
5 月 20 日,面壁智能小钢炮 MiniCPM 系列推出端侧多模态模型 MiniCPM-Llama3-V 2.5 并开源。据悉,该模型且支持 30+ 多种语言,并且具有以下特性:
最强端侧多模态综合性能:超越多模态巨无霸 Gemini Pro 、GPT-4V;
OCR 能力 SOTA!9 倍像素更清晰,难图长图长文本精准识别;
图像编码快 150 倍!首次端侧系统级多模态加速。
MiniCPM-Llama3-V 2.5 开源地址:
https://github.com/OpenBMB/MiniCPM-V
MiniCPM 系列开源地址:
https://github.com/OpenBMB/MiniCPM
Hugging Face 下载地址:
https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5
8 B 端侧模型,超越 GPT-4V、Gemini Pro
MiniCPM-Llama3-V 2.5 以 8B 端侧模型参数量级,贡献了惊艳的 OCR(光学字符识别)SOTA 成绩,以及端侧模型中的最佳多模态综合成绩与幻觉能力水平。

模型雷达图
在综合评测权威平台 OpenCompass 上,MiniCPM-Llama3-V 2.5 以小博大,综合性能超越多模态“巨无霸” GPT-4V 和 Gemini Pro。
OCR(光学字符识别)是多模态大模型最重要的能力之一,也是考察多模态识别与推理能力的硬核指标。新一代 MiniCPM-Llama3-V 2.5 在 OCR 综合能⼒权威榜单 OCRBench 上,越级超越了 GPT-4o、GPT-4V、Claude 3V Opus、Gemini Pro 等标杆模型,实现了性能 SOTA。
在评估多模态大模型性能可靠性的重要指标——幻觉能力上,MiniCPM-Llama3-V 2.5 在 Object HalBench 榜单上超越了 GPT-4V 等众多模型(注:目标幻觉率应为 0)。
在旨在评估多模态模型的基本现实世界空间理解能力的 RealWorldQA 榜单上,MiniCPM-Llama3-V 2.5 再次超越 GPT-4V 和 Gemini Pro,这对 8B 模型而言难能可贵。
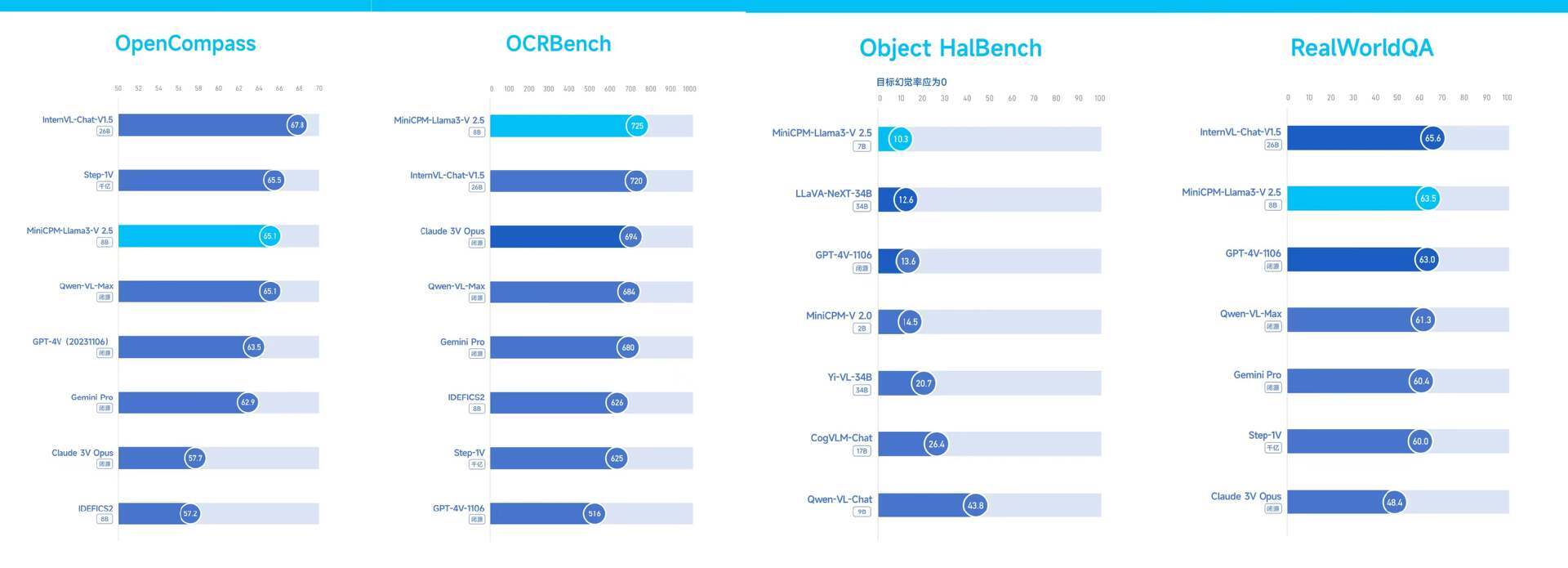
榜单成绩:OpenCompass | OCRBench | Object HalBench | RealWorldQA
快 150 倍!首次端侧系统级多模态加速
面壁智能首次进行端侧系统加速,MiniCPM-Llama3-V 2.5 目前已可以高效部署在手机端。
在图像编码方面,面壁首次整合 NPU 和 CPU 加速框架,并结合显存管理、编译优化技术,在 MiniCPM-Llama3-V 2.5 图像编码方面实现了 150 倍加速提升。
在语言模型推理方面,目前开源社区的报告结果中,Llama 3 语言模型在手机端侧的解码速度在 0.5 token/s 上下,相比之下,多模态大模型的端侧运行面临着更大的效率挑战,经过 CPU、编译优化、显存管理等优化方式,将 MiniCPM-Llama3-V 2.5 在手机端的语言解码速度提升到 3-4 token/s。
有别于常见的中英双语模型,MiniCPM-Llama3-V2.5 可支持 30+ 多种语言,包括德语、法语、西班牙语、意大利语、俄语等主流语言,基本覆盖一带一路国家。
基于自研的跨语言泛化技术,仅通过少量翻译的多模态数据的指令微调,就可对多语言多模态对话性能高效泛化。

多语言版本 LLaVABench 评测结果
9 倍像素更清晰,难图长图长文本精准识别
OCR 技术进一步打磨,复杂推理与多模态识别能力再进化,MiniCPM-Llama3-V 2.5 对于难图、长图、长文本的精准识别,再度带来出众表现。
面壁自研了高清图像高效编码技术,可以高效编码及无损识别 180 万高清像素图片,并且支持任意长宽比,包括 1:9 极限比例,突破了传统技术仅能识别 20 万像素小图的瓶颈。
另外,MiniCPM-Llama3-V 2.5 在复杂推理能力上进一步突破:可更好地深入洞察图像,在更复杂、更接近人类的水平上进行思考和解决问题。该模型不仅能理解单一文本或图像等模态信息,还能跨越不同模态间的综合信息,做出更准确和深入的分析。
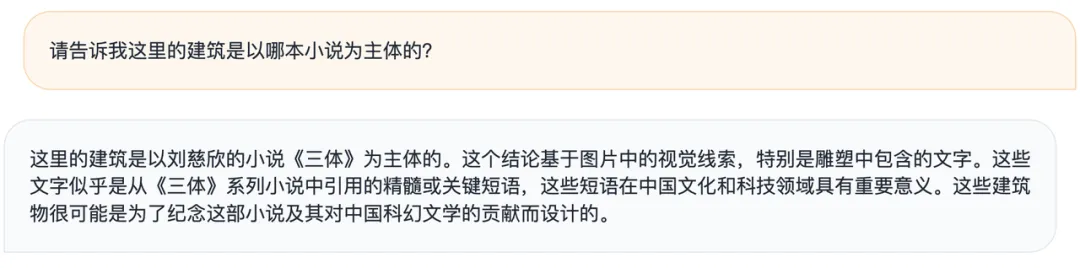
比如,给定一张充满繁密字迹的建筑风景图,人眼难以辨别,但 MiniCPM-Llama3-V 2.5 能够一眼看懂其中的《三体》主题,还能正确推理出这些建筑是为了纪念《三体》及其对中国科幻文学的贡献而设计:

把同样的问题抛给 GPT-4 V ,结果并不理想:

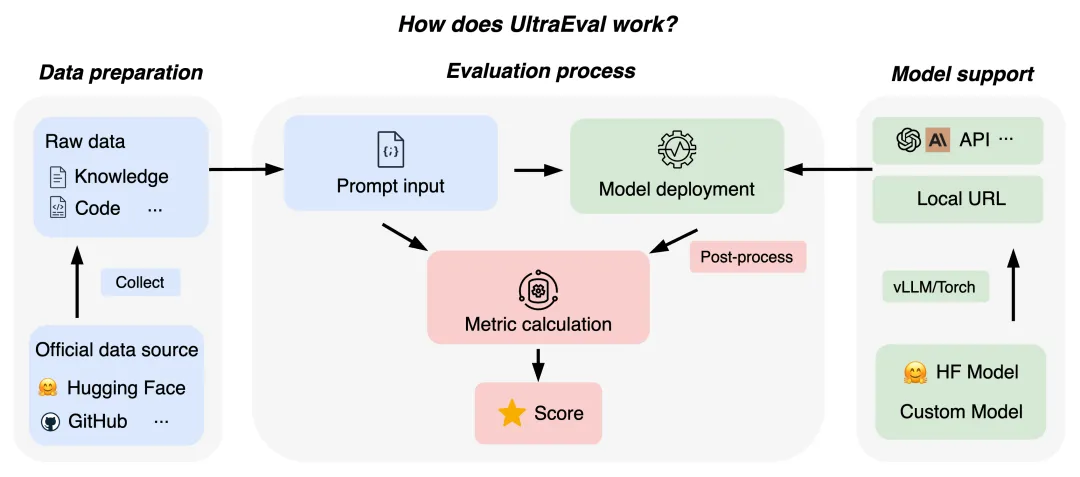
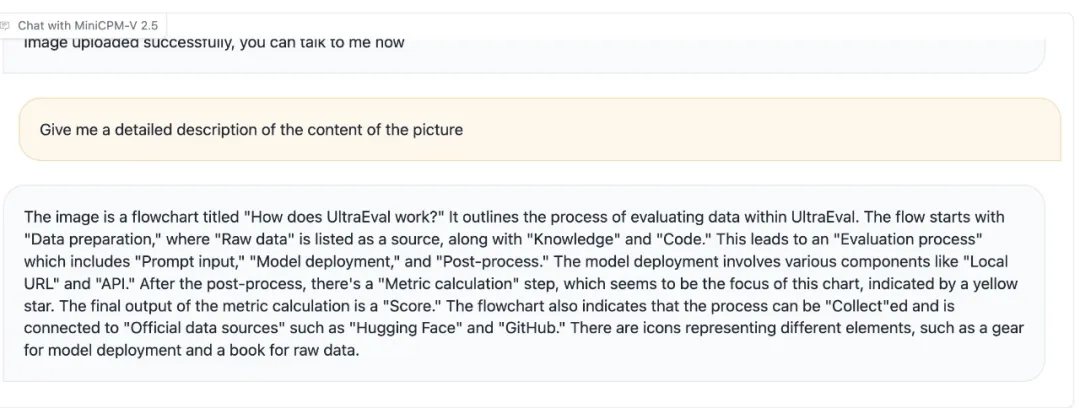
另外,识别包含复杂逻辑的流程图是多模态模型推理能力的直观体现,MiniCPM-Llama3-V 2.5 不仅能够看懂流程图中不同模块的文字、箭头之间的空间位置和复杂逻辑关系,还能给出清晰易懂的解释说明:
全文 OCR 能力方面,输入一张手机拍摄的火车票,MiniCPM-Llama3-V 2.5 也能准确提取信息,给出无误的"json"格式输出:





