Pivotal 在上周(译者注:这篇新闻发表于 2015 年 9 月 25 日)的 SpringOne2GX 会议上宣布了对其大数据产品 Spring XD 进行了完全的重构,并且给予它一个新的品牌名称 Spring Cloud Data Flow . 这个新产品将可执行的应用作为其模块基础,并且聚焦在这些应用的编排上。虽然新产品从 Spring XD 那里保留了高层的 REST API、shell 和 UI,从而保证了后向兼容,但新旧产品的底层却大不相同。
Spring XD 中基于 Zookeeper 的运行环境不见了,取而代之的是服务提供总线(SPI :service provider interface),SPI 在其它系统中也有应用,如 Pivotal Cloud Foundry 、 Lattice 和 Yarn ,主要用做微服务应用的加载、扩展和监控。迄今为止 SPI 的应用案例包括,Lattice 系统中使用 receptor API 来加载模块,以及 Cloud Foundry 中 cloud controller API 的使用。当然,它也有运行在进程中的本地实现,这和老的XD 产品中的单节点运行比较类似。
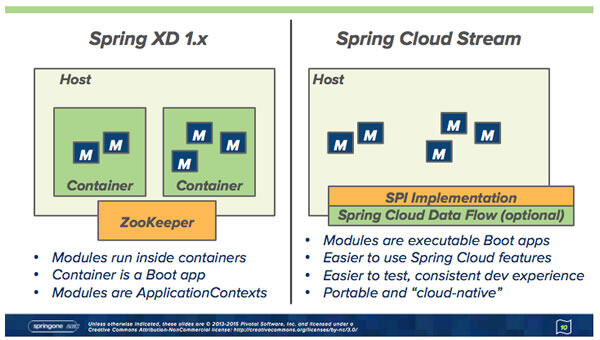
“在这个变化的过程中一个基本理念是我们保留了许多高层的API”, Pollack 在会议中讲到,“但是在这个下面我们进行了巨大的重构以克服那些我们已经发现的根本性的限制。”
这些限制包括了扩展能力、金丝雀部署(Canary Deployments,通过路由策略选择性地对部分用户发布新功能)、资源分配(比如不同的模块分配不同的内存)、分布式追踪(distributed tracing)等等,这些都是目前产品的架构所无法满足的。另一些限制则是和经典父子类加载器体系(parent-child classloader hierarchy)的使用相关,与之相反,如果你使用的是隔离的微服务应用架构,就可以使用扁平的加载器(flat classloader)。
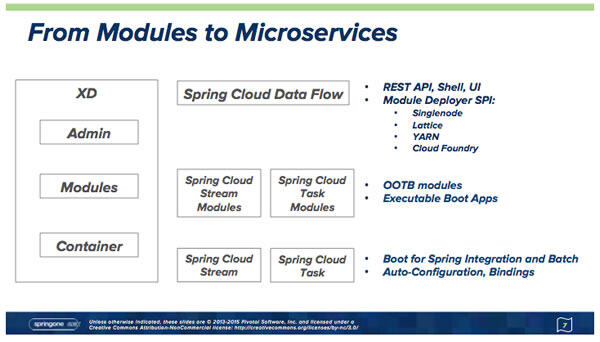
为了解决这个类加载器的问题,现存的集成模块和批处理模块已经被重构,成为使用隔离扁平加载器(isolated flat classloaders)的可引导的Spring 应用(Spring Boot apps) 。实际上,这个设计使得流处理和批处理应用以微服务的方式运行,而这些微服务可以独立的演进。即使没有Spring Cloud Data Flow,这些微服务模块也可以独立运行,因为本质上它们就是Java 的Jar 包,但data flow 可以帮你解决很多乏味冗长的工作,比如属性配置等。还有一些其它的好处,比如相比之前基于Zookeeper 的XD 容器架构,现在可以以更直接的方式来编写这些独立模块的单元测试程序。上面这些优点可能会开启新的市场机会,并触发更多的社区贡献。
在可引导的模块下面是两个新的项目:Spring Cloud Stream 和Spring Cloud Task,创建这两个项目的目的是为Spring Integration 和Spring Batch 分别提供自动配置的能力。
为了能对这个编程模型有些理解, 可以参考下面这段代码, 它来自Mark Fisher 和Dave Syer 的第二次演讲, 实现的是流入信道适配器, 代码使用了标准的Spring Integration 注解(annotation),缺省情况下Spring Integration 每秒钟会去调用它:
@EnableBinding(Source.class)
public class Greeter {
@InboundChannelAdapter(Source.OUTPUT)
public String greet() {
return "hello world";
}
}
@EnableBindings(Source.class) 这个注解将会检测你在类路径(classpath)上实现了什么样的绑定器(binder),然后会用这个绑定器来创建信道适配器。它有一个接口类型的参数,Source、Sink 和 Processor 是已经定义好的,你也可以定义其它的。这个示例中,Source 自身仅仅是一个消息信道接口:
public interface Source {
@Output("output")
MessageChannel output();
}
@Output 注解用来标识输出信道(离开这个模块的消息),而 @Input 则用来标识输入信道(进入这个模块的消息)。信道可以被一个可选的名称来参数化 - 如果没有这个信道名,那么就会用它的方法名来代替。
与 Source 对应的 Sink 是独立的进程,我们本可以跑更多的这样的进程,比如 10。Sink 会监听与另一个中间件间的集成信道,并且当有消息时被激活:
@EnableBinding(Sink.class)
public class Logger {
@ServiceActivator(inputChannel=Sink.INPUT)
public void log(String message) {
System.out.println(message);
}
}
从示例来看,Spring Cloud Data Flow 象粘合剂一样,致力于将这些应用部分串到一起。目前,它的一个里程碑版本已经可以使用。
查看英文原文: SpringXD being Re-architected and Re-branded to Spring Cloud Data Flow




