
今天,由李开复打造的 AI 大模型创业公司“零一万物”发布了一系列开源大模型:Yi-34B 和 Yi-6B。
Yi-34B 是一个双语(英语和中文)基础模型,经过 340 亿个参数训练,明显小于 Falcon-180B 和 Meta LlaMa2-70B 等其他开放模型。在发布会中,李开复称其数据采集、算法研究、团队配置均为世界第一梯队,对标 OpenAI、谷歌一线大厂,并抱有成为世界第一的初衷和决心。同时,他表示 Yi-34B 是“全球最强开源模型”,其通用能力、知识推理、阅读理解等多指标均处于全球榜单首位。
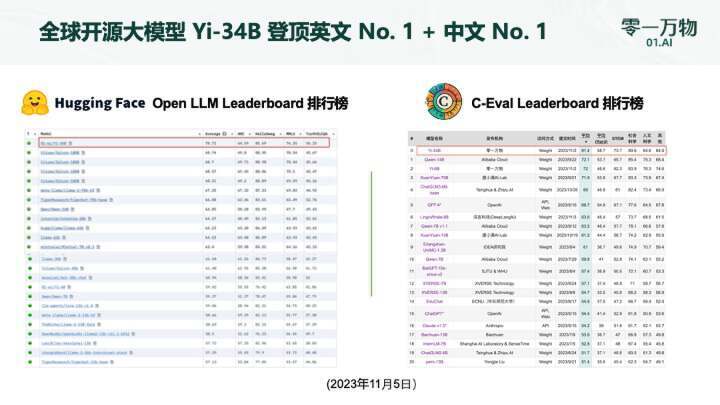
零一万物团队也进行了一系列打榜测试,具体成绩包括:
Hugging Face 英文测试榜单,以 70.72 分数位列全球第一;
以小博大,作为国产大模型碾压 Llama-2 70B 和 Falcon-180B 等一众大模型(参数量仅为后两者的 1/2、1/5);
C-Eval 中文能力排行榜位居第一,超越了全球所有开源模型;
MMLU、BBH 等八大综合能力表现全部胜出,Yi-34B 在通用能力、知识推理、阅读理解等多项指标评比中“击败全球玩家”;
......
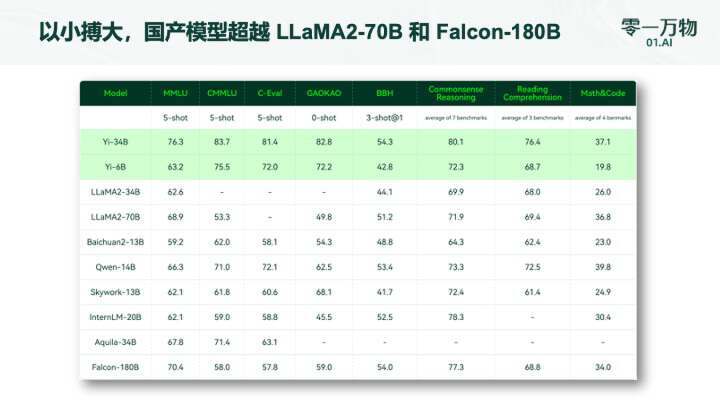
然而,在发布中,也有一点需要指出,那就是 Yi 系列模型在 GSM8k 和 MBPP 的数学以及代码测评方面表现不如 GPT 模型出色。这是因为团队希望在预训练阶段希望先尽可能保留模型的通用能力,所以训练数据中没有加入过多数学和代码数据。后续他们计划在开源系列中推出专注于代码和数学领域的继续训练模型。
200K 上下文窗口,能处理 40 万字文本
值得注意的是,此次开源的 Yi-34B 模型,将发布全球最长、可支持 200K 超长上下文窗口(context window)版本,可以处理约 40 万汉字超长文本输入。这意味着 Yi-34B 不仅能提供更丰富的语义信息,理解超过 1000 页的 PDF 文档,还让很多依赖于向量数据库构建外部知识库的场景,都可以用上下文窗口来进行替代。
相比之下,OpenAI 的 GPT-4 上下文窗口只有 32K,文字处理量约 2.5 万字。今年三月,硅谷知名 AI 2.0 创业公司 Anthropic 的 Claude2-100K 将上下文窗口扩展到了 100K 规模,零一万物直接加倍,并且是第一家将超长上下文窗口在开源社区开放的大模型公司。
在语言模型中,上下文窗口是大模型综合运算能力的金指标之一,对于理解和生成与特定上下文相关的文本至关重要,拥有更长窗口的语言模型可以处理更丰富的知识库信息,生成更连贯、准确的文本。
此外,在文档摘要、基于文档的问答等下游任务中,长上下文的能力发挥着关键作用,行业应用场景广阔。在法律、财务、传媒、档案整理等诸多垂直场景里,更准确、更连贯、速度更快的长文本窗口功能,可以成为人们更可靠的 AI 助理,让生产力得到大幅提升。然而,受限于计算复杂度、数据完备度等问题,上下文窗口规模扩充从计算、内存和通信的角度存在各种挑战,因此大多数发布的大型语言模型仅支持几千 tokens 的上下文长度。为了解决这个限制,零一万物技术团队实施了一系列优化,包括:计算通信重叠、序列并行、通信压缩等。通过这些能力增强,实现了在大规模模型训练中近 100 倍的能力提升。
实现 40%训练成本下降
AI Infra(AI Infrastructure 人工智能基础架构技术)主要涵盖大模型训练和部署提供各种底层技术设施,包括处理器、操作系统、存储系统、网络基础设施、云计算平台等等,是模型训练背后极其关键的“保障技术”,这是大模型行业至今较少受到关注的硬技术领域。
李开复曾经表示,“做过大模型 Infra 的人比做算法的人才更稀缺”,而超强的 Infra 能力是大模型研发的核心护城河之一。在芯片、GPU 等算力资源紧缺的当下,安全和稳定成为大模型训练的生命线。零一万物的 Infra 技术通过“高精度”系统、弹性训和接力训等全栈式解决方案,确保训练高效、安全地进行。
凭借其强大的 AI Infra 支撑,零一万物团队表示,Yi-34B 模型训练成本实测下降 40%,实际训练完成达标时间与预测的时间误差不到一小时,进一步模拟上到千亿规模训练成本可下降多达 50%。截至目前,零一万物 Infra 能力实现故障预测准确率超过 90%,故障提前发现率达到 99.9%,不需要人工参与的故障自愈率超过 95%,有力保障了模型训练的顺畅进行。
零一万物背后
今年 7 月,李开复博士正式官宣并上线了其筹组的“AI 2.0”新公司:零一万物。此前李开复曾表示,AI 大语言模型是中国不能错过的历史机遇,零一万物就是在今年 3 月下旬,由他亲自带队孵化的新品牌。
在接受外媒采访时,他谈到了创办零一万物的动机:“我认为需求是创新之母,中国显然存在巨大的需求,”“与其他国际地区不同,中国无法访问 OpenAI 和谷歌,因为这两家公司没有在中国提供他们的产品。因此,我认为有很多人正在努力为市场创造解决方案。这是刚需。”
众所周知,构建大模型是一项耗资巨大的事业。为了维持现金密集型业务,零一万物从一开始就制定了商业化计划。虽然该公司将继续开源其一些模型,但其目标是构建最先进的专有模型,作为各种商业产品的基础。
李开复表示,他们非常清楚这些大型语言模型需要大量计算,花费巨大。“我们筹集到了大量资金,其中大部分都花在了 GPU 上。”与中国其他 LLM 玩家一样,零一万物也需要积极储备 GPU 以应对美国制裁。在发布会中,李开复表示零一万物现在的供应至少足以满足未来 12-18 个月的需求。
美国的制裁也让中国企业注重优化计算能力,李开复表示:“借助一支非常高质量的基础设施团队,每 1000 个 GPU,我们也许能够从中挤出 2000 个 GPU 的工作负载。”
从一些报道中,我们可以了解到,零一万物员工规模已超过 100 人,半数是来自国内外大厂的 LLM 专家。其中,零一万物技术副总裁及 AI Alignment 负责人是 Google Bard/Assistant 早期核心成员,主导或参与了从 Bert、LaMDA 到大模型在多轮对话、个人助理、AI Agent 等多个方向的研究和工程落地;首席架构师曾在 Google Brain 与 Jeff Dean、Samy Bengio 等合作,为 TensorFlow 的核心创始成员之一。
零一万物的商业化之路很大程度上取决于其为其昂贵的 AI 模型找到适合的产品市场的能力。“中国在大模型方面并不领先于美国,但毫无疑问,中国可以构建比美国开发商更好的应用程序,这主要是因为过去 12 年左右建立的非凡的移动互联网生态系统,”李开复说道。
李开复表示,这家初创公司的最终目标是成为一个外部开发人员可以轻松构建应用程序的生态系统。“我们的职责不仅仅是推出好的研究模型,更重要的是让应用程序开发变得容易,这样才能有优秀的应用程序,”他说。“归根结底。这是一场生态系统游戏。”
开源地址:
Hugging Face:https://huggingface.co/01-ai/Yi-34B;https://huggingface.co/01-ai/Yi-6B
ModelScope:https://www.modelscope.cn/models/01ai/Yi-34B/summary; https://www.modelscope.cn/models/01ai/Yi-6B/summary
GitHub:https://github.com/01-ai/Yi




