
2025 年的拉斯维加斯,亚马逊云科技 re:Invent 现场依旧人潮汹涌——超过 6 万名参会者线下到场,近 200 万人在线收看主题演讲。
但在这层喧嚣之下,会场里明显多了一种氛围:大家比起兴奋,更关注具备自主行动力的 Agent。
前两年的大会主旋律还是“云 + 大模型”的宏大叙事,今年更聚焦在“Agent”,并且把焦点拉回到了三个具体的问题:算力和成本怎么算,基础设施怎么重构,以及最关键的——Agent 该怎么被快速开发出来并跑进生产环境。
在首日的主题演讲中,亚马逊云科技首席执行官 Matt Garman 提出,未来每家公司、每一个可以想象的领域里,都将运行数十亿个 Agent。这是一个足够宏大的判断。但对台下负责预算和落地的技术管理者来说,眼前的问题要现实得多:
从一个在 PC 上跑得很顺的 Demo,到一个能接住真实业务、经得住高并发、算得清成本的生产级 Agent,中间还有多长的一段路?
在今年的主题演讲上,亚马逊云科技把这一现实问题提升到了“范式变革”的层面:正如二十年前亚马逊云科技通过推动“云原生(Cloud Native)”改变了软件开发方式,如今,它希望在“Agentic AI”上,完成一次类似级别的重构。
演讲中提到,光有“模型能力”已经远远不够,真正挡在企业面前的,是如何构建可长期托付的“企业级 Agent”。对大多数团队来说,从概念验证(PoC)走向生产环境,往往会面临着“编排能力、安全性、扩展性”三大隐形高墙。
为了解决这一问题,亚马逊云科技的策略是从单纯的“模型超市”转型为提供完整的“Agentic AI 基础设施”,旨在让 Agent 的开发像搭积木一样高效。
亚马逊云科技 Agentic AI 副总裁 Swami Sivasubramanian 进一步拆解了这一路径。他没有只停留在发布几个新功能,而是展示了一套全栈技术改造:例如开发者用的 SDK 和平台级服务(如 Amazon Bedrock AgentCore)、模型定制与训练的路径,包括由亚马逊云科技自身验证过的规范、策略和自动推理支撑的安全机制。
他的目标很明确:通过标准化的 Agent 架构,将企业构建智能体的周期,从“作坊式”的数月摸索,压缩到工业化生产的“周”甚至“天”。

这也标志着亚马逊云科技正在引领新一轮的 Agent 开发范式转移:从提供算力、存储等基础资源的“云底座”,转变为提供一套可复用、工业化的“Agent 生产流水线”。
对企业来说,接下来的竞争重点,也正从“有没有 Agent”,转向“谁能更快、更稳地把 Agent 造出来、用起来”。
给 Agent 开发做减法——让“从想法到原型”变成几天之内的事
Swami 提到,当下有两件事在同时发生。
第一,“谁能构建 Agent”的用户主体,正在被改写。过去,要做一个像样的系统,必须熟练掌握编程语言,还要记住一堆 API 和参数。现在,越来越多的工作开始交给 Agent 完成,会把需求说清楚的人,正变成新的“构建者”。
第二,“要花多久构建”的现状,也在被改写。过去要几年才能做出来的系统,现在有机会在几个月内上线;过去需要几个月打磨的功能,正在被压缩到几周,甚至几天。从想法到产生业务影响,这条路在变短,而 Agent 就是这条路径上的加速器。
在这样的前提下,Swami 把一个 Agent 拆成了三块:模型,是“大脑”,负责推理、规划和决策;代码,是“身份和角色”,定义它能做什么、如何做决定;工具,是“手脚”,包括各类 API、数据库、浏览器、解释器等执行手段。
Agent 开发慢,往往卡在这三者的配合上。模型不够可靠,开发者就只能写大量状态机和决策树,把流程一条条写死,为各种可能情况提前设定工作流;工具调用和状态切换需要硬编码,一旦出现意料之外的情况,发生在 AI Agents 之间的复杂协作就会失效。久而久之,代码库被一层层“胶水代码”包裹,既难维护,也很难在新场景中复用。
这次发布的 Amazon Strands Agents SDK,就是在这一层做“减法”。
Swami 提到,亚马逊最初是为自家产品做 Agent,做到一半停下来问了自己一句话:如果从头设计一套面向未来的 Agents SDK,它应该是什么样?
他们的答案很直接:尽量把控制流交给模型,让模型结合上下文和可用工具自行规划步骤;开发者只需要定义好三样东西——用哪颗“大脑”(模型)、这个 Agent 是谁(代码里的身份和能力)、它可以动用哪些工具。
Amazon Strands Agents SDK 采用的就是这种“模型驱动”的方式:不再要求开发者提前写完所有状态机和工作流,而是让 Agent 在运行时根据目标和环境做决策、动态调用工具。

效果很具体:在内部的 Agent 系统中,他们删掉了成千上万行与工具选择、状态协调相关的胶水代码,开发效率提升,Agent 的准确性和可维护性也更好。
验证之后,亚马逊决定将 Amazon Strands Agents SDK 开源。短短几个月内,Amazon Strands Agents SDK 下载量超过 500 万,社区贡献了大量扩展能力:支持更多模型、多 Agent 协同、TypeScript 和边缘设备等。
这说明,Amazon Strands Agents SDK 确实踩中了开发者的痛点,它让“写一个 Agent”变得更加简单。
不过,写得快只是第一步。在 Swami 看来,真正拖慢项目的,还有一整段“从 PC 到生产环境”的路:Demo 很好看,业务部门却迟迟等不到真正上生产的版本。
几乎每家公司里,都有人在本地机上跑各种 Agent Demo,但领导层更关心的是:为什么这些东西进不了生产?什么时候能跑在 VPC 里,连上真实系统?这叫作“概念验证困境”。
概念验证要跨过去,需要解决五个问题:基础设施能否从 0 扩展到几千个并发会话;会话上下文和跨会话记忆怎么管理;身份与访问控制如何保证安全;如何与内部 API、数据库以及第三方服务安全集成;出现问题时,日志、监控和调试从哪里入手。
过去,要解决这些问题,往往得先拉起一个团队,花上几周甚至更久搭一套“Agent 环境”。
Amazon Bedrock AgentCore 的作用,就是把这部分也做成标准件。它不是再造一个新的框架,而是一套专门为 Agent 准备的工具箱:管理运行时、弹性扩缩容、会话隔离、会话记忆、身份和访问控制,以及与各类服务之间的安全集成。

以身份管理为例,如果从零开始,你可能要花几周时间处理认证协议、安全规范和各种边缘场景;而用 Amazon Bedrock AgentCore Identity,只需要几行代码,就能让 Agent 代表用户,在亚马逊云科技和 Slack、Zoom 等第三方应用之间安全地执行操作。
当控制流交给模型、基础设施变成标准组件之后,从“想做一个 Agent”到“让它在生产环境里跑起来”,就不必再是几周甚至几个月的排期,而有机会被压缩到“几天”这个量级。
而这只是亚马逊“Agent 天级构建”的起点,接下来更重要的是 Agent 的“大脑”——模型。
给模型训练做减法——让“训练”更快更实用
Swami 在演讲里说得很直接:今天搭一个 Agent 已经不算难,难的是让它跑得又快又省,还要贴合各自行业。
虽然,现在的大型语言模型足够“聪明”,能多步推理,会用工具,也能处理意外情况。但一应用到具体业务上,很容易遇到三个现实约束:
延迟:用户和客服都等不了几秒钟的“转圈”;规模:大促、旺季一来,系统是稳住还是排队;迭代速度:发现问题到修正上线,是按季度还是按天算。
因此,在他看来,问题已经不在于“要不要定制模型”,而是两个更具体的问题:能多快开始定制,能多快看到效果。
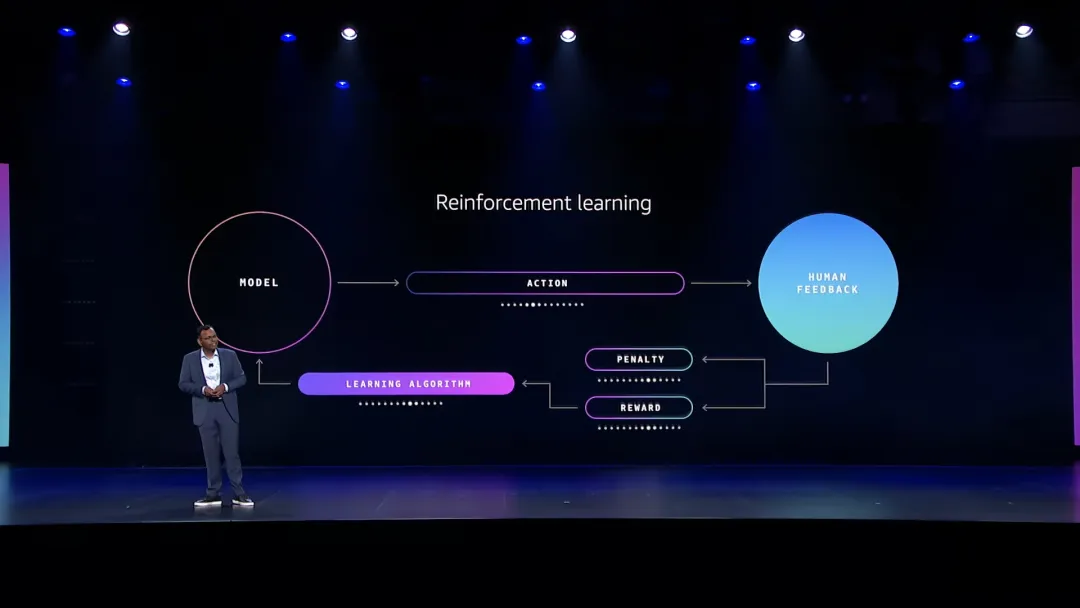
这也是为什么,强化学习在模型训练领域的定位始终是关键。过去,强化学习一直被视作“高配玩法”——模型通过行动结果学习,做好事有奖励,犯错就被“扣分”。原来有两种路径:
基于人类反馈的强化学习(RLHF):给标注人员看同一个问题的多个回答,让人类按好坏排序,再训练出一个“奖励模型”,像人一样打分。之后 Agent 每执行一次动作,这个奖励模型都会给它打分,模型在不断试错中学会什么是好的回答。
基于 AI 反馈的强化学习(RLAIF):把“打分的人”换成大模型,让它来评估和排序回答。这种方式比人工更快、更便宜、更一致,适合有明确对错,或可以清晰表达的场景,还能奖励“好的过程”,而不只是正确答案,让模型学会更有条理的思考路径。
这两种方式听上去很理想,但现实是:要在生产环境里做一轮像样的强化学习训练,你需要奖励建模、策略优化、反馈整合方面的专家,还得搭起一整套分布式训练基础设施。从立项到见效,6~12 个月很常见,而且结果未必稳定,对大多数公司来说,这就是“劝退”。
把这些复杂性和成本都藏在平台里,让普通开发团队也用得起这套技术,亚马逊云科技发布了 Amazon Bedrock Reinforcement Fine-Tuning(RFT),它很简单:无须强化学习专家团队,也能有强化学习带来的效果。

用 RFT 时,开发者只需要做三件事:选一个基础模型;指向在 Amazon Bedrock 中积累的日志,让模型看到真实的 Agent 交互;选择一个奖励函数。最简单的方式,是用一个大模型做“评审”,判断哪种回答更好。剩下的工作,包括奖励模型如何训练、策略如何优化、训练如何调度,都由 Amazon Bedrock 在后台完成。
在多数用例中,这种方式能在易用性和效果之间取得平衡,让基础模型在特定任务上的准确率明显提升,而无需拉起一个半年周期的大项目。换句话说,原本只属于少数玩家的强化学习,被压缩成了一个任何团队都能尝试的“提效选项”。
此外,很多客户的开发诉求则更直接:律师事务所希望模型真正掌握自己多年积累的案例与推理模式;医疗服务提供者希望模型能基于特定患者结果来学习;金融机构需要的是对本国市场、监管环境有深刻理解的模型。他们希望完全掌控定制技术和数据,而不仅仅是在通用模型上“加一层强化微调”。
亚马逊云科技在 2024 年推出的 Amazon SageMaker AI,其实就是在围绕这个问题布局,到了 2025 亚马逊云科技 re:Invent,又发布了 Amazon SageMaker AI Serverless Model Customization,它能为开发者提供两种体验:一种是自助式体验,适合喜欢掌控全局的开发者;一种是 Agent 驱动,只需自然语言描述用例,AI Agent 会推荐微调技术、生成数据集、设置 Serverless 训练、评估模型效果。
这意味着,原本需要数月完成工作,如今只需要几天,全程由懂最佳实践的 Agent 指导完成,并且支持最新的强化学习技术,包括 RLAIF、RLVR 和 DPO。
当然,还有一类客户的目标更高。他们要的不是“懂一点行业术语”的模型,而是一个从底层就理解该行业的基础模型。
以药物研发公司为例,他们需要模型真正理解分子结构、蛋白质相互作用、特定治疗领域的临床数据。对这种需求来说,只在通用模型上做微调是不够的——就像随手教一个通用翻译几句医学词汇,和从头培养一位医疗翻译,是两件完全不同的事。
按照传统路径,要获得这样的基础模型,几乎只能从零开始训练:组建顶级机器学习团队;承担数百万美元的算力成本和数月的训练周期;还要接受“辛苦训练完,效果未必理想”的不确定性。这也是为什么,定制基础模型长期以来几乎只属于大厂和头部 AI 创企。
亚马逊云科技针对这些痛点推出的 Amazon Nova Forge,试图改写的就是这条“起跑线”。
它允许你在 Amazon Nova 的训练过程中访问中间检查点:不必从头开始,而是在训练中段接手;用自有数据与亚马逊云科技精选数据混合继续训练;既继承 Amazon Nova 的通用智能、安全性和可靠性,又在后半段注入你所在行业的知识和工作流理解。
最终可以得到的是一个既“前沿”,又“贴身”的模型:对通用世界有足够理解;对特定行业有深入洞察;而你不需要承担完整训练生命周期的全部成本和工程复杂度。
从“训练效率”的角度看,这是更高一层的减法:不是简单把每一次训练跑得更快,而是改变了从哪一步开始训练。
给 Agent 工程化做减法——高效解决 Agent“信任”与“可靠”难题
目前,大多数 AI Agent 系统仍主要依赖大模型的统计式推理能力来做决策。在聊天、写稿这类轻量场景里问题不大,但一旦涉及资金、生产环境或安全责任,这种不确定性就变成核心风险。
Swami 的比喻也很直白:给 Agent 开通信用卡的权限,就像把信用卡交给一个青少年——他确实能帮你办不少事,也可能哪天突然买了一匹小马,或一仓库零食。
根源在于,大模型的本性是概率式产生“幻觉”,容易在复杂规则和法律条文面前犯错、推理路径不透明,很难像读程序那样逐行检查,以及容易被刻意设计的输入“带跑偏”。
面对这种不确定性,企业通常会“过度补偿”:一种是事事人工复核,层层加签,流程越拉越长,Agent 的价值被拆得所剩无几;另一种是把 Agent 写成脚本,用硬编码规则把它绑住,牺牲掉 Agent 自主性。
两条路的共同结果,是信任问题变成效率问题:想上线一个 Agent,难点不在能不能做出来,而在审批和风控始终不敢放行,“快速落地”无从谈起。
要打破这个局面,亚马逊云科技提出了先换一种思路:不再靠加人、加流程来换安全感,而是把“能做什么、不能做什么”变成可以形式化验证的约束。
几年前,亚马逊云科技内部第一个 AI Agent 原型(也就是今天 Kiro CLI 的前身),就暴露过一个关键问题:模型会出现“API 调用幻觉”——调用一个看似合理、但根本不存在的接口。
为了解决这一问题,他们当时把科学家、机器学习工程师和自动推理团队拉到一起,最后确定了一条路径:把大模型(神经网络)和形式化推理(符号逻辑)结合,做成所谓的“神经符号 AI”。
这个背后的“自动推理”能力,简单说,就是用数理逻辑穷尽程序可能的执行路径,去回答一个问题:在所有这些路径里,有没有一种会违反规则?
事实上,这套技术,亚马逊云科技已经使用了十多年:内部用来分析虚拟化、加密、身份认证、网络系统;对外则以 Amazon IAM Access Analyzer、Amazon VPC Reachability Analyzer、Amazon S3 Block Public Access 等工具的形式提供;在其他行业,它也被用在航空航天、铁路信号、工业控制等“不允许出错”的系统中。
目前,这套“老技术”将系统性地接入 Agent 领域:用自动推理验证 Agent 输出的程序和指令,有问题就打回;用推理系统的结果反向训练模型,让模型更懂约束和逻辑;更重要的是,把验证器直接嵌入 Agent 的推理和执行链路,让约束从一开始就是系统的一部分,而不是上线前的“补丁”。
在这样的框架下,“信任”的含义也被改写了:不再是“我觉得它大概没问题”,而是“在这个边界内,它不会越线”。
信任之外,另一个同样关键的问题是可靠性——不仅要“不越界”,还要“每次都能干好”。
许多企业已经有过教训:Agent 在 Demo 里表现亮眼,第一天上线也没问题,但到了第 N 次,或环境稍一变化,就开始犯糊涂。这种不稳定同样会拖慢上线节奏,让团队迟迟不敢把真正关键的流程交出去。
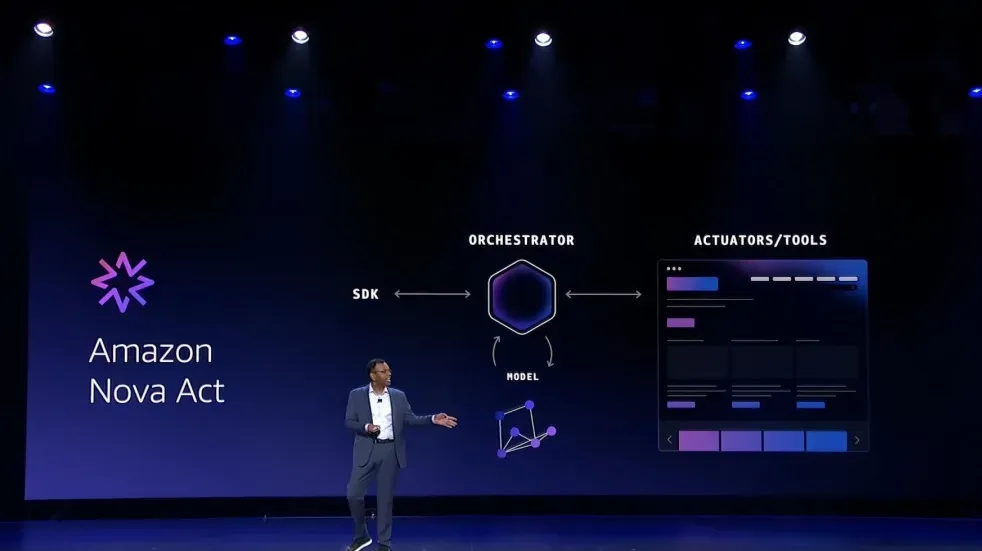
亚马逊云科技对这个问题的回答是 Amazon Nova Act。它专门负责自动化各种带界面的企业工作流程——填表、改记录、发请求、走审批,看上去像 RPA 的升级版,但思路完全不同:
传统 RPA 靠录脚本,一变脚本就失效;通用大模型虽然能理解界面变化,但协调和纠错复杂,一旦走错分支,很容易“一错到底”。Amazon Nova Act 则从一开始就把模型、协调器、执行器和 SDK 当成一个整体,在训练阶段就紧密打包,而不是各自为战。
更关键的是,它的可靠性不是靠“没出过大事”的经验判断,而是通过强化学习与训练环境练出来的。
亚马逊云科技已经为常见企业流程搭建了大量仿真环境(RLGyms):CRM、人力资源、工单、审批系统……只要有 UI,就可以复制出一个“训练版”。
在这些环境里,Amazon Nova Act 的 Agent 反复跑任务:每次完整走完流程会被奖励;出错则受到惩罚。数百个环境、数千条并行工作流,让它在不影响真实系统的前提下,把“常见业务流程”跑熟、跑稳。
最终呈现出来的,是可以量化的结果:在它瞄准的企业工作流场景中,Amazon Nova Act 的可靠性可以达到约 90%;在 RealBench、ScreenSpot 等基准测试上,Amazon Nova Act 的表现与该领域最好的模型相当甚至更好。
当信任与可靠性都被拉进这样的工程框架里,Agent 项目从“技术可行”到“敢上线、敢托付”的最后一公里,才真正有了“提速”空间。
可以说,这一届 re:Invent,亚马逊云科技试图证明的是:当 Agent 开发、模型训练、工程化这三道关都完成了“减法”,企业就有能力把智能体的构建周期,从按“月”计算,实实在在压缩到可以按“天”来衡量——而且不是停留在实验室里。
而可以预见的是,未来围绕 Agent 的竞争,也会从“谁先喊出口号”,真正转向“谁能更快、更稳地把 Agent 推向生产”。在这一场新的竞赛里,谁能率先过滤掉“噪音”,把时间和资源押在可验证、可交付的能力上,谁也就更有机会抓住这轮生产力升级的窗口。
2025 亚马逊云科技 re:Invent 中国行即将启幕!12 月 18 日开始,北京、上海、深圳、成都四城线下巡演及线上专场将同步开启,无论你是云计算新手还是技术老兵,都将从高阶演讲、实战内容、技术分享和专家互动中受益。点击【链接】立即注册,抢占席位,把握 Agentic AI 时代的新机遇!




