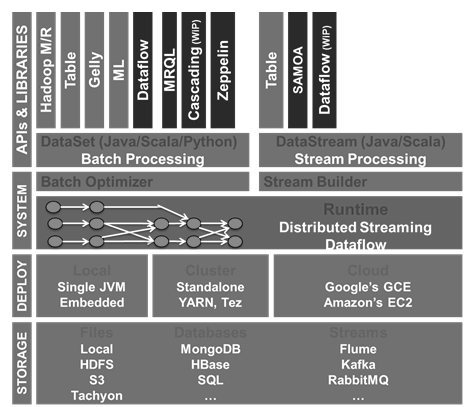
Hadoop 是大数据领域最流行的技术,但并非唯一。还有很多其他技术可用于解决大数据问题。除了 Apache Hadoop 外,另外 9 个大数据技术也是必须要了解的。
- Apache Flink
- Apache Samza
- Google Cloud Data Flow
- StreamSets
- Tensor Flow
- Apache NiFi
- Druid
- LinkedIn WhereHows
- Microsoft Cognitive Services
Apache Flink:是一个高效、分布式、基于 Java 实现的通用大数据分析引擎,它具有分布式 MapReduce 一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于 Java 和 Scala 的 API。
这是一种由社区驱动的分布式大数据分析开源框架,类似于 Apache Hadoop 和 Apache Spark。它的引擎可借助数据流和内存中 (in-memory) 处理与迭代操作改善性能。目前 Apache Flink 已成为一个顶级项目 (Top Level Project,TLP),于 2014 年 4 月被纳入 Apache 孵化器,目前在全球范围内有很多贡献者。
Flink 受到了 MPP 数据库技术(Declaratives、Query Optimizer、Parallel in-memory、out-of-core 算法)和 Hadoop MapReduce 技术(Massive scale out, User Defined functions, Schema on Read)的启发,有很多独特功能(Streaming, Iterations, Dataflow, General API)。详细了解
Apache Samza:是一个开源、分布式的流处理框架,它使用开源分布式消息处理系统 Apache Kafka 来实现消息服务,并使用资源管理器 Apache Hadoop Yarn 实现容错处理、处理器隔离、安全性和资源管理。
该技术由 LinkedIn 开发,最初目的是为了解决 Apache Kafka 在扩展能力方面存在的问题,包含诸如 Simple API、Managed state、Fault Tolerant、Durable messaging、Scalable、Extensible,以及 Processor Isolation 等功能。
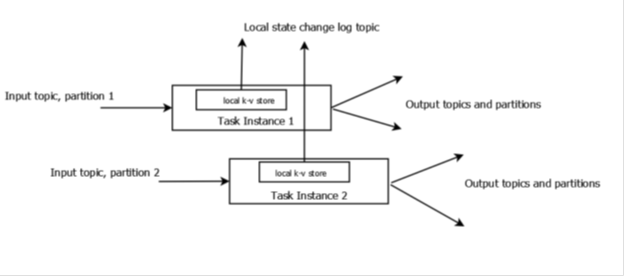
Samza 的代码可作为 Yarn 作业运行,还可以实施 StreamTask 接口,借此定义 process() 调用。StreamTask 可以在任务实例内部运行,其本身也位于一个 Yarn 容器内。详细了解
Cloud Dataflow:Dataflow 是一种原生的 Google Cloud 数据处理服务,是一种构建、管理和优化复杂数据流水线的方法,用于构建移动应用,调试、追踪和监控产品级云应用。它采用了 Google 内部的技术 Flume 和 MillWhell,其中 Flume 用于数据的高效并行化处理,而 MillWhell 则用于互联网级别的带有很好容错机制的流处理。
该技术提供了简单的编程模型,可用于批处理和流式数据的处理任务。该技术提供的数据流管理服务可控制数据处理作业的执行,数据处理作业可使用 Data Flow SDK(Apache Beam) 创建。
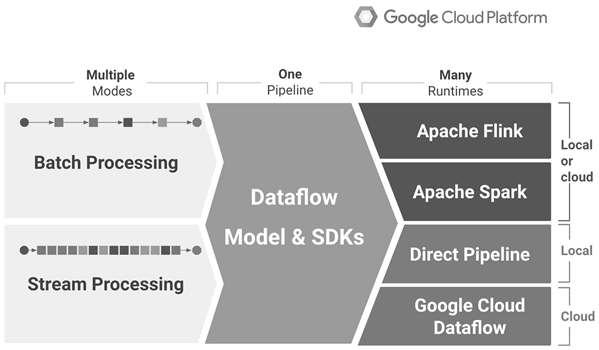
Google Data Flow 为数据相关的任务提供了管理、监视和安全能力。Sources 和 Sink 可在管线中抽象地执行读写操作,管线封装而成的整个计算序列可以接受外部来源的某些输入数据,通过对数据进行转换生成一定的输出数据。了解详情
StreamSets:StreamSets 是一种专门针对传输中数据进行过优化的数据处理平台,提供了可视化数据流创建模型,通过开源的方式发行。该技术可部署在内部环境或云中,提供了丰富的监视和管理界面。
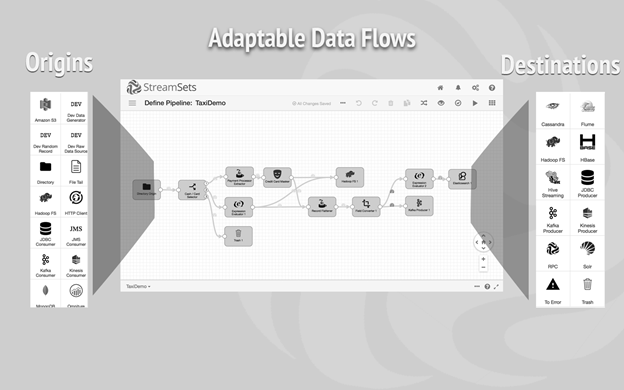
数据收集器可使用数据管线实时地流式传输并处理数据,管线描述了数据从源头到最终目标的流动方式,可包含来源、目标,以及处理程序。数据收集器的生命周期可通过管理控制台进行控制。了解详情
TensorFlow:是继 DistBelief 之后的第二代机器学习系统。TensorFlow 源自 Google 旗下的 Google Brain 项目,主要目标在于为 Google 全公司的不同产品和服务应用各种类型的神经网络机器学习能力。
支持分布式计算的 TensorFlow 能够使用户在自己的机器学习基础结构中训练分布式模型。该系统以高性能的 gRPC 数据库为支撑,与最近发布的 Google 云机器学习系统互补,使用户能够利用 Google 云平台,对 TensorFlow 模型进行训练并提供服务。
这是一种开源软件库,可使用数据流图谱 (data flow graph) 进行数值运算,这种技术已被包括 DeepDream、RankBrain、Smart Replyused 在内的各种 Google 项目所使用。
数据流图谱使用由节点 (Node) 和边缘 (Edge) 组成的有向图 (Directed graph) 描述数值运算。图谱中的节点代表数值运算,边缘代表负责在节点之间进行通信的多维数据阵列 (张量,Tensor)。边缘还描述了节点之间的输入 / 输出关系。“TensorFlow”这个名称蕴含了张量在图谱上流动的含义。了解详情
Druid:Druid 是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析,诞生于 2011 年,包含诸如驱动交互式数据应用程序,多租户:大量并发用户,扩展能力:每天上万亿事件,次秒级查询,实时分析等功能。Druid 还包含一些特殊的重要功能,例如低延迟数据摄入、快速聚合、任意切割能力、高可用性、近似计算与精确计算等。
创建 Druid 的最初意图主要是为了解决查询延迟问题,当时试图使用 Hadoop 来实现交互式查询分析,但是很难满足实时分析的需要。而 Druid 提供了以交互方式访问数据的能力,并权衡了查询的灵活性和性能而采取了特殊的存储格式。
(点击放大图像)

该技术还提供了其他实用功能,例如实时节点、历史节点、Broker 节点、Coordinator 节点、使用基于JSON 查询语言的索引服务。了解详情
Apache NiFi:Apache NiFi 是一套强大可靠的数据处理和分发系统,可用于对数据的流转和转换创建有向图。借助该系统可以用图形界面创建、监视、控制数据流,有丰富的配置选项可供使用,可在运行时修改数据流,动态创建数据分区。此外还可以对数据在整个系统内的流动进行数据起源跟踪。通过开发自定义组件,还可轻松对其进行扩展。
(点击放大图像)

Apache NiFi 的运转离不开诸如 FlowFile、Processor,以及 Connection 等概念。了解详情
LinkedIn WhereHows:WhereHows 提供带元数据搜索的企业编录 (Enterprise catalog),可以让您了解数据存储在哪里,是如何保存到那里的。该工具可提供协作、数据血统分析等功能,并可连接至多种数据源和提取、加载和转换 (ETL) 工具。
(点击放大图像)

该工具为数据发现提供了Web 界面,支持API 的后端服务器负责控制元数据的爬网(Crawling) 以及与其他系统的集成。了解详情
Microsoft Cognitive Services:该技术源自 Project Oxford 和 Bing,提供了 22 种认知计算 API,主要分类包括:视觉、语音、语言、知识,以及搜索。该技术已集成于 Cortana Intelligence Suite。
(点击放大图像)

这是一种开源技术,提供了22 种不同的认知计算REST API,并为开发者提供了适用于Windows、IOS、Android 以及Python 的SDK。了解详情
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




