
最近,第十届中国大学生程序设计竞赛(China Collegiate Programming Contest,CCPC)举行。 字节 Seed 作为赞助商,携 Seed-Thinking 非正式参与了最后的比赛。结果却让很多人比较意外,Seed-Thinking 只做出了一道签到题(指专门设计得比较简单,让选手“打卡”或“热身”的题目)。据悉,CCPC final 赛的题目数量在 10~13 题不等,这次题目信息还未公布。
随后,Seed 的工作人员在知乎上也发布了一些其他模型的参赛结果:
Seed-Thinking,1 题(C 题)
o3/o4,都是 1 题(G 题)
Gemini 2.5 pro,1 题(C 题)
DeepSeek R1,0 题
根据参赛选手的描述,这些难题中,C 题和 G 题相对来说比较偏向于是“签到题”的。OpenAI、谷歌、DeepSeek 参赛成绩也是比较让人意外的。
“根据之前的 codeforces rating 分数,假如那些大模型是人类选手,应该不止这个成绩。”小红书博主“AI 实话实说”评价道。codeforces rating 是一个人长期参加某在线比赛的平均表现,大家通常会根据这个分数判断一个人的水平并且对应到某个比赛的表现。
“有可靠消息表明,出题人并没有专门出题要让大模型做不出来。”该博主对 AI 前线表示。
“人类不参与任何一道题的思考”
“实际上,从赛前的评估结果看,我个人对这个结果是有一些预期的。出于评估目的,非 XCPC 选手出身的我,在赛前把前几年的 CCPC-final 差不多全看了一遍,大体对 CCPC-final 的难度有了个预估:挺难的,对我和模型而言都挺难的。”该员工表示。
据其介绍,字节 Seed 团队的参赛方式是:人类不参与任何一道题的思考,纯让模型自己试。现场的三位参赛人员担任“驾驶员+修理工”的角色。
对于很多人关于“人类选手场上偷摸做题”的担忧,该员工也表示“这个可能性比较低”,“因为几位同事虽然现在都是资深的 LLM 工程师,但是算法竞赛水平可能还没到能在本场 CCPC 上砍瓜切菜的程度。同时,这场比赛也没有明显的签到题。另外,模型在 codeforces 上的表现其实已经超过了三位同事不少。”
“至于最终成绩,只能说是很悲壮了。赛中的几个小时,场外的大伙一直不停打地在刷新榜单,可惜直到封榜都没能看到 model AC 掉任何一题。好在最后场上的同事非常神勇地判断出了哪道题最签一点,保住了 Al 的最后一点面子。”该工作人员说道。
此外,该工作人员也表示这次本次比赛题目相较去年会新一些,如果是去年的 CCPC final,模型表现会更好一些。
不过,评论区也有网友指出,“Gemini 2.5 pro 非常变态,只要你把你的 io 和 debug 信息给它,迭代几次就成功了,我用这个打了好几次 cf 了,基本上你只要会给提示大部分题都能 AC。测下来人为辅助给一些基本提示的话,AI 能写出 70%的题。关键在怎么给 AI 提示,AI 的自我纠错已经非常厉害了。”
“感觉大模型技能树确实有点不一样。”字节工作人员还在知乎上提到。
包括 Seed-Thinking 在内,字节 Seed 进行测试的大模型在架构上也有一定的代表性:
Seed-Thinking-v1.5 采用 MoE 架构,包含 200B 总参数与 20B 激活参数。研究团队在强化学习训练中整合了 STEM 问题、代码任务、逻辑推理和非推理数据,针对可验证和不可验证的问题使用不同的奖励建模方法。
o3 采用“推理专用架构”,专注于解决复杂问题。它拥有 128 层 Transformer,并集成了专门的符号推理引擎,使其在数学处理和逻辑推理方面达到人类水平的精度。o4-mini 基于“效率优化架构”构建,通过量化技术和动态算力分配,将参数量缩减至 o3 的五分之一,同时保持了相近的性能。它在实时任务中处理速度比 o3 提升了 3.2 倍。
Gemini 2.5 Pro 建立在原生多模态架构上,支持文本、图像、音频及代码等多源输入,并支持百万 Token 上下文窗口,使其能够处理超大文档、视频脚本与完整代码库。虽然没有详细技术介绍,但其技术突破在于强化学习、思维链提示和后训练。
DeepSeek R1 由一个嵌入层、61 个 Transformer 层以及输出阶段的多个预测头构成,直接将强化学习应用于基础模型,无需依赖监督微调 (SFT) 作为初始步骤,使模型能够探索解决复杂问题的思路链。
单就在上述模型在 CCPC final 比赛中的表现,不同模型架构并未表现出特别大的差异。
暴露出大模型短板
“这其实说明大模型在做算法题上其实是很有短板的”上述博主说道,“这件事 OpenAI 在他们拿 ioi 金牌的那篇论文没有说。”
在今年 2 月,OpenAI 发布了关于推理模型在竞技编程中应用的研究论文,其中,在 IOI 2024 国际信息学奥林匹克竞赛的测试中,o3 拿到了 395.64 分,达成金牌成就。
OpenAI 得出结论是:通过扩展强化学习规模,不依赖特定人工设计的 test-time 策略,是推动 AI 在推理类任务(如竞赛编程)中达到最先进水平的一条可靠路径。
不过,该博主解释称,OpenAI 的 o3 可以拿到 IOI 金牌,原因是团队针对算法题进行了专门的 agentic 训练,即允许模型使用工具(比如 python 解释器)来运行自己的代码,观察代码的输出并修改代码,而字节的这次比赛是非 agentic 的。
算法题都要通过编程解决。有些题的做法非常独特和需要创意,可能和模型见过以前的任何题目,乃至题目的组合都不一样。在这种前提下,模型就很难做好,这与人不会解题的原因类似。
另外,该博主指出,比较标准比赛的奖项是衡量大模型能力的有效方式,但在算法题领域用学历来衡量很不合理。因为厉害的选手都是很小就学,最厉害的选手大概是高中生,而不专门练习的博士生可能打不过小学生。
推理模式表现更好
就在 4 月份,微软首席软件工程师 Alex Svetkin,将 Anthropic、DeepSeek、Google、xAI、OpenAI 的 7 个大模型在两组 LeetCode 算法题上进行了基准测试:一组是广为人知的“经典”题目;另一组是最新发布的“未见过”题目,目的是看这些打模型解决新型算法问题的能力是否有所提升。具体测试结果如下:
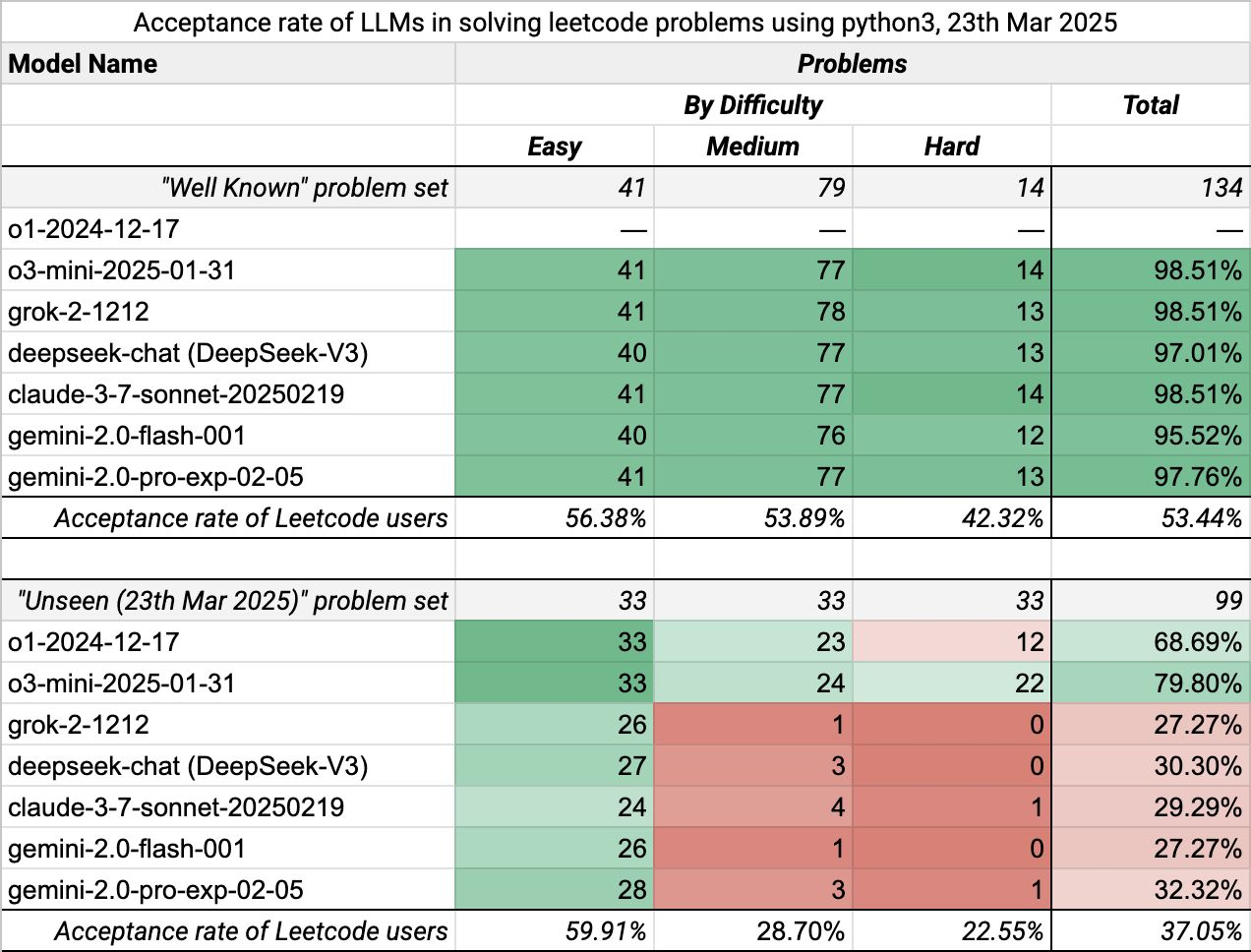
(上:经典题目测试结果;下:“未见过”题目测试结果)
结果表明,所有模型在经典题目上的通过率都非常高。为了节省时间和调用额度,Svetkin 没有测试表现更强的模型或衍生版本(例如启用推理能力的 Claude 3.7 Sonnet、DeepSeek R1、Gemini 2.5 Pro 和 OpenAI O1),“因为它们的结果几乎可以预见”。
在“未见过”的题目上,测试结果在两个方面表现出了显著差异:
对所有模型而言,“未见过”题目的通过率都更低,尤其在中等和困难题上尤为明显。
启用了“推理”或“思考”模式的模型在各个难度级别的题目上表现更好,不过具体的提升幅度因模型而异。
对于经典题目通过率显著更高的原因,Svetkin 表示这是因为这些题目及其标准解法很可能出现在模型的训练数据中,模型只需复现已知的正确答案即可。在面对新的中等和困难题目时,人类的通过率也明显低于在“已知”题集上的表现。这种差异较难量化,它并不一定意味着新题“更难”。
所有启用了“推理”模式的模型在性能上都明显优于其基础版本。最重要的是,其中一些模型已经能够解决相当比例的中等和困难题目。在所有启用“推理”模式的模型中,o3-mini 表现最佳。值得指出的是,o3-mini 是专门为解决竞赛编程问题而训练的。
“不过,我不会断言哪个模型更适合解算法题,因为这高度依赖于 token 预算,同时还要综合考虑推理延迟与使用成本。”Svetkin 说道。
参考链接:
https://www.zhihu.com/question/1903142349388886822
https://hackernoon.com/testing-llms-on-solving-leetcode-problems-in-2025




