Netflix 的目标是能预测顾客之所想观看的电影,也即推荐预测。为了做到这一点,每天会运行大量机器学习工作流,而为了支撑创建这么多机器学习工作流和有效利用资源,Netflix 的工程师开发了 Meson。
Meson 是一个通用的工作流和调度框架,它可以跨异质性系统进行 ML 管道管理、执行工作流。Meson 维护构建、训练和验证个性化算法(视频推荐等)的 ML 管道的生命周期。
Meson 的主要目标之一是提高算法实验的速度、稳定性和可重复性,同时允许工程师使用他们自己选择的技术。
机器学习管道的强大面孔
Netflix 当前几种生成机器学习管道的关键角色是 Spark, MLlib, Python, R 和 Docker。
下面来了解下一个典型的视频推荐的机器学习管道,以及它们在 Meson 中是如何表示和处理的。

工作流涉及到如下几点:
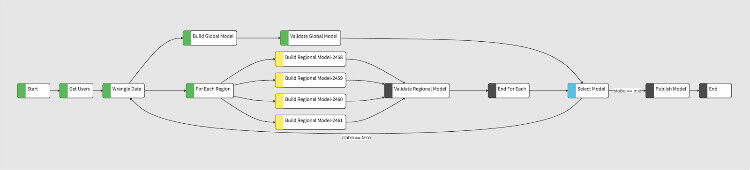
- 选择用户集:通过 Hive 查询来选择用户集来做人群行为分析;
清晰/预处理数据:使用 Python 脚本创建两个用户集来确保并行路径; - 并行路径:一个路径使用 Spark 构建和分析全局模型,并保存到 HDFS 作为临时存储。另外一个使用 R 来构建区域模型。区域的数量是基于人群选择分析而动态变化。在流程图中,Build Regional Model 和 Validate Regional Model 对于每个区域是重复的,运行时扩展,并且以不同的参数集来执行,见下图;
- 验证:Scala 代码用来测试两个并行路径收敛时的模型稳定性。在这步中,如果模型不稳定,我们也需要再返回、重复整个流程;
- 发布新模型:建立一个 Docker 容器来发布新模型,以便被其它生产系统使用。
上图展示了一个运行的工作流(前面描述的):
- 用户集选择和数据预处理已完成,图中绿色部分;
- 流程中的并行路径:
- Spark 分支完成模型生成和验证;
- for-each 分支分出四个不同的区域模型,它们都在运行中,图中黄色部分。
- 模型选择的 Scala 部分已激活,如图中蓝色部分所示。这表明一个或者多个输入分支已完成,但是它仍然没有被调度执行。其原因是输入分支还有未启动或者正在进行的。
- 运行时环境和参数会根据业务策略传递到工作流当中。
深度解密
接下来让我们揭开 Meson 神秘的面纱,去理解 Meson 是如何跨系统运行和生态系统不同组件间是怎样交互的。工作流在运行的过程中有各种资源要求和期望,Meson 是利用 Apache Mesos 来实现的。Mesos 提供 CPU、内存、存储和其它计算资源的任务级别的隔离和抽象。Meson 利用这点特性来实现对任务的高扩展性和容错性。
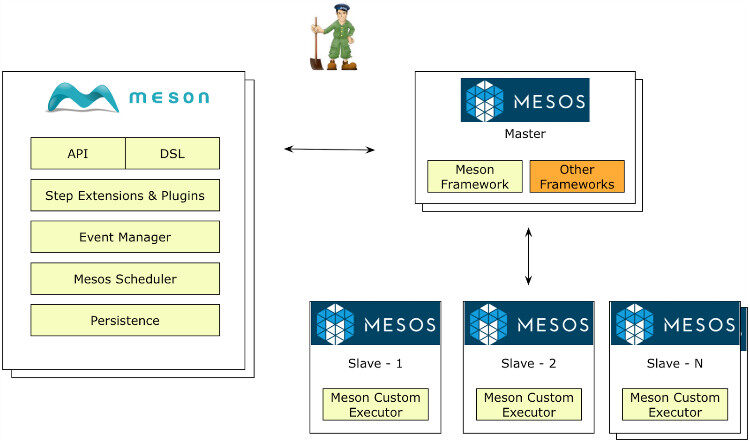
Meson 调度器
Meson 调度器被注册为一个 Mesos 框架,进行管理各种工作流的启动、流控制和运行时。Meson 把实际的资源调度发到 Mesos,包括各种内存和 CPU 要求。Meson 依赖 Mesos 进行资源调度,但是 Meson 的调度器设计成可插入的,所以也可以选择其它框架来做资源调度。
每步一旦被调度,Meson 调度器从 Mesos 申请到实际的资源,并把任务注册到 Mesos master。
Meson Executor
Meson Executor 是一个定制化的 Mesos Executor。写入一个 executor 允许我们保持 Meson 间通讯通道,这对长连接任务(框架消息发送到 Meson 调度器)非常有用。Meson Executor 也使得使用者可以传入定制化的丰富数据,而不仅仅传入一些退出代码或者状态信息。
一旦 Mesos 调度一个 Meson 任务,它会在 slave 端下载所有任务依赖后启动一个 Meson executor。当核心任务被执行,executor 会发送心跳、完成百分比、状态信息等。
DSL
Meson 提供一个基于 Scala 的 DSL,使得开发人员更容易的使用和创建定制化的工作流。下面展示前述工作流是如何使用 DSL 来定义:
val getUsers = Step("Get Users", ...)
val wrangleData = Step("Wrangle Data", ...)
...
val regionSplit = Step("For Each Region", ...)
val regionJoin = Step("End For Each", ...)
val regions = Seq("US", "Canada", "UK_Ireland", "LatAm", ...)
val wf = start -> getUsers -> wrangleData ==> (
trainGlobalModel -> validateGlobalModel,
regionSplit **(reg = regions) --< (trainRegModel, validateRegModel) >-- regionJoin
) >== selectModel -> validateModel -> end
// If verbs are preferred over operators
val wf = sequence(start, getUsers, wrangleData) parallel {
sequence(trainGlobalModel, validateGlobalModel)
sequence(regionSplit,
forEach(reg = regions) sequence(trainRegModel, validateRegModel) forEach,
regionJoin)
} parallel sequence(selectModel, validateModel, end)
Meson 架构扩展
Meson 很容易扩展,增加定制化的步骤和扩展功能,比如,Spark Submit Step, Hive Query Step、Netflix 的微服务或者其它像 Cassandra 的系统。
Artifacts
在 Meson 里,工作流的每步输出都作为“一等公民”对待,并存储为 Artifacts。工作流会根据 artifact id 的存在与否来决定每步的重试是否可跳过。我们也可以通过 Meson UI 来对 Artifacts 进行定制的可视化。比如,存储特征重要性作为一个 artifact,然后插入一个定制的可视化来比较过去 N 天特征的重要性。
Mesos Master / Slave
Meson 的定制化 Mesos executor 是跨 slave 机器发布的。下载所有 jar 包和定制化的 artifact,并发送消息 / 上下文 / 心跳到 Meson 调度器。从 Meson 提交的 Spark 作业共享相同的 Mesos slave 来运行 Spark 作业启动的任务。
原生 Spark 支持
支持原生 Spark 是 Meson 的一个重要要求。 在 Meson 里提交 Spark 作业后可以监控 Spark 作业过程,并能提供 Spark 步骤的重试或者杀死 Spark 作业。Meson 也支持指定 Spark 版本。
Meson 支持具有挑战性的 Spark 多租户环境。Meson 能够高效的利用有限的资源,通过匹配潜在满足资源需求和服务等级协议(SLA)需要的 Mesos slave。也可以对 Mesos slave 标签化分组。
ML 结构
随着 Meson 的使用增加,大规模的并行问题(比如,参数扫描、复杂的 bootstrap 算法和交叉验证)也出现了。
Meson 提供一个简单的‘for-loop’ 结构,它允许数据科学家和科研人员在成千上万的 docker 镜像中表达参数扫描算法。这个结构的使用者可以实时的监控成千的任务过程,通过 UI 找到失败的任务,打印日志到一个位置来简单的管理并行任务。
结论
Mesos 在去年已经完成多 ML 管道的成百上千的并发作业。它能提高算法团队对推荐算法的效率。
Netflix 后期计划在几个月后开源 Meson。
英文原文: Meson: Workflow Orchestration for Netflix Recommendations
译者介绍:侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata_ny 分享相关技术文章。




