Google 开发了一种可以接受多种形式输入并能生成多种形式输出的算法。
目前,大部分机器学习应用程序都只能关注一个领域。机器翻译一次只能建立一个语言对的模型,而图像识别算法一次只执行一个任务(例如描述图像、判断图像所属类别或在图像中查找对象)。然而,我们的大脑在执行所有任务时都能表现得很好,并且能够将知识从一个领域转移到另一个领域。大脑甚至可以将通过听学到的知识转换成其他领域的知识:看到或者读到的知识。
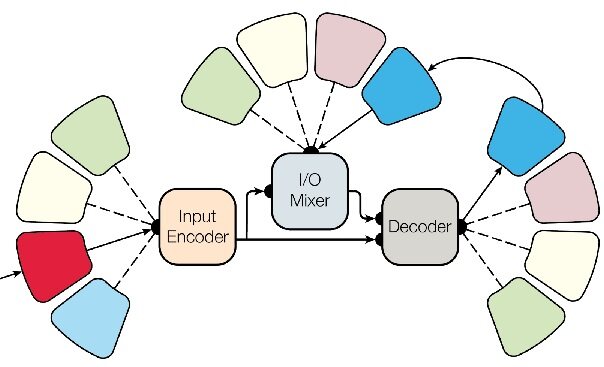
Google 开发了一个能够执行8 个不同领域任务的模型:语音识别、图像分类和添加标题、句法解析、英德互译和英法互译。这个模型由编码器、解码器和“输入输出混频器”组成,其中“输入输出混频器”会将先前的输入和输出馈送到解码器。如下图所示,每个“花瓣”表示一种形式(声音、文本或图像)。神经网络可以通过任意一种输入和输出的形式来学习每个任务。
2016 年 11 月,Google 发布了 zero-shot 翻译。该算法将所有句子映射到“中间语言”,“中间语言”指的是一种对于每种输入语言和输出语言都相同的句子。Google 只针对英韩语言对和英日语言对进行了训练,也就是说这个神经网络并未学习过对应的日韩语言对,但这时这个神经网络就能够进行日韩互译了。
Google 报告称,使用 MultiModel 时使用少量训练数据的任务表现更好。机器学习模型通常在使用更多训练数据的时候表现更好。使用 MultiModel 可以从多个领域获取额外的数据。需要注意的是,使用这种方法并没有打破标准任务任何已有的记录。
MultiModel 作为 Tensor2Tensor 库的一部分在 GitHub 开源。有关这个模型更详细的方法和研究结果可以在 arxiv.com 的论文 One Model To Learn Them All 中找到。
查看英文原文: Google Presents MultiModel: A Neural Network Capable of Learning Multiple Tasks in Multiple Domains
感谢冬雨对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




