
电影圈或许也没想到,抢走 2026 年春节档风头的,竟然是 AI。
从年前到年后,全球 AI 领域迎来了一波密集的发布潮,国内外科技巨头与创新企业争相“交卷”,火药味十足。从 Seedance 2.0 到 GLM-5,从 Claude Sonnet 4.6 到 Gemini 3.1 Pro,诸神混战,商量好了似的一起致敬去年 DeepSeek 在春节档的一战成名。
值得玩味的是,这一轮诸神之战,大家更多关注的是如何刷新“天花板”,却很少有人在改变“地板”。换句话说,模型越来越强,但能触达这些能力的人,依然有限——最先进的模型仍然掌握在极少数公司手中,再强的突破,也难以转化为更广泛的创新红利。
在这场春节档混战中,蚂蚁集团也发布了三款模型:百灵家族旗舰即时模型 Ling-2.5-1T、混合线性架构的思考模型 Ring-2.5-1T,以及全模态大模型 Ming-flash-omni-2.0。前两款模型均基于 Ling 2.5 架构,该架构在 Ling 2.0 基础上,采用混合线性注意力机制,大幅提升了长文本处理效率。其中,Ling-2.5-1T 在 token 效率、偏好对齐等维度全面升级;Ring-2.5-1T 主打复杂推理,同时实现 IMO 2025 和 CMO 2025 的金牌水平。Ming-flash-omni-2.0 则基于 Ling-2.0 架构,在视觉理解、语音交互、图像编辑上均实现大幅提升。
相比“更大更强”的发布,这次发布的特殊性在于,开源世界终于又迎来了一款万亿参数推理模型。
在当前以 OpenAI、Google 为代表的闭源大模型体系主导下,万亿级参数模型长期被视为超级实验室的专属资产。要打造一个万亿参数的模型,必须同时跨越算力、数据、工程三道门槛:需要数万张高端 GPU 组成的集群,并且这些 GPU 能够协同工作,还需要海量、高质量、多样化的数据。因此,目前业内开源的万亿级模型寥寥,专注于深度思考的万亿级推理模型更是稀缺。
这也是 Ring-2.5-1T 这款开源模型能够在社区引起广泛讨论的根因之一。最重要的是,蚂蚁愿意在万亿参数这个量级上,持续进行底层的架构创新。这一点尤为关键,意味着团队需要具备迎难而上、勇于探索技术边界的决心和能力。比如这次在架构上,百灵大模型创新引入了混合线性注意力架构,大幅提升推理效率,同时保持训练系统的开放开源,与社区携手攻坚这一工程难题。
万亿模型的意义,不只在于参数本身
当模型规模跨过千亿之后,单纯依赖参数堆叠,已经很难带来线性的能力提升,反而会带来训练成本飙升、推理效率下降等一系列现实问题。行业对此已经形成了效率优先的共识,要么围绕注意力机制进行优化,要么针对 KV Cache 进行压缩,要么在数据质量和训练策略上挖掘突破口……本质上,大家再次来到同一起跑线,寻找新的 Scaling Law。
这也是为什么,这次 Ling 2.5 在架构上的升级能够成为社区讨论的焦点。
去年 10 月,蚂蚁百灵团队在一份长达 58 页的硬核技术报告《Ling 2.0 Technical Report》中,详细介绍了 Ling 2.0 架构。Ling 2.0 采用了统一的 MoE 基础架构,总专家数达 256 个,每次前向传播仅激活 8 个专家和 1 个共享专家,整体激活率约为 3.5%。
Ling 2.5 在 Ling 2.0 架构基础上,引入了混合线性注意力机制,对传统全注意力路径进行重构。具体而言,百灵团队通过增量训练方式,将原有 GQA(Grouped Query Attention)升级为 1:7 的 MLA(Multi-head Latent Attention)与 Lightning Linear Attention 组合结构。一部分注意力层被替换为线性注意力路径,以降低长序列计算复杂度;其余层则通过近似转换为 MLA,在压缩 KV Cache 的同时实现更好的表达能力。在实现层面,还对 QK Norm、Partial RoPE 等关键组件进行了针对性适配,以增强 Ling 2.5 架构在混合注意力架构下的表达能力。
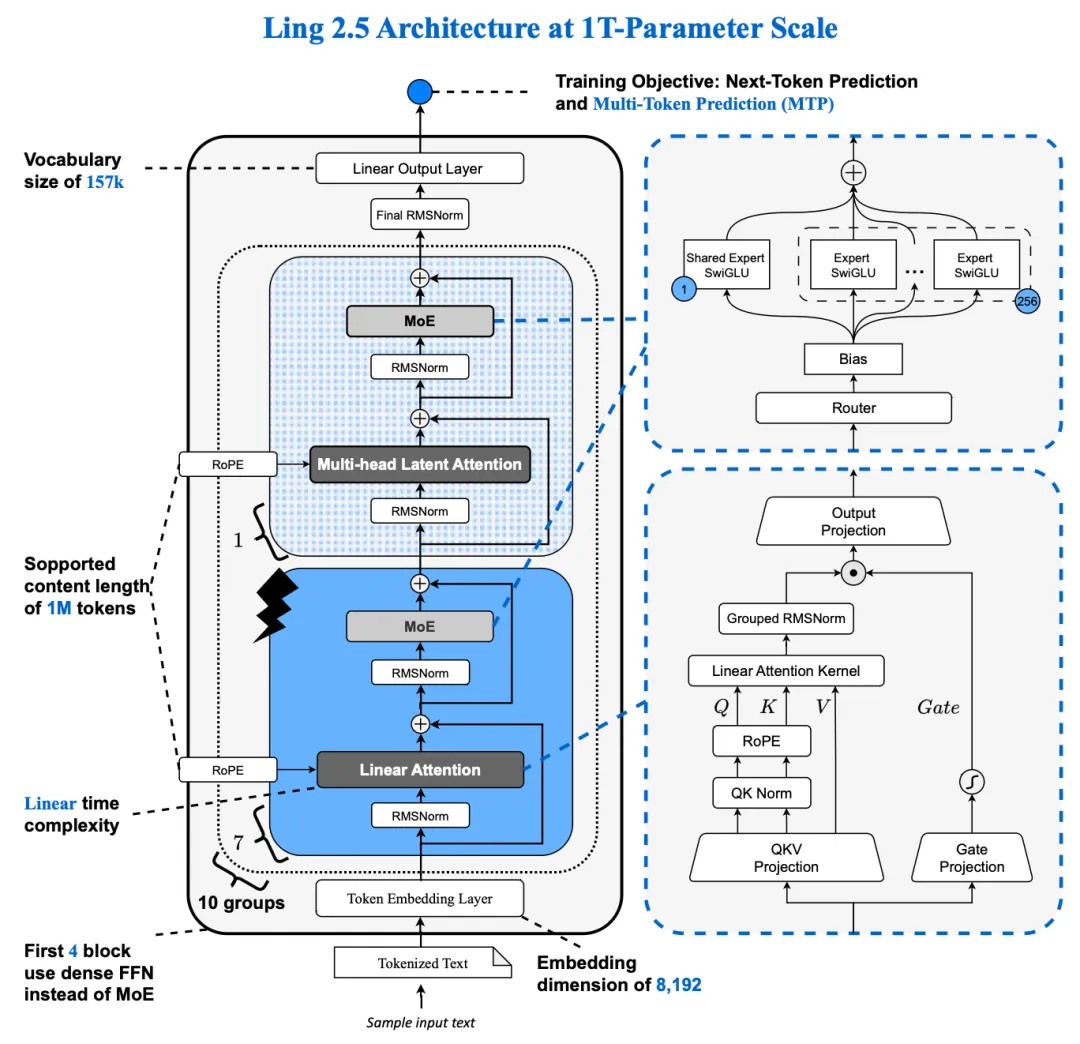
这一设计其实相当务实,同时 兼顾了长序列处理能力与低成本部署的现实要求。 用线性注意力将传统自注意力的时间复杂度从 O(n²) 降低至 O(n),提升模型在长上下文场景中的效率;通过对 KV Cache 的针对性优化,有效降低推理阶段高昂的显存与带宽开销。
在训练阶段,Ling-2.5-1T-base 专门基于约 9T 高质量语料进行了持续预训练,重点强化了知识覆盖、智能体多轮交互和长程执行能力。在此基础上,借助混合线性注意力在长序列上的计算效率,将训练上下文窗口扩展至 256K tokens,并通过 YaRN(Yet another RoPE extensioN)实现最高 1M tokens 的稳定外推。
对于混合线性注意力在超长上下文推理中的效果,此前在社区中仍存在争议。一部分原因在于,线性注意力在理论上可能损失部分全局信息交互能力,此外,其在实际任务中的表现依赖于具体实现与训练策略。
架构改造后,Ling-2.5-1T 的激活参数规模由 51B 提升至 63B,但整体推理效率并未因此下降,相反,其在长文本生成中的吞吐优势甚至会随着生成长度增加而进一步放大。
Ling-2.5-1T 还专门针对超长上下文场景进行了系统性评测。在与采用 MLA 和 DSA 架构的大型即时模型对比中,Ling-2.5-1T 在多项长文本任务中表现出一定优势,验证了混合注意力路径在工程落地中的可行性。不过,与当前领先的闭源模型,如 GPT-5.2、Gemini 3 Pro 相比,仍存在一定差距。百灵团队表示,仍将持续在接下来版本中推进相关能力的进一步提升。
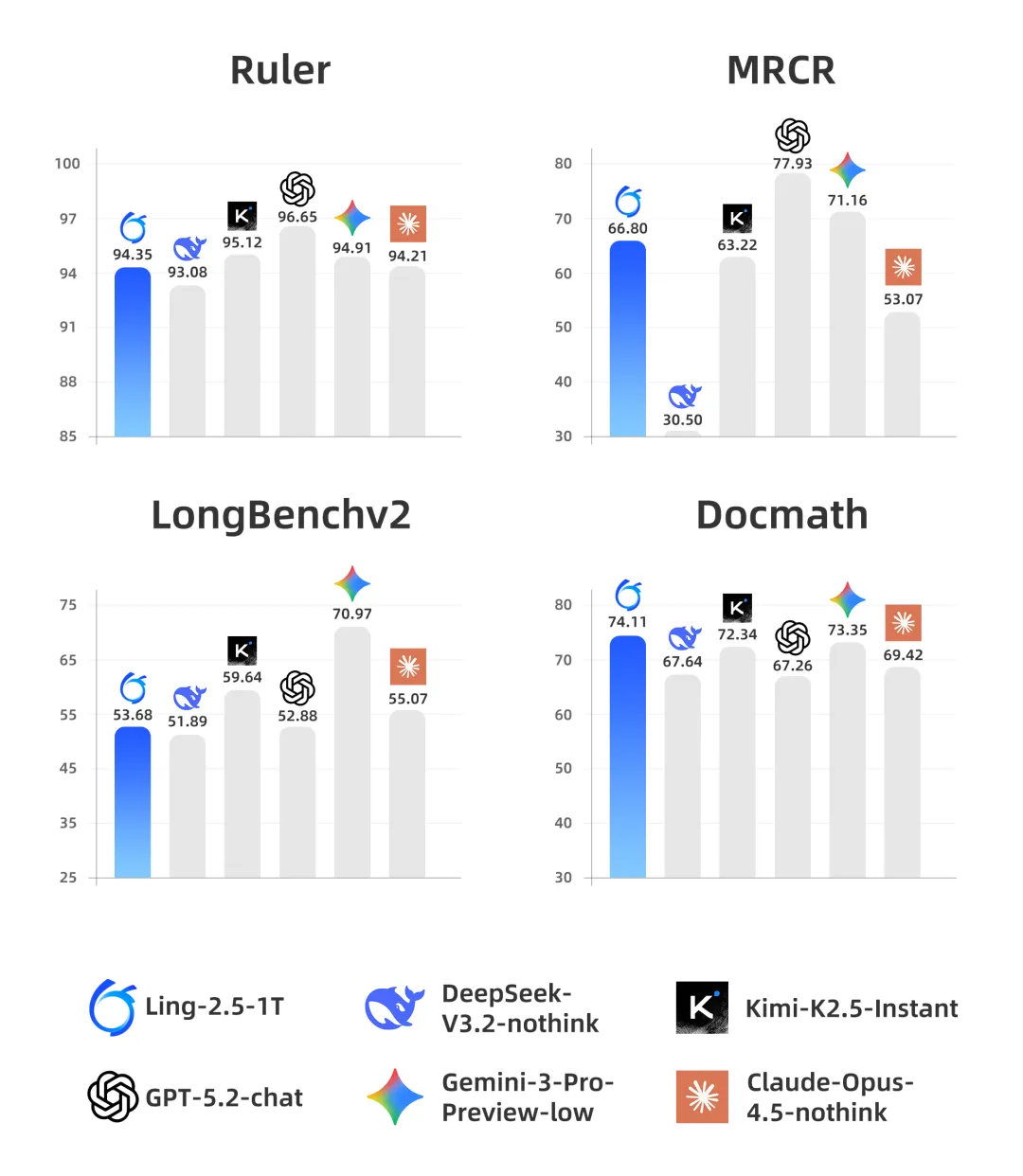
整体而言,从性能表现上来看,这一次的架构改造带来的提升十分明显,尤其是在效率上的提升,直接回应了深度思考模型的长期痛点。
过去,强调多步推理、链式思考的模型,往往意味着高延迟、高成本,在真实的生产环境中落地挑战重重。基于高比例的线性注意力机制,Ring-2.5-1T 在⽣成⻓度超过 32K 时,访存规模降低 10 倍,⽣成吞吐提升 3 倍 +。通过混合线性注意力的设计,让长程推理变得更轻量、更高效。
从这个角度来看,万亿推理模型开源的意义,早已不在于参数规模本身,而在于是否找到一条可以持续扩展的路径。而混合线性注意力所代表的,正是一种面向长期演进的架构思路。以新的架构范式,将模型能力真正转化为可落地的价值。某种程度上,这也体现了蚂蚁百灵团队的价值取向——长期主义,以及对 inclusion 的关注。通过架构创新,让更多开发者、更多场景有机会参与进来。
奥数金牌水平的模型,如何深度思考?
架构上的升级使得 Ring-2.5-1T 和 Ling-2.5-1T 在多个权威基准评测上均有不错的表现。Ling-2.5-1T 作为百灵家族当前最强大的即时模型,其与主流的大尺寸即时模型相比,在复杂推理、 指令遵循能力具有明显优势。
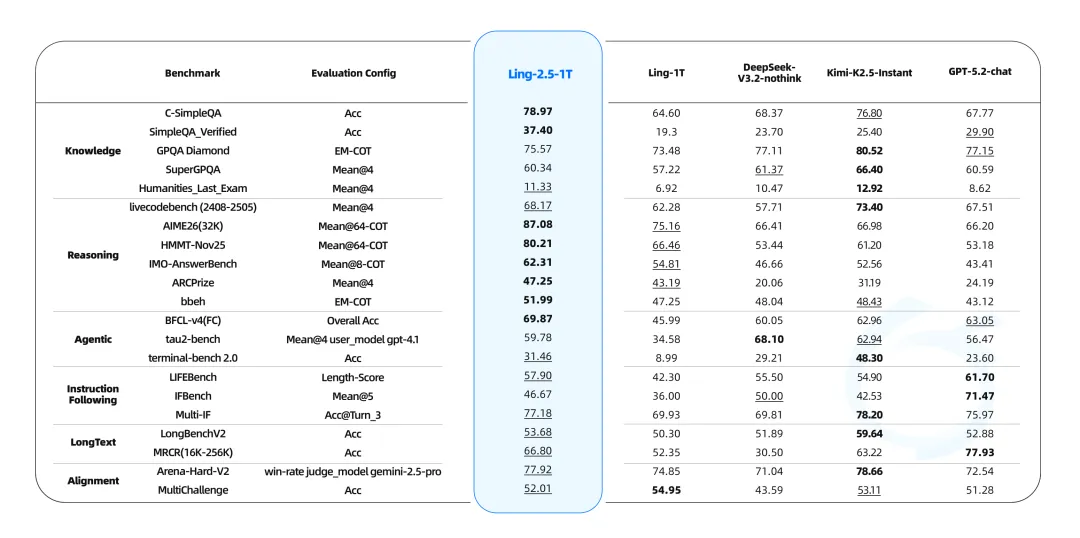
Ring-2.5-1T 则在数学、代码、逻辑等高难推理任务和智能体搜索、软件工程、工具调用等长程任务执行上均达到了开源领先水平。并且在 IMO 2025(满分 42 分)中,Ring-2.5-1T 获得 35 分,达到金牌水平;在 CMO 2025(满分 126 分)中取得 105 分,显著高于金牌线(78 分)及国家集训队入选线(87 分)。(Ring-2.5-1T 在 IMO 2025 与 CMO 2025 中的详细解答:https://github.com/inclusionAI/Ring-V2.5/tree/main/examples)
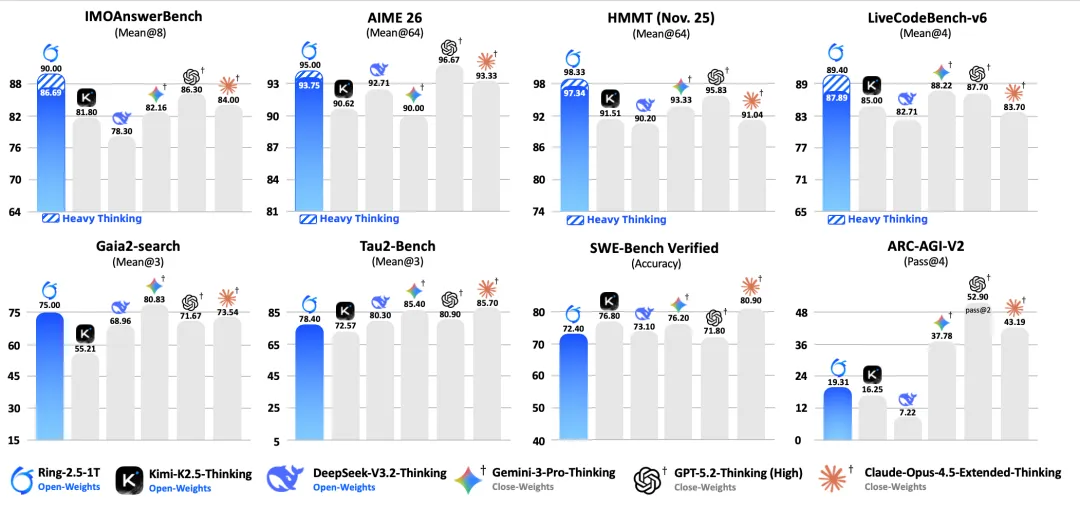
在实际应用中,这两款模型表现如何?
在一句话生成 PPT 测试中,Ling-2.5-1T 根据一句指令,快速完成了从内容组织到 HTML 代码生成的全过程,直接输出了一份可用于演示的 PPT 页面,并且给出了详细的参考文献。在可视化、专业知识梳理上,均有不错的表现。
Prompt: 帮我用 HTML 生成一个介绍 LLM 基本原理的 PPT,画风要有科技感,术语严谨学术性强,16:9 的页面。
Ring-2.5-1T 则更擅长深度思考,能根据指令自动开发一个微型版操作系统(TinyOS),完成从任务拆解、模块设计到代码生成与调试的完整闭环。
这种深度思考能力,决定了模型能否真正跨越复杂问题的门槛。在 Ring-2.5-1T 中,一个关键变化是 dense reward 机制(稠密奖励),这也是支撑 Ring-2.5-1T 能够实现奥数金牌水平深度思考的关键。
百灵团队将 dense reward 引入到了 RLVR 的框架中,让模型的训练目标从给出正确结果,转向对每个推理步骤或关键节点都给予反馈。这种训练方式带来最直接的变化就是,相当于给模型思考过程加上了监督员,确保每一步推理都能合乎逻辑,减少漏洞,从而提升模型在复杂推理任务中的稳定性。
简单来说,dense reward 的核心理念就是关注过程而非仅仅是结果。当思考过程本身成为优化目标,大模型才真正具备了接近人类思考方式的能力。这也是蚂蚁这几款开源模型,能够在春节档杀出重围的根因之一。
万亿推理模型的开源,只是蚂蚁 AGI 布局中的一环
从行业经验来看,开源已经被证明是一条有效的生态路径,但如果仅仅把蚂蚁在这次春节档的动作理解为“开源策略”,明显低估了其背后的意图。因为蚂蚁正在做的,从来不只是开放模型本身,而是试图开放一整套围绕大模型运行的系统能力——包括训练、推理、强化学习乃至应用构建在内的完整技术体系。
支撑百灵大模型体系的,是蚂蚁集团自研的高性能强化学习系统 ASystem,其针对万亿参数模型的显存管理和训推权重交换问题做了精细的优化,实现了单机显存碎片秒级回收、权重零冗余交换,把大规模 RL 训练稳定跑成日常。
围绕这一底座,百灵团队在过去一年中持续推进核心能力的开源。自去年 11 月起,陆续推出「ASystem 系统开源」系列技术解析,并同步开放了一系列关键组件,包括高性能强化学习权重交换框架 Awex、用于提升通信效率的 NCCL 扩展库 AMem NCCL-Plugin、面向强化学习的高性能状态数据管理系统 AState、强化学习训练框架 AReaL,以及 Agentic RL 环境系统 AEnvironment。百灵团队希望将这套融合了技术深度与工程实践的系统性探索回馈社区,提供模型与系统协同设计的实践经验与参考路径。
当行业都在热热闹闹地重新定义模型“天花板”时,百灵团队紧盯“地板”,向更多开发者构建一条面向未来的技术路径:不仅提供模型能力,还提供构建模型的能力。 百灵团队表示,未来还将陆续开源 ASystem 的其他核心 RL 组件,进一步完善开源强化学习训练生态。表面上看,这似乎脱离了金融科技公司的叙事主线,实际上,这只是蚂蚁集团在 AGI 布局中的冰山一角。
作为最早将 AI 技术大规模应用于金融场景的公司之一,蚂蚁集团在过去多年来一直致力于 AI 研究,并将机器学习应用于欺诈检测、信用评估和服务自动化等领域。2023 年,随着生成式 AI 兴起,集团明确提出“AI First”战略,将 AI 置于公司发展的核心位置,并与“支付宝双飞轮”“加速全球化”共同构成新的增长引擎。
在模型层,百灵大模型系列持续演进,覆盖语言、多模态与推理能力;在应用层,则围绕自身优势场景,在金融、健康与生活服务等领域探索 AI 原生产品形态,通过“AI 管家”等形式,将模型能力转化为可感知的用户价值。
2025 年是蚂蚁 AGI 的重要分野。这一年,百灵大模型的迭代节奏明显加快,技术路线也逐渐清晰,从大语言模型 Ling,到多模态模型 Ming,再到强调深度思考能力的 Ring,构建起一套覆盖理解、生成与推理的模型体系。
在应用层,蚂蚁也在加速探索。去年 11 月,发布了“灵光”AI 助手,将多模态生成能力与实际使用场景结合,支持包括 3D、音视频、图表、动画与地图在内的多种信息形式输出,尝试构建一种更加直观的人机交互方式。
去年 12 月升级的 AI 健康助手——阿福,则集成健康问答、健康陪伴、健康服务三大功能模块,支持语音、文字、图片交互及“AI 诊室”主动追问模式,曾连续三天登顶 App Store 应用下载总榜第一。在 2 月 16 日的马年央视春晚舞台上,蚂蚁阿福出现在小品《血压计》中,成为全民关注热点。
当模型能力、系统基础设施与应用场景开始协同演进时,一套完整的 AI 体系正在逐步成型。而蚂蚁,也早已完成从金融科技公司到 AI 核心玩家的转身。从数据库、隐私计算,再到智能体、万亿参数模型,蚂蚁源源不断地将核心能力向社区释放,试图在更大范围内建立技术共识与生态协同。对蚂蚁而言,开源更像是一种组织能力与创新模式,驱动团队在开放中进化,在探索中打磨能力。通过持续的开放与协同,构建一个能够自我生长的技术生态。
从这个角度来看,这次万亿参数推理模型的开放,并不只是一次技术展示,更像是其在 AGI 路径上的一次阶段性落子——将能力交给开发者,让生态参与进来,也为下一个智能十年写下自己的注脚。当模型、算力与场景通过开放机制形成正循环时,技术的演进速度将不再由单一组织决定,而是由整个生态共同驱动。谁能够在这一过程中构建起稳定的开放体系,谁就更有可能在下一阶段占据主动权。而蚂蚁的选择,正是押注在这样一条更长期、更复杂,但也更具确定性的路径之上。




