近年来随着深度学习的急剧升温,不管是学术界还是工业界都把大量资源投入了深度学习。作为一个普通的工程师或者程序员,也想对机器学习,尤其是深度学习有所了解,应当如何入手?最好的回答当然是“gets your feet wet”——不下水是终究是学不会游泳的。然而,深度学习火爆的同时,带来的一个副作用是:面对琳琅满目的各色名词,初学者简直毫无头绪,也无从下手。特别是机器学习、深度学习,以及最近炒得很火的强化学习、迁移学习,到底是怎么一回事儿?
本文试图以自己亲自操刀的两个项目案例演示迁移学习的实际应用,并且在篇头以维基百科上的定义,对上述几种机器学习作个简单的阐明,以及做个对迁移学习的简单科普。
迁移学习的概念
首先可以看看维基百科上关于机器学习、深度学习、强化学习和迁移学习的定义:
-
机器学习是人工智能的一个分支。人工智能的研究是从以“推理”为重点到以“知识”为重点,再到以“学习”为重点,一条自然、清晰的脉络。显然,机器学习是实现人工智能的一个途径,即以机器学习为手段解决人工智能中的问题。机器学习在近 30 多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。
机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习理论关注可以实现的,行之有效的学习算法。很多推论问题属于无程序可循难度,所以部分的机器学习研究是开发容易处理的近似算法。
-
深度学习(英语:deep learning)是机器学习拉出的分支,它试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。[1][2][3][4][5] 深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别 [6])。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。[7]
-
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法具有普适性,因此在其他许多领域都有研究,例如博弈论、控制论、运筹学、信息论、仿真优化、多主体系统学习、群体智能、统计学以及遗传算法。在运筹学和控制理论研究的语境下,强化学习被称作“近似动态规划”(approximate dynamic programming,ADP)。
在最优控制理论中也有研究这个问题,虽然大部分的研究是关于最优解的存在和特性,并非是学习或者近似方面。在经济学和博弈论中,强化学习被用来解释在有限理性的条件下如何出现平衡。
-
Inductive transfer, or transfer learning, is a research problem in machine learning that focuses on storing knowledge gained while solving one problem and applying it to a different but related problem.[1] For example, knowledge gained while learning to recognize cars could apply when trying to recognize trucks. This area of research bears some relation to the long history of psychological literature on transfer of learning, although formal ties between the two fields are limited.
维基百科上,机器学习、深度学习、强化学习都已有中文条目。而迁移学习的词条至今还没有中文版本,可见这个概念在公共领域才刚刚兴起。简单将英文条目翻译成中文就是:归纳迁移,也叫做迁移学习,是机器学习中的一个研究问题。它侧重于把解决某一问题时的知识储存起来,以便应用到不同、但是相关的其他问题上去。例如,通过学习识别小轿车获得的知识,也可以用来尝试识别大卡车。
一言一蔽之:机器学习(ML)是人工智能(AI)的一个子领域,而深度学习、强化学习、迁移学习都是机器学习的子领域。它们按照各自的特点自成一类,并不意味着它们的定义是互斥的。恰恰相反,本文列举的两个例子都是基于深度学习的迁移学习,而且在目前的学术研究和业界应用中也非常常见。
迁移学习的有效性从何而来?
因为现有的机器学习,特别是深度学习的各种模型,在能充分满足设计时的任务需求之外,往往具备稍加修改就能适用类似任务的能力。这种可能性,就为节省研发资源,以及将大数据机器学习成果转移到小数据、定制化应用等等提供了一个便捷的渠道。类比人类活学活用的智能:比如一个人扎实地学会了蛙泳,只需要稍加练习,也能较快掌握自由泳的技巧;一个人学会了打网球,那么要学习打壁球也非常容易。
这种举一反三的能力,既得益于人类的智能,也依赖于学习对象之间的某种类比相似性。而机器学习中的很多模型,恰恰在特定领域具有类似的智能。比如用于图像识别的深度神经网络,在使用百万量级的图片,完成针对特定一千种物体识别的训练以后,它不光能胜任这一千种物体的识别,而且它的整个网络结构、参数设置使它也有可能适应其它物体的图像识别。
从具体操作的角度,可以有:
- 样本迁移,即将任务 A 中部分适合任务 B 的数据抽取出来,与其它数据一起针对任务 B 进行训练;
- 特征迁移,比如用于识别小轿车的神经网络,那些用来识别车轮车窗的网络参数,可以直接迁移到卡车识别的神经网络,再辅以卡车图像数据,就能事半功倍地训练出卡车识别网络。
- 模型迁移,这个跟特征迁移类似,但是更简单粗暴,不光是特征被迁移用来类似任务,而且是这个模型都被迁移。这个模式的实际案例非常多,很多研究成果都是将 AlexNet、GoogLeNet 等模型迁移到特定的任务。当然也会根据需求略作改进和添加新的辅助功能,但是总体上看,节省了大量的开发时间、也节省了大量用于学习的计算资源,还能取得相当甚至更好的效果。
- 关系迁移,即将事物间的相互关系类推到类似事物。这个可能在 NLP 等有具体规则的机器学习领域更为常见,比如 man->woman, 可以类推到 king->queen,还可以推广到更多词汇的机器理解。
本文两个案例都用到了模型迁移,因为简单有效,直接照搬,非常适合短时间开发可用方案。
案例一
新加坡政府机构组织的视频分析挑战赛(参考网址: https://www.imda.gov.sg/infocomm-and-media-news/buzz-central/2015/8/challenge-the-state-of-the-art-in-video-analytics)
我所在实验室为成像技术实验室(Imaging Technology Center),而上司非常想在政府组织的比赛里检测下员工的能力以及增加一下实验室的曝光率,于是决定参加这一挑战。时间是 2015 年 8 月到 11 月。
比赛内容就是通过视频分析,检测出视频中出现的人脸并定位。其难度在于:1. 机位隐蔽视角刁钻 2. 人流密度极大。否则,用常规计算机视觉的方法就能解决问题了,比如开源的 OpenCV 中就有 haar, HoG, LBP 等各种人脸、人身等目标检测功能。
实际上由于时间仓促,(8 月中旬启动,9 月初现场测试,刚好两周时间)。第一轮选拔比赛我们使用的就是 OpenCV 的 HoG,配以适当的手工微调。如果是应付优化好的机位,稀疏的人群,是没有什么问题,但是面对任意倾斜角度以及密密麻麻互相遮挡的人群,传统方法的确是力有不逮。好在我们进入了第二轮也就是最终轮。
第二轮是 9 月中旬到 11 月底,时间相对充裕。于是我们决定尝试用当时已经火了一阵的 Caffe 作为深度学习库。此时 Google 的 Tensorflow 并没有开源,并且 Tensorflow 是在 2015 年 11 月才放出第一个公开版本。为了应对比赛的特殊要求,我特地搜索了一下”crowded pedestrian”,”end-to-end”等关键词,于是搜到了一个斯坦福研究员的 paper 和开源代码: https://github.com/Russell91/ReInspect 。两者都很重要,看 paper 才知道他在做什么,是怎么做到的;而代码则提供了一个验证以及“偷懒”的机会。(如果没有代码,我怎么知道是作者留了一手,还是我写不出能复现的代码呢?虽然后者概率更大)
ReInspect 是用 Caffe 开源库实现的基于 Overfeat-GoogLeNet 的深度神经网络,用来在图像中检测出重叠严重的密集目标物体。看项目描述就很适合这个比赛的要求。在搭好平台编译调试妥当,验证了原作者示例后,我拿比赛测试用视频作为测试集,发现比第一轮的 HoG 要靠谱多了。于是立马进入下一轮的网络训练,同时也是迁移学习的过程。
事实上 ReInspect 本身也算是迁移学习的成果,因为它的网络权重就是用 GoogLeNet 的网络权重来初始化的。初始化以后,它又用了 11917 幅图进行训练,这一万多幅图中有 91146 个人头部被标定出来用于训练。写了这么多枯燥的文字,贴个图展示下直观的效果:

可以看出 ReInspect 在这个咖啡馆的人头检测效果还是不错的。
相比之下我们用于比赛的测试视频只有 10 来个 3 分钟长短 15fps 的短视频。考虑到连续帧之间差别不大,实际可用于训练的图像也就 10 x 3 x 60 = 1800 张而已(每秒抽取一帧),只有原作者训练集的 15% 左右。
我们知道深度学习的关键点之一就是大数据。没有大量训练数据的支持,再好的模型也可能训练不足,导致其性能不可靠。幸好我们如法炮制了 paper 中原作者的方法:用他现成的网络权重来初始化我们自己的网络,再用我们自己的训练集重新训练。效果真的很不错,而且比训练前的表现又有了大幅提升,以下图为例(比赛签署了 NDA 协议,所以比赛用视频和结果都不能公开,我用互联网上公开的一段尼泊尔地震广场上人群蜂拥的视频做了下测试。图示帧大概出现在视频 03:34 处):

可以看到出在多目标以及目标间有重叠时,经过迁移学习之后的网络表现还是很不错的。(由于比赛只要求检测出可能泄漏隐私的面部——定义比较含糊,我们对于侧脸和后脑勺没有作统一规定,分派给学生做手工标定时没有作同一标准,因此在检测侧脸和后脑时不保证可靠性。)
比较下具体的量化数据:
原作者: 训练集: 11917 幅照片 准确率: ~78%
我们直接以原作者训练结果初始化后训练结果:
新结果: 训练集: 1800 幅照片 准确率: ~74.1%
这个准确率是比赛组织方人工给我们统计的,所以可信度比较高。也跟作者者准确度十分接近。考虑到我们的比赛测试视频是在各种不同的场景、更加密集的人流中进行,实际上可以认为我们用更少的数据达到了更好的效果——不仅仅是实际目标检测效果,也包括解决方案从提出到部署完成所需要的人力物力。
相比 GoogLeNet 所投入的海量人力物力,相比原作者上万张图像的标定和训练,我们只花了 1500 张图像的标定和训练,就到达了同样的结果。这也正是迁移学习的优势所在:站在巨人的肩膀上。前人、学界大牛、业界大牛的成果都可以直接为你所用,你只需要少量的数据就可以达成原本需要十倍百倍数据量才能达到的效果。
案例二
Mindef 项目吉普车零件检测。项目背景:由于视频分析挑战赛结果还不错,我们又接手了一个军方项目的计算机视觉部分的任务。保密程度不高,可以简单分享一下。简单来说就是军方需要缩减培训新兵的人手,在维修车辆方面,希望有软件可以指导新手找到对应零部件。这样不需要很多人手亲自指点,而只需要新兵人手一个平板就可以了。
有了上一次项目的经历,对这个任务就显得比较有自信。而且解决方案简直如出一辙,甚至更为简单,因为用于识别物体的 AlexNet 本来就是被设计出来用于识别物体竞赛的。它可以识别 1000 种物体,而项目需要识别的汽车零部件还不到 100 种,可以说是杀鸡用牛刀了。
下面就是经典的 AlexNet 在 Caffe 上的再现:
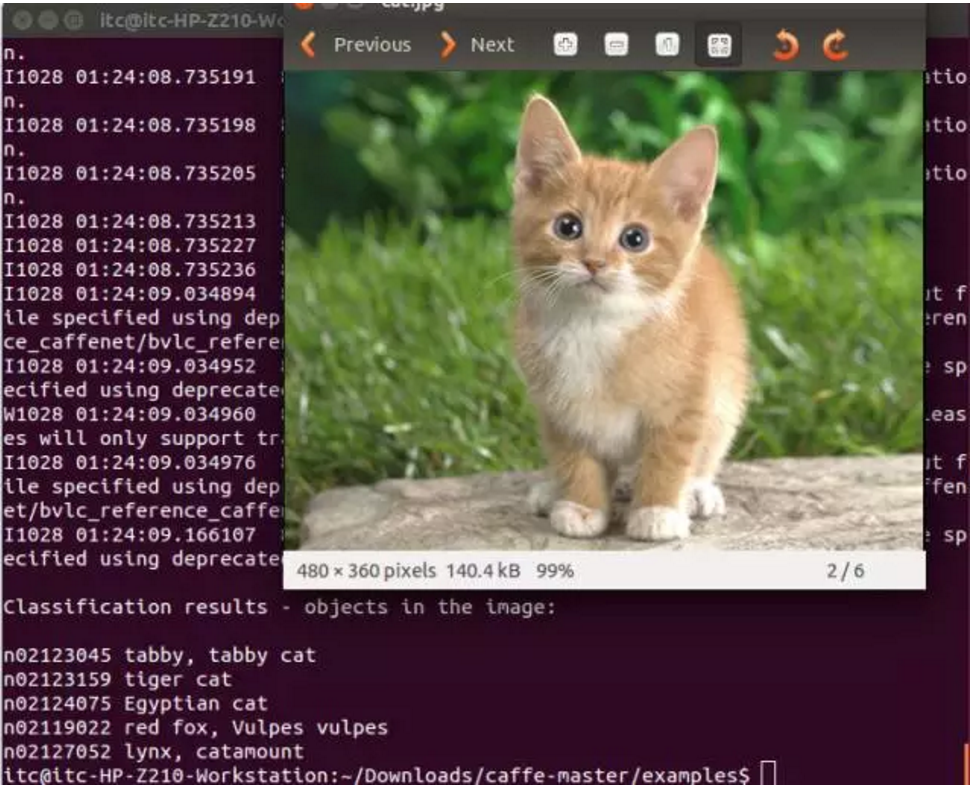
而我们初步交付的就是 5 个不同的零件识别而已。
由于位置和照明的限制,给训练图片采集和实际检测都增加了不少难度。
这里还有一段用 python TkInter 写的一个调用 Caffe 库的简易 GUI,基本用来满足功能需求。
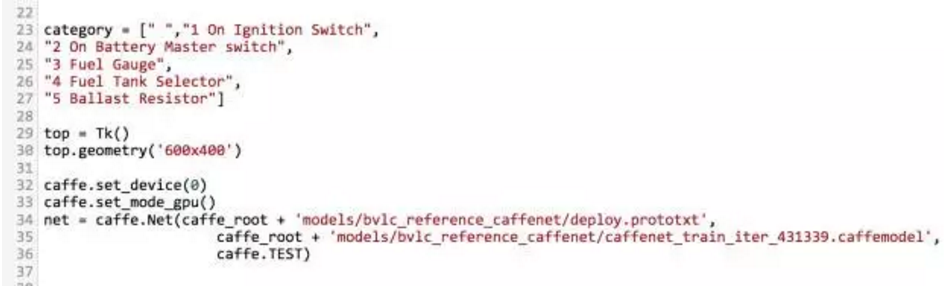
从代码也可以看到我当时用的就是 Caffe 移植的 Alexnet : models/bvlc_reference_caffenet
最终的结果,每个零件我用了不到 100 幅照片来做训练,达到了 90% 左右的准确度。而 AlexNet 则使用了上百万幅照片,即使平摊到 1000 个种类,每个类别也有 1000 幅照片作为训练数据。而且,我们最终节省的不光是采集图片的时间、标定的时间,连后继训练网络的时间也大为缩短。在很短的时间内就能达到可以交付的效果。
总结
上述两个例子都是在作者还不了解迁移学习的时候完成的两个实际项目。按照迁移学习的定义,应该是符合模型迁移的定义的。当然真正研究迁移学习,还有很多深入和细分的技术,如归纳迁移、拜叶斯迁移、继承式迁移等等。文中的两个例子应该属于深度神经网络的模型迁移学习,即使用能够胜任类似任务的深度神经网络模型,并将类似学习训练产生的网络配置用于初始化新任务中的网络参数,以便在更短更快的迭代中获得可靠的训练结果。




