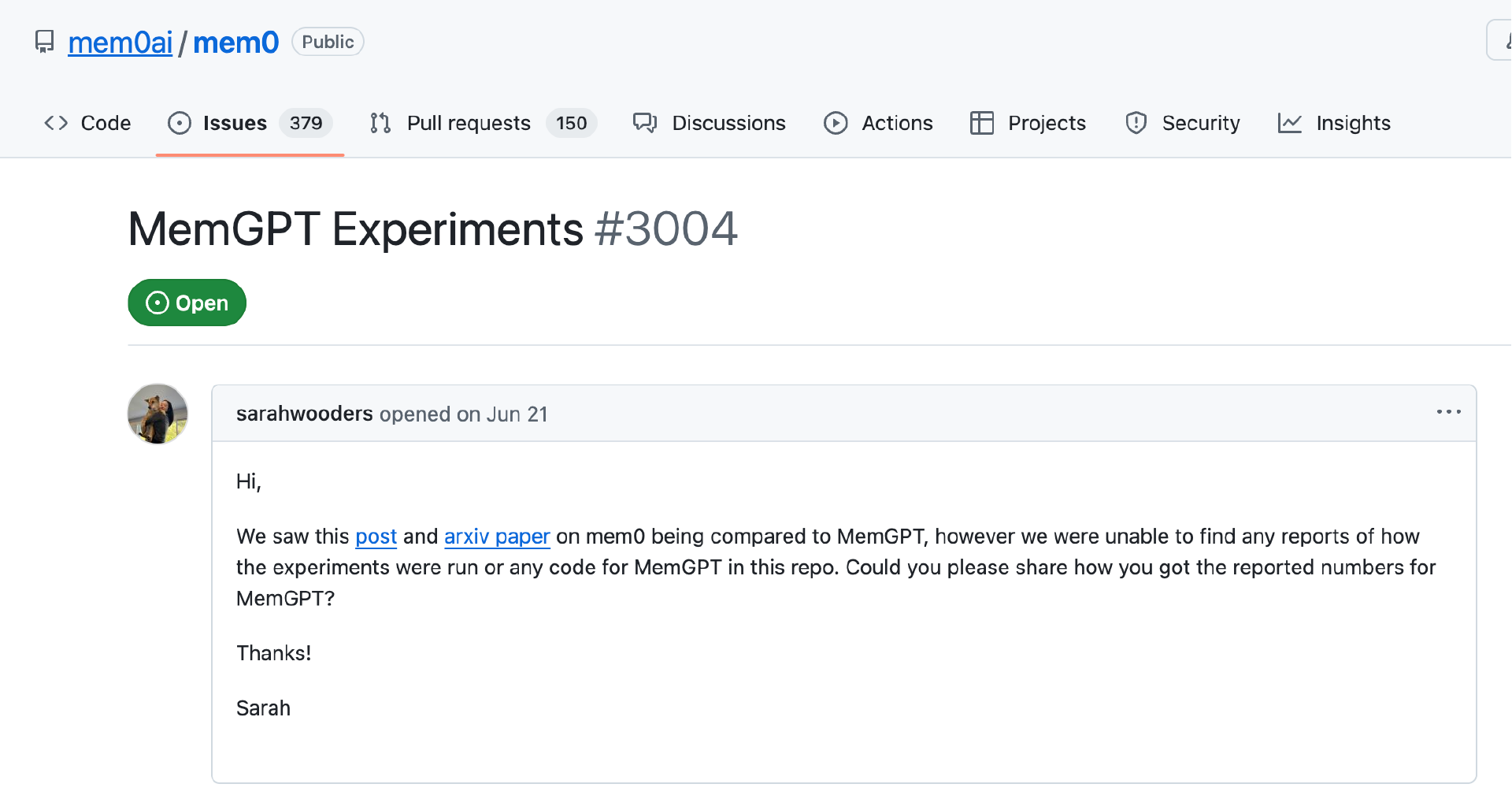
“有一个记忆工具厂商 Mem0 发布了有争议的结果,声称在 LoCoMo 上运行了 MemGPT。但结果令人困惑,因为我们(MemGPT 的原团队)无法找到不进行大规模代码重构就将 LoCoMo 数据灌入 MemGPT/Letta 的方法。Mem0 并未回应我们对其基准测试计算方式的澄清请求,也没有提供支持 LoCoMo 数据回填的修改版 MemGPT 实现。”Letta 表示。
当地时间 8 月 12 日,Letta 发文称,Letta 在 LoCoMo 上仅通过将对话历史存储在文件中(而不是使用专门的记忆或检索工具),就达到了 74.0% 的准确率。这表明:
之前的记忆基准测试可能并不十分有意义;
记忆更多取决于智能体如何管理上下文,而不是所使用的具体检索机制。
Letta 表示,虽然 Letta 本身没有原生方式导入 LoCoMo 那样的对话历史,但其最近为 Letta 智能体(包括 MemGPT 智能体)增加了文件系统功能。“我们好奇,如果只是把 LoCoMo 的对话历史放进一个文件,而不使用任何专用记忆工具,Letta 的表现会如何。”
当文件被挂载到 Letta 智能体后,智能体可以使用以下文件操作工具:
grep
search_files
open
close
对话数据被放进一个文件并上传挂载到智能体中。Letta 会自动解析并嵌入文件内容,以便进行语义(向量)搜索。智能体可以用 search_files 做语义搜索,用 grep 进行文本匹配,再用 answer_question 回答问题。
为了与 MemGPT 的原实验保持一致,Letta 用 GPT-4o mini 作为模型。由于 GPT-4o mini 能力较弱,Letta 让智能体部分自治,通过规则限制其调用工具的模式:必须先调用 search_files 搜索文件,再不断搜索直到决定调用 answer_question 并结束。搜索什么、搜索多少次由智能体自行决定。
“这个简单的智能体在 GPT-4o mini 和最少提示调优的情况下,就在 LoCoMo 上取得了 74.0% 的成绩,明显高于 Mem0 报告的其最佳图记忆版本的 68.5%。”
Letta:能力比工具更重要
Letta 认为,如今的智能体在使用工具方面非常高效,尤其是那些很可能出现在训练数据中的工具,如文件系统操作。因此,很多原本为单跳检索设计的专用记忆工具,还不如直接让智能体自主迭代搜索数据来得有效。
智能体可以生成自己的搜索查询,而不仅仅是检索原始问题,例如将 “How does Calvin stay motivated when faced with setbacks?” 转化为 “Calvin motivation setbacks”,并且智能体可以持续搜索直到找到正确数据。
智能体是否“记住”了某事,取决于它能否在需要时成功检索到正确信息。因此,更重要的是考虑智能体是否能够有效使用检索工具(知道何时以及如何调用),而不是纠结于具体的检索机制(如知识图谱还是向量数据库)。
Letta 还提出,目前智能体能够非常高效地使用文件系统工具,在很大程度上是因为后期优化重点偏向智能体的编码任务。一般来说,越简单的工具越可能出现在智能体的训练数据中,也越容易被有效利用。虽然更复杂的方案(如知识图谱)在特定领域可能有用,但它们可能更难被 大模型(智能体)理解。
“智能体的记忆能力取决于智能体的架构、工具和底层模型。比较智能体框架与记忆工具,就像比较苹果和橘子,因为框架、工具和模型都是可以自由组合的。”Letta 说道。
那如何正确评估智能体记忆能力呢?
Letta 先推荐了自家的 Letta Memory Benchmark(Letta 排行榜) 提供了同类对比(apples-to-apples),在保持框架(目前仅 Letta)和工具不变的情况下,评估不同模型在记忆管理方面的能力。该基准在动态上下文中即时生成记忆交互场景,从而评估智能体记忆,而不仅仅是检索能力(如 LoCoMo)。
然后指出,另一种方法是直接评估智能体在需要记忆的具体任务中的整体表现。例如 Terminal-Bench,测试智能体解决复杂、长时间运行任务的能力。由于任务时间长且需要处理远超上下文窗口的信息,智能体可以利用记忆跟踪任务状态与进度。
最后,Letta 总结道,对于设计良好的智能体,即便是简单的文件系统工具,也足以在 LoCoMo 这样的检索基准中表现优异。
参考链接:




