近日,Facebook开源了新的压缩算法 Zstandard 1.0 。据 Facebook 工程师 Yann Collet 和 Chip Turner 介绍,该算法是少数能够在性能和效率方面超过 zlib 的压缩算法之一,而后者当前是“占统治地位的标准”。Facebook Zstandard 利用了 Collet 之前所做的工作。Collet 是 LZ4 的作者,他在 2015 年发布了其新算法的第一个版本。
Facebook 的基准测试显示,在任意压缩率和压缩带宽组合下,Zstandard 的性能都要高于 zlib。
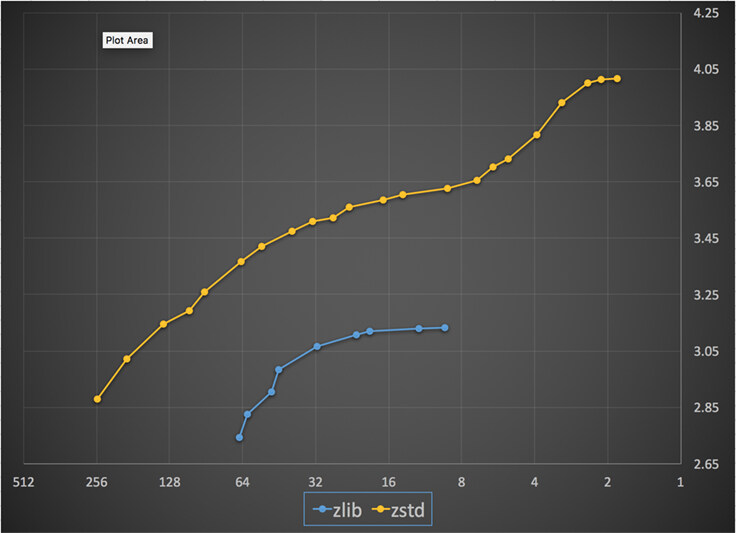
特别地,当使用标准无损压缩语料库 Silesia 时,相比 zlib,Zstandard 展示了出色的性能:
- 在压缩率相同的情况下,它的速度快大约 3 到 5 倍;
- 在压缩速度相同的情况下,它生成的文件小 10% 到 15%;
- 不管压缩率多大,它解压缩的速度都要快 2 倍;
- 它的最大压缩率要高许多(大约为 4 比 3.15)。
Zstandard 使用了有限状态熵,并以 Jarek Duda 在熵编码非对称数字系统(ANS)方面的工作为基础。ANS 的目标是“避免在压缩速度和压缩率之间进行取舍”,它既可以用于精确编码,也可以用于快速编码,并且支持数据加密。但是,从根本上讲,Zstandard 之所以提供了更好的性能是因为它的多项设计和实现选择。
- zlib 受一个 32KB 的窗口限制,而 Zstandard 并没有任何固有的限制,它可以更充分地利用现代环境中的内存,包括移动和嵌入式环境。
- 一个新的 Huffman 解码器 Huff0 。它可以借助多个 ALU 并行解码符号,减少算术操作之间的依赖。
- Zstandard 设法尽量减少分支,从而将因为分支预测错误而导致的、开销很高的管道清理最小化。下面的例子展示了如何在不使用分支的情况下重写 while 循环:
/* 经典版本 */
while (nbBitsUsed >= 8) { /* 每个 while 测试都是一个分支 */
accumulator <<= 8;
accumulator += *byte++;
nbBitsUsed -= 8;
}
/* 无分支版本 */
nbBytesUsed = nbBitsUsed >> 3;
nbBitsUsed &= 7;
ptr += nbBytesUsed;
accumulator = read64(ptr);
- 对于差别只有几个字节的序列,重复码建模极大地改善了压缩。
Zstandard 是使用 C 语言编写的。它既是一个命令行工具,也是一个库。它提供了 20 多个压缩级别,让用户可以根据具体可用的硬件、待压缩的数据和待优化的瓶颈进行仔细地调整。Facebook 建议开始时使用默认级别 3。该级别适合大多数情况。然后,可以尝试 9 以下的级别,合理地平衡速度和空间,或者使用更高的级别获得更高的压缩率,而 20 以上的级别则适合那些你不关心压缩速度的情况。
对于 Zstandard 的未来版本会带来什么特性,Collet 和 Turner 也提供了一些信息,其中包括支持多线程,以及可以提供更快压缩速度和更高压缩率的新的压缩级别。
Zstandard 是继苹果的 ZLFSE 和谷歌的 Brotli 之后的又一个开源压缩算法。ZLFSE 和 Brotli 都是开源的,每一种算法都针对特定的应用场景进行了优化:Brotli 似乎为实现 Web 资产和 Android APK 的高压缩率进行了优化,而LZFSE 的目标是,在压缩率相同的情况下,提供比zlib 更快的压缩速度和更低的电量消耗。
查看英文原文: Facebook Open-Sources New Compression Algorithm Outperforming Zlib




