针对云服务大战环境,记得甲骨文公司创始人、董事长兼 CTO Larry Ellison 曾说过:现在云计算仍旧处于早期阶段,甲骨文已经做好准备,全力进军云计算领域。时隔不久,好消息就传来了。在 8 月 3 日的 2017 甲骨文数据库云技术大会上,甲骨文公司数据库技术全球执行副总裁 Andrew Mendelsohn 介绍了甲骨文在提供云数据库服务过程中,基于当前云端环境和客户场景所做的技术创新。

Andrew Mendelsohn 在演讲中说到,甲骨文一直以来都很重视中国市场,因为在中国有众多金融机构,拥有全球最大的银行,这样大规模的交易服务就需要大的云端数据库以及服务器来处理业务,所以甲骨文会为中国用户提供先进的技术方案,那么如何进一步在云端提供更好、更稳定的数据库?
甲骨文在了解市场需求之后,在云端做的最大的一个变革就是架构起多租户的数据库,这是一个非常关键的基础架构,也就是说客户有数据库的话,就需要去做一些 SaaS 的应用。这个时候如果只是依靠于之前的网络技术,客户的能力就不足以在这样的云端上架构起全面网络,所以他们需要做多租户部署,也要在业务迁移到云端之前去开发一些更加尖端的技术来满足客户的需求。
甲骨文做了很多相关技术的整合,包括 JSON 数据、SQL 数据库,还有很多开发者也会用 Java 语言,这些都会被整合到甲骨文核心数据库当中。
Andrew 说,现在用 SQL 语言将所有来源的数据都整合到云端,去进行一个相关的查询语言的应用,也可以在云端进行相关的存储和运算,以实现最佳高性能的语言处理。
Andrew 也介绍了甲骨文的新动向,例如 Oracle 数据库 12cR2 正式发布,可以将公有云部署在客户环境和本地;NoSQL 数据库可以包含在 Oracle 数据库企业版中;新的数据库云服务正式发布,包括 Exadata 快捷版,MySQL 云服务,Big Data SQL 云服务;推出下一代 IaaS 云服务数据中心,为客户提供加强的数据库和 Exadata 云服务;公有云部署在客户环境的扩展,正式发布可部署在客户环境的 Exadata 和大数据公有云服务器。
在数据库方面实现不断地创新,是为了能够克服更多的挑战来实现下一代数据库的发展,所以现在甲骨文要做的是发展云端的数据库技术。甲骨文在数据管理和数据库上的优势,主要存在于三个主要方面:一个是转化到内存的数据库,第二个是从数据的仓储到大数据,第三个是能够实现全面优化的云服务。
首先,就是从磁盘式到内存式的数据库。在原始的基于磁盘的存储方式当中是行格式。同时也是使用内存当中的缓存和磁盘存储的方式。基于内存的是非常好的数据库优化,我们可以用集成的内存、闪存和 NVRAM 的存储方式。同时我们还可以做双格式,就是包括行和列的格式。最主要的是我们硬件的存储供应商,比如 DRAM 技术已经很成熟了,最近闪存也逐渐地存在了我们的硬盘当中,这叫做非易失性存储的技术,简称为 NVRAM。也就是说这种存储模式是一直存在的,会替代掉传统的存储模式。

Oracle 数据库 12c 的存储模式要比传统的基于磁盘的模式更加先进,包括内存选件、实时分析、性能和易于实施,这种实施让交易和分析在同一个数据库当中进行。与此同时,它还可以提供亚秒级的报告和分析,比如说在亚马逊买了一本书,相应的数据库就会在一张表中对你进行分析。
追求性能也是非常高端的事情。甲骨文在做技术创新的时候,一件重要的事情就是保持兼容性。在过去三十年当中,甲骨文数据库的应用不断加速运行,兼容性更好,更不用重写任何的应用代码,这就是使用了甲骨文的内存技术,这也是内存数据库的优势。
Andrew 说,12cR2 的新特性里包含性能增强基因,例如 3 倍更快的连接。使用内存连接组,SQL 的查询速度可以更加快速;10 倍更快的复杂查询,使用内存表达式;60 倍更快的 JSON 查询,使用新的优化的二进制格式,通过这些技术希望达到更好的 JSON 查询。正是因为这些新特性和高效效果,很多客户已经逐渐更新到了 12cR2 这一新版本服务上。这也会让 DBA 的工作变得更加轻松。
从数据仓库到大数据,甲骨文是如何给客户做技术支持的?Andrew 解释说,传统的数据仓库操作就像从 Exadata 或者是关系型数据库的交易里面提炼出很多的数据,一般情况下做分析和数据挖掘,这是传统的数据仓库操作。但是如果进入到大数据时代,需要不断地扩展现在所做的各种事情的边界,不仅是 SQL 关系型数据库,还有机器学习和图像学习的挖掘能力。
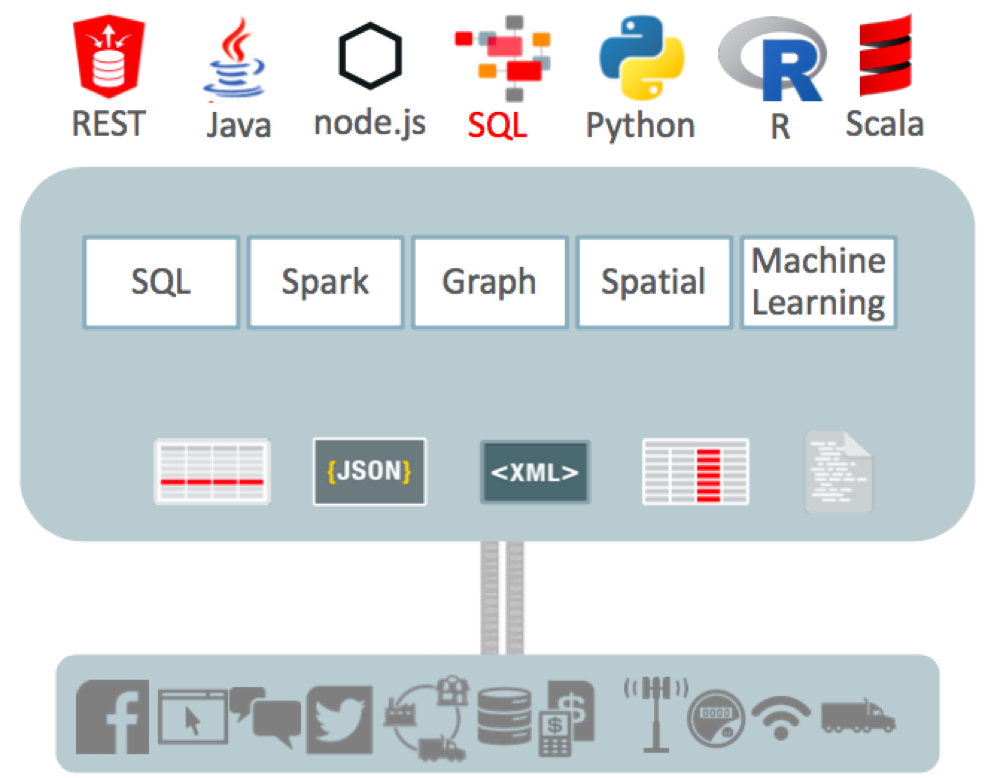
再看一下逻辑层,这是大数据现有的分析平台,任何的语言都可以来读取数据库,也可以进行任何的分析。无论是 SQL、Spark 或者是 Graph 或机器学习,这种数据的结构也可以变,有结构的、无结构的,或者是 JSON 的,亦或是其他类型的数据库,比如关系型、非关系型等等都是可以的,数据可以来自于任何的数据源,这就是一种新的大数据分析模式。
再深入挖掘一下大数据 SQL,它的架构体现在大数据 SQL 的构成,有任何数据库的构成都可以并行使用这样的 SQL 进行查询。这些数据库是分散在各种各样的仓库当中,不仅放在 Oracle 数据库,也可以放在 Hadoop 等,因此这种查询服务功能非常强大,无论是在云端还是在客户本地都可以进行查询。这种技术是基于 Exadata 技术之上,被称为智能扫描或闪存和缓存。这些技术都是基础,甲骨文希望在不同的数据源之间进行可扩展连接,不仅仅是 Oracle 数据库。
Oracle 数据库的三个优势,第一个是要更低的成本,第二个是更高的敏捷性,第三个是弹性扩展,即数据库可以拓展,也可以收缩。
也许有人会问,在云当中如何降低成本?传统的本地部署要为高峰期的容量买单,但是现在是按所需容量买单。在优化的云上面是按使用量付费的,降低了客户的消费成本。其次就是在甲骨文的云端数据库上,运营成本也非常低。因为多租户的架构确实可以帮助用户降低自动化的成本,还可以减少人工部署的费用。
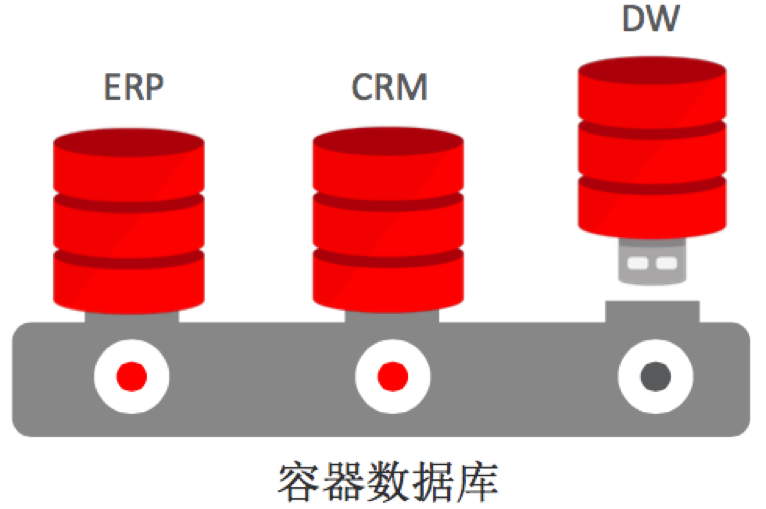
什么叫做多租户的架构?容器数据库是代表你可能有超过 4 个可插拔的虚拟数据库,它是根据应用来进行调整的,就像一个真实的 Oracle 数据库一样,可以被放在一个容器数据库当中,放在一个服务器上面,而且还可以在集成的服务器集群当中运行,无论是用 SaaS 还是 DBS,有的时候还会使用很多小的数据库。通过甲骨文容器数据库的技术,可以将这种几千个小的数据库放到一个容器里面,所以用户在管理的时候只需一键就可以控制好多个不同的数据库。
再看一下敏捷性,其实就是在云端快速建立一个新的数据库,这样的敏捷性可以快速扩张,也可以快速收缩。多租户架构是关键,一旦有一个容器数据库,客户在做可插拔数据库的时候是非常简单的,这种原数据的操作在几秒钟内就可以做完了,所以多租户的技术就是敏捷性的前提。
最后一个非常重要的点就是弹性扩展。Andrew 说,在单一的服务器当中,你可以加不同的内核,或者是有其他的一些服务进行横向扩展。例如 Oracle 数据库可以扩展 RAC 群集,同时因为它是按需供应容量的,所以可以满足容量的激增。此外,它可以在数据库当中进行自动数据库的分片,还具备大规模的客观扩展性和可靠性,这些都是数据库优化云提供的弹性扩展能力。




