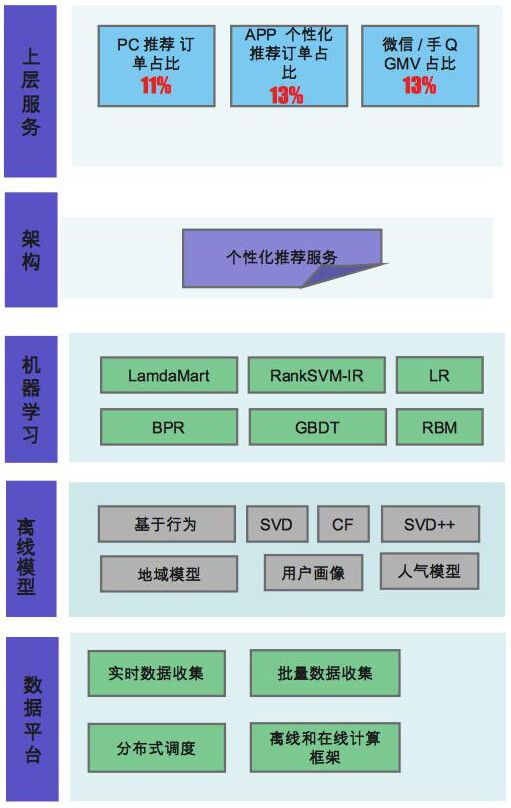
写在前面:京东作为国内最大的自营 B2C 平台,目前个性化推荐成交的订单数已占到总量的 13%。这其中,数据驱动的个性化推荐系统发挥着越来越重要的作用。在 7 月 17~18 日即将举行的 ArchSummit 深圳 2015 “电商和零售业的转型”专题论坛上,京东推荐搜索部技术总监刘尚堃也将分享《京东数据驱动下的个性化推荐》。在一年一度的“6·18”大促销活动到来之际,InfoQ 走进京东,带你领略背后的技术之谜。
受访嘉宾介绍:刘尚堃,京东推荐搜索部技术总监。2011 年加入京东组建了京东搜索团队,2013 年在继续负责搜索引擎相关工作的同时,开始组建广告算法团队,通过一年的算法优化,京东快车广告系统为公司过亿的收入。2013 年年底负责京东推荐系统和搜索系统包括架构、算法、产品在内的全部工作。2014 年带领团队全方位向千人千面推荐和搜索产品目标迈进。
InfoQ:首先请介绍下自己及您的团队所负责的事情。
刘尚堃:我 2011 年初加入京东,开始组建搜索团队,并带领团队用 C++ 研发了一套分布式搜索引擎,在此之前京东的搜索是基于开源系统构建的。2012 年底系统上线之后,京东的转换率有 2%的提升,性能提升了 100%。在这个过程中团队也得到了磨练。2012 年开始组建了广告团队,并开发了”京东快车”,2013 年年中该广告系统已经给京东创造了上亿元的营收。在后来的对比中发现,京东 45% 的品类点击超过淘宝。2014 年广告团队剥离出去独立运作,我开始负责搜索和推荐团队,现在部门有大概 80 人的规模。
InfoQ:您能介绍一下京东的分布式搜索引擎系统的开发过程及其系统架构吗?
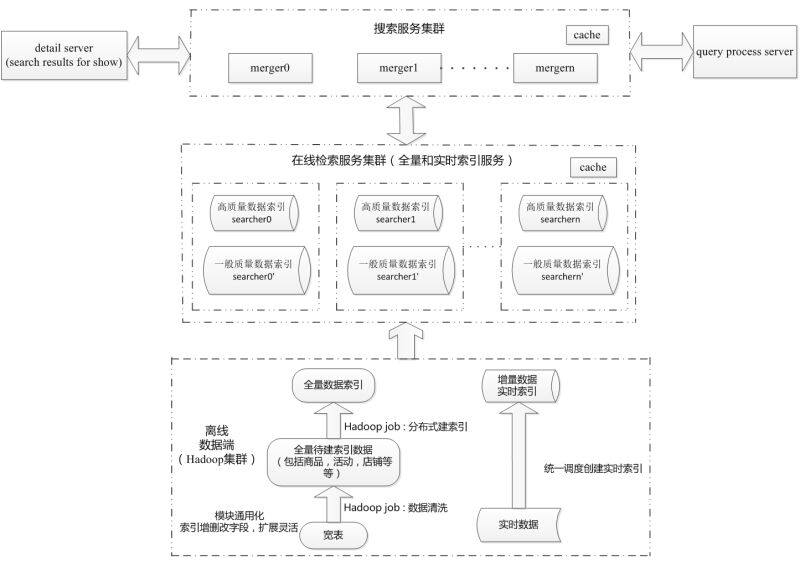
刘尚堃:简单说一下吧。如上图所示,从上到下。首先是搜索引擎的前台部分,有一个意图分析的模块对用户的类型以及请求 query 进行分析。然后进入搜索过程,搜索分两部分,一部分是业务逻辑层,一部分是分布式的 search 引擎阵列。最下面的是数据更新,全量更新与实时增量更新。经过多年的打磨,现在基于 Hadoop 的数据全量更新每天进行一次,实时增量更新则是滚动进行。我们刚刚采用流水线推送技术进行全量更新,性能比过去提升了 20%。
此外,搜索引擎也会连接到用户画像,对其进行更精准的匹配。接下来就是数据分析的部分了。一般我们每周会进行 3 次小流量的算法改进,主要是对 GMV(Gross Merchandise Volume)和转化率的调整测试。
InfoQ:有一个问题我问过不同的相关公司,也想再问下您,商品推荐、广告推荐与内容推荐有哪些异同?在技术实现上各有什么特点?
刘尚堃:其实商品推荐更侧重用户的购买行为,即把大量的商品定位到海量的人群中去,促成订单的成交,这可以用明确的财务指标来衡量;广告的重点是吸引用户点击,以满足商家的推广与展示需求;内容推荐的衡量比较负责,需要看用户兴趣、内容新颖度、以及点击率等多维度指标。
因此,商品与广告的财务指标更容易激起团队的成就感与激情。
这三者的技术实现是有一些通用的步骤可循。以我们京东的推荐系统为例,首先是召回模型,即底层架构和计算平台,比如数据提取、分布式任务的调度与计算等;上面是离线模型,主要是对用户画像、协同过滤以及关联度匹配,这一层用户实时行为对结果的影响更大;再之上是排序模型部分,主要是规则排序、机器学习等。比如我们近期上线了 leaning to rank 对排序优化提升了 20%;再之上是 A/B 测试的框架以及业务架构。
广告推荐更类似于离线部分以及排序里的 CTR(Click-through Rate)预估。有一个很大的不同在于,广告系统里的产品池远小于商品推荐的规模,因此更侧重 RPM(注:广告请求每千次展示收入,(Estimated earnings / Number of ad requests) * 1000),客户关注的是 ROI(Return On Investment)。
InfoQ:京东快车系统在持续优化的过程中,遇到了哪些比较有代表性的或者说有意思的问题?这些问题是怎么解决的?
刘尚堃:现在广告系统叫”精准通”。2014 年之后独立运作了我了解不多,我说一下 2014 年之前的吧。我们广告系统刚上线的时候,广告商品的库存量比较小,这时候定向投放的相关性会比较差,但是又不能过度增加其曝光量,否则会破坏京东用户的体验。为了保证二者的平衡,我们采取减少曝光、保证用户体验和广告主利益,但是牺牲了部分收入的做法。
这类似于”饥饿营销”,也源于我们当时的谨慎。由于精准度较高,商家的热情一下子被拉起来了。但是广告资源有限,后期随着广告资源的不断丰富,我们才逐渐放开了这个限制。
InfoQ:今年 QCon 北京的时候我们就深度学习方面的内容采访了一下李成华博士。您能否谈谈深度学习 / 机器学习在京东现有业务系统中的应用?
刘尚堃:现在深度学习的主要应用是智能机器人方面,我们团队有一位从 Google 过来的博士在做。客服机器人第一步是对用户的问题与 20 多个大类进行匹配是最难的,这一步主要用了很多 DNN(Deep Neural Network)的算法。
InfoQ:作为一个用户量超大的网站,您所负责的系统架构有没有经过大的调整或重构?
刘尚堃:现在更多的是只对系统的痛点部分进行改进。比如,以前全量数据传输比较慢,我们后来用流水线推送进行改进。我们更像是在高速公路上一边跑一边随时随地换轮胎。每次的改进都是一次突破,所有的优化都是立足在架构层面的,比如使得我们的调用更加透明、系统性能更为稳定,使业务开发更加迅速。底层的优化根据我们的具体需求在持续地改进。

InfoQ:在最近这两年的 618 活动中,千人千面计划的实施取得了哪些突破?618 活动对系统和你的团队有哪些挑战?
刘尚堃:京东的 618 可能有点不一样。千人千面作为用户画像的部分,在促销活动中所起的作用主要是对商品的排序。
目前这已经是我第五次做 618 这样的活动了。这个跟你们理解的不大一样,该做的事情平时和 618 之前我们都做完了,团队已经成长起来,我们也都习以为常。否则我也不能坐这里接受你们的采访,而应该在上面忙活着。
InfoQ:明天就是 618 了,您所负责的推荐与搜索系统对历次 618 活动的销售预测情况如何?有什么可以透露的消息吗?
刘尚堃:谈到技术,说的最多的是我们要扛过去啊,其实这是对系统最基本的要求。技术的支撑作用是毋庸置疑的。
现在技术更主要的是推动作用。我们的工程师针对今年的 618 开发了一个促销搜索的 PC 端产品,可以对促销商品的真实性、优惠力度、排序等比较接地气的功能,这里面技术实现了很多。
我们对 618 的原则是,只要能卖出去就不怕赔。今年的预测应该会超过去年淘宝的双十一。到时候在 ArchSummit 深圳 2015 大会上我在给大家做更详细的分享。




