苹果发明了一种神经网络系统,可以从由 LIDAR 传感器生成的点云中分离出对象。
不久之前,苹果进军无人驾驶领域。不过,关于他们的汽车,我们了解的并不多。许多正在研发自动驾驶汽车的公司都使用所谓的 LIDAR 来检测汽车周围的障碍物。LIDAR 发出光脉冲,并测量该脉冲返回传感器的时间,然后就可以计算出汽车与附近的障碍物之间的距离。旋转传感器就可以测得传感器周围的所有障碍物。

LIDAR 获得的距离存储在所谓的“点云(Point Cloud)”中。在将这个点集可视化之后,人类可以很轻松地检测出这些点云中各种类型的对象,如人、汽车、自行车。遗憾地的是,对计算机而言,这仍然是一项困难的工作。读者可以试着指出上图中的人和汽车。
传统方法依靠人工编制的特性赋予这些数据意义。例如,将云分割成子云的方法,或者将点云分离成平面的方法。还有一种让 LIDAR 数据有意义的方式是选择一个观察点,把图像输入已有的计算机视觉算法。这些方法的缺点是特性设计非常困难,而且也很难设计出可以很好地概括所有情况的特性。现在,苹果创建了一种端到端的神经网络来解决这个问题。这种方法不依赖任何手工编制的特性或神经网络之外的其他机器学习方法。

该方法的第一部分是所谓的“特性学习网络”。苹果把这个空间分解成所谓的三维像素(3D 像素)。在检测汽车时,他们将每个三维对象的尺寸设定为2 米高、2.4 米宽(这样,一辆汽车就可以很好地匹配到一个三维像素里去)。在每个三维像素里,他们随机选取一个点的子集(有些三维像素包含许多点,有些只包含几个,这样处理之后,每个三维像素包含同样数量的神经网络输入)。他们把这个点的子集输入到神经网络,在一个128 维的空间里创建一个表示。
对这个空间里每一个点都进行这样的处理,就得到一个数据结构,让你可以通过在神经网络方法中看到的相同的网络结构输入到计算机视觉算法。通过多个卷积层,神经网络把输出投射成一张概率图和一种回归图(如下图所示)。概率图说明了这个空间中的每个三维像素是否包含对象。回归图说明了每个三维像素中对象的位置。
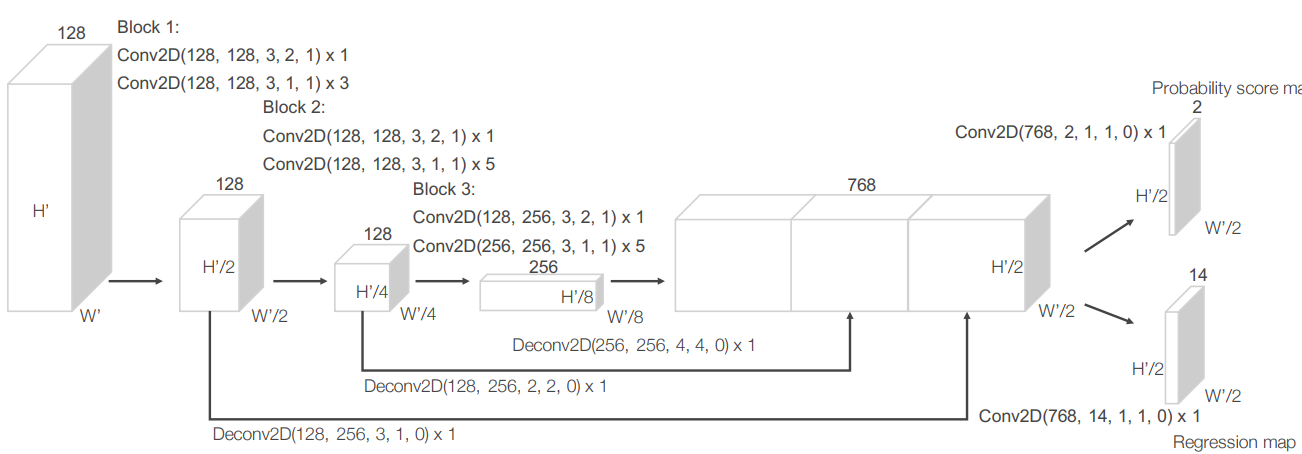
苹果使用KITTI Vision 基准测试测试了他们的方法,并把他们的方法和其他使用类似数据的方法进行了比较,不过,有些方法使用了人工编制的特性。结果表明,与所有现有的方法相比,包括使用了人工编制的特性的方法,他们的方法性能更好。
通过这项研究,苹果展示了他们在自动驾驶项目中使用的方法。今年有报道称,苹果使用了车顶上总计12 个LIDAR 传感器中的6 个。他们在一篇论文里发布了他们的结果,感兴趣的读者可以从ArXiv 下载。
查看英文原文: How Apple Uses Neural Networks for Object Detection in Point Clouds




