近日,微软正式发布了Azure Archive Storage。Azure Storage 的归档特性已经面向客户预览了数月,而且,此次发布包含Blob-Level Tiering,让客户可以在不同的层之间优化数据的全生命周期存储。
Azure Storage 团队去年推出了 Cool Blob Storage ,让客户把不经常访问的数据转移至 Cool 层,降低数据存储成本。他们可以把极少访问的数据存储到 Archive 层,进一步降低成本。
Azure Storage 目前有三层:Hot、Cool 和 Archive。不过,每一层的可用性、使用费、数据存储期限、延迟、可伸缩性、性能都有所不同。
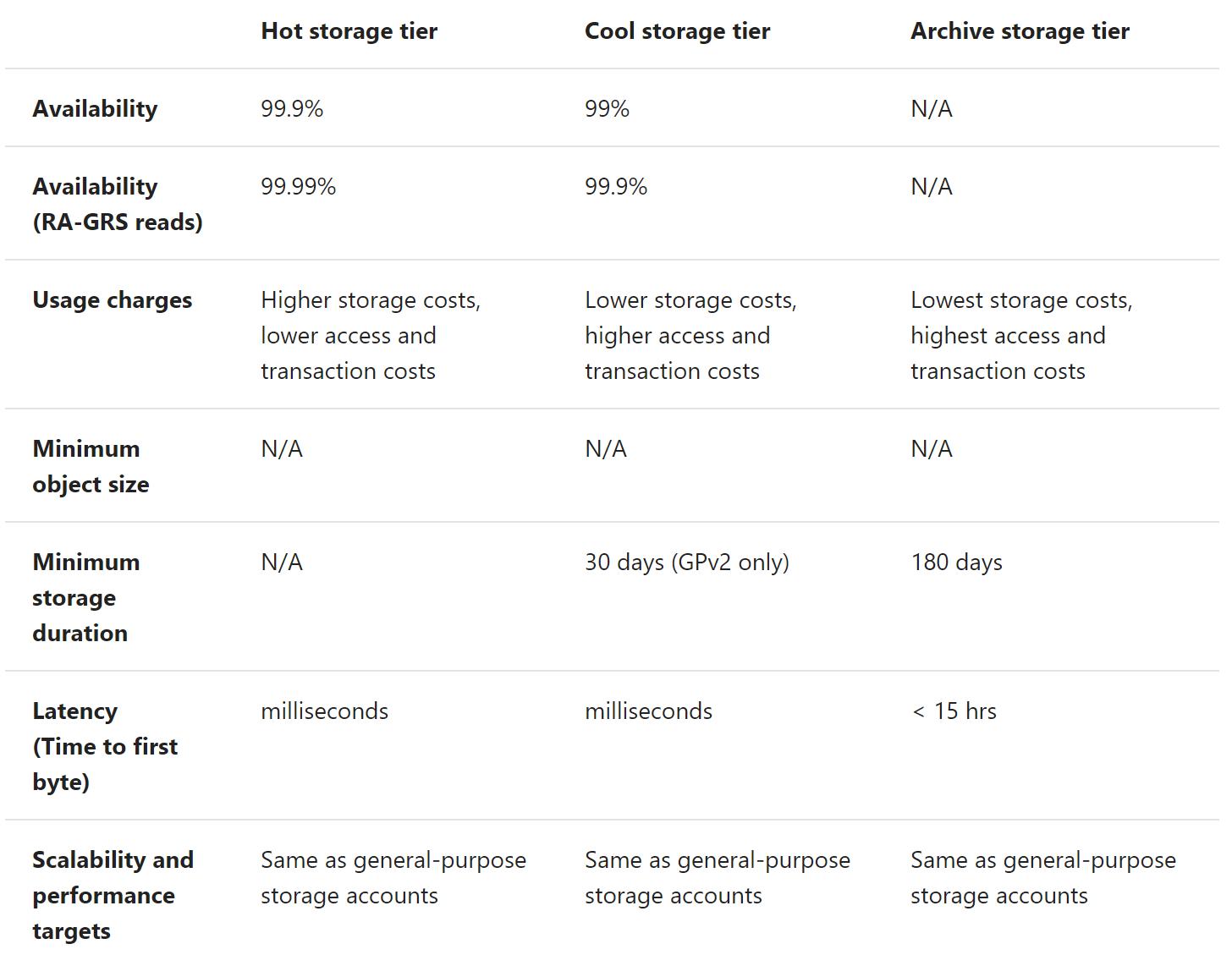
图片来源: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
借助 Blob-Level Tiering 的能力,客户可以在对象级上分层数据,也就是说,可以在 Hot、Cool 或 Archive 层之间改变单个对象的访问层级。现有及新增的 Blob Storage 和 General Purpose v2(GPv2)账户都可以使用 Archive Storage 和 Blob-Level Tiering 功能。这些层中的数据可以通过 Azure portal、PowerShell、CLI 工具、REST API、Microsoft Azure Explorer 访问,也可以通过.NET、Java、Python 等编程语言或 Node.js 客户端库访问。
HubStor 是 Azure Storage Archive 的早期用户之一。该公司在 Microsoft Azure 云平台上以软件即服务(SaaS)的方式提供二级存储解决方案。其首席执行官 Geoff Bourgeois表示:
通过解决云上 Cool 存储的问题,组织可以降低诸如合规性这种关键需求的风险和操作复杂性。HubStor 参与了微软的非公开预览计划,其目的是尽早试用并及时向客户提供 Azure Archive Storage 和 Blob-level Tiering 特性的集成。
此外,甚至是作为世界领先的微软云数据迁移和管理解决方案提供商之一的 Archive360 也推出了新产品 Archive2Azure ,这是一个支持 Archive Blob Storage Tier 的智能数据管理和合规归档的长期解决方案。Archive360 市场营销副总裁 Bill Tolson表示:
新的 Azure Archive Blob Storage 层,加上 Archive2Azure 软件,对于簿记经理、档案管理员、HR 部门、IT 部门和法律部门——几乎每个垂直行业——任何收集存储时间长但访问次数少而又必须保证可用性、保护等级与安全性的数据的人,这是他们的福音。
Archive 的起步价为每 GB 每月 0.002 美元;关于自 2 月 1 日起生效的定价细节,请查看 Archive Storage 通用价格页面。这项特性在 14 个区域提供, Microsoft Azure 文档站点提供了 Azure Storage 的完整文档。
查看英文原文: Microsoft Announces General Availability of Azure Archive Storage




