Intel 开源了基于 Apache Spark 的分布式深度学习框架 BigDL。BigDL 借助现有的 Spark 集群来运行深度学习计算,并简化存储在 Hadoop 中的大数据集的数据加载。
BigDL 适用的应用场景主要为以下三种:
- 直接在 Hadoop/Spark 框架下使用深度学习进行大数据分析(即将数据存储在 HDFS、HBase、Hive 等数据库上);
- 在 Spark 程序中 / 工作流中加入深度学习功能;
- 利用现有的 Hadoop/Spark 集群来运行深度学习程序,然后将代码与其他的应用场景进行动态共享,例如 ETL(Extract、Transform、Load,即通常所说的数据抽取)、数据仓库(data warehouse)、功能引擎、经典机器学习、图表分析等。
运行于 Spark 集群上 Spark 是被工业界验证过的,并有很多部署的大数据平台。BigDL 针对那些想要将机器学习应用到已有 Spark 或 Hadoop 集群的人。
对于直接支持已有 Spark 集群的深度学习开源库,BigDL 是唯一的一个框架。
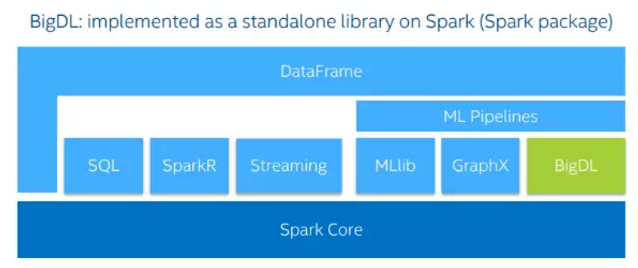
BigDL 可以直接运行在已有 Spark 集群之上,和 Spark RDD, DataFrame/DataSet 直接接口,不需要额外的集群数据加载,从而大大提高从数据抽取到深度学习建模的开发运行效率。用户不需要对他们的集群做任何改动,就可以直接运行 BigDL。BigDL 可以和其它的 Spark 的 workload 一起运行,非常方便的进行集成。
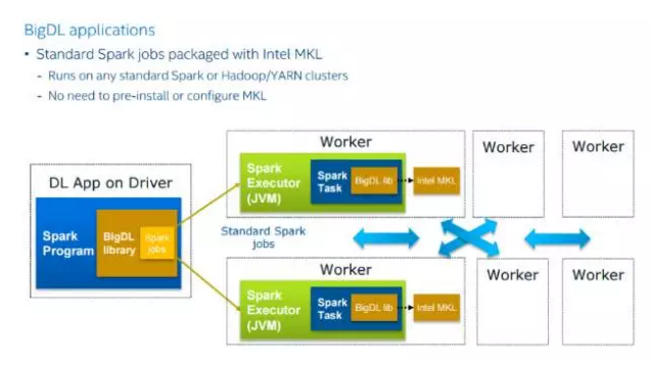
BigDL 库支持 Spark 1.5、1.6 和 2.0 版本。BigDL 库中有把 Spark RDDs 转换为 BigDL DataSet 的方法,并且可以直接与 Spark ML Pipelines 一起使用。
Non GPU on Spark
BigDL 目前的测试结果是基于单节点 Xeon 服务器的(即,与主流 GPU 相当的 CPU),在 Xeon 上的结果表明,比开箱即用的开源 Caffe,Torch 或 TensorFlow 速度上有“数量级”的提升,最高可达到 48 倍的提升(Orders of magnitude ,up-to 48X today)。而且能够扩展到数十个 Xeon 服务器。
为什么创建一个默认情况下不使用 GPU 加速的深度学习框架?对于英特尔来说,它是促进下一代 CPU 机器学习的策略的一部分。
Spark 传统上不是一个 GPU 加速的产品,虽然目前 IBM 和 Databricks(于去年底)有在自己的集群上增加支持 GPU 加速的 Spark 服务;其实使用 GPU 也将是一种趋势。从另一方面来说,BigDL 是给开发者的一个福利,理论上,使用现有软件会比移植到 GPU 架构上的工作量小很多。比如说英特尔采用 GPU-a PCIe 附加卡的形式封装了 Xeon Phi 处理器,由 Xeon Phi 插件卡组成的系统可以通过简单地更换或添加卡来升级或扩展,而不用更换整个机架。
性能上的优化措施
与使用 GPU 加速来加速过程的其他机器学习框架不同,BigDL 使用英特尔数学内核库(Intel MKL)来得到最高性能要求。在性能提高策略上,它还针对每个 Spark task 使用了多线程编程。
对于模型训练,BigDL 使用了在多个执行器中执行单个 Spark 任务的同步小批量 SGD(Stochastic Gradient Descent)。每个执行器运行一个多线程引擎并处理一部分微批次数据。在当前版本中,所有的训练和验证数据都存储到存储器中。
BigDL 使用 Scala 开发,并参考了 Torch 的模型。像 Torch 一样,它有一个使用 Intel MKL 库进行计算的 Tensor 类。Intel MKL(Math Kernel Library)是由一系列为计算优化过的小程序所组成的库,这些小程序从 FFT(快速傅立叶变换)到矩阵乘法均有涉及,常用于深度学习模型训练。Module 是另一个从 Torch 借鉴而来的概念,它的灵感来自 Torch 的 nn package。Module 代表单独的神经网络层、Table 和 Criterion。
易用性上的优化
BigDL 的 API 是参考 torch 设计的,为用户提供几个模块:
- Module: 构建神经网络的基本组件,目前提供 100+ 的 module,覆盖了主流的神经网络模型。
- Criterion:机器学习里面的目标函数,提供了十几个,常用的也都包含了。
- Optimizer:分布式模型训练。包括常用的训练算法(SGD,Adagrad),data partition 的分布式训练。
用户只需定义好模型和目标函数,就可以放到 Optimizer 里面去训练。对于数据预处理,BigDL 提供了一个叫 Transformer 的接口封装,并且提供了很多图像、自然语言处理方面的预处理算法的实现。另外还提供很多示例程序,让用户了解怎么使用 BigDL。例如怎么训练模型,怎么和 Spark 其它模块一起工作。
BigDL 提供了一个 AWS EC2 镜像和一些示例,比如使用卷积神经网络进行文本分类,还有图像分类以及如何将在 Torch 或 Caffe 中预训练过的模型加载到 Spark 中进行预测计算。来自社区的请求主要包括提供对 Python 的支持,MKL-DNN(MKL 的深度学习扩展),faster-rcnn,以及可视化支持。




