Google 最近发布了一篇名为“ Google 使用 Borg 进行大规模集群的管理”的论文,披露了这个在过去极少提及的技术的细节。
Borg 是一个集群管理器,它负责对来自于几千个应用程序所提交的 job 进行接收、调试、启动、停止、重启和监控,这些 job 将用于不同的服务,运行在不同数量的集群中,每个集群各自都可包含最多几万台服务器。Borg 的目的是让开发者能够不必操心资源管理的问题,让他们专注于自己的工作,并且做到跨多个数据中心的资源利用率最大化。下面这张图表描述了 Borg 的主要架构:
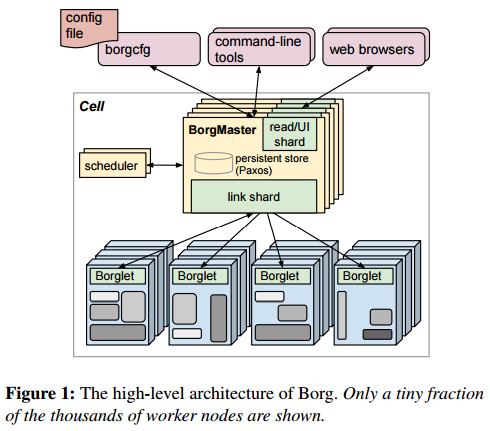
图 1:Borg 的高级别架构图,其中只展示了全部几千个工作节点中很少的一部分。
这套架构中包含了以下组件:
- 单元(Cell) —— 将多个机器的集合视为一个单元。单元通常包括 1 万台服务器,但如果有必要的话也可以增加这个数字,它们各自具有不同的 CPU、内存、磁盘容量等等。
- 集群 —— 一般来说包含了一个大型单元,有时也会包含一些用于特定目的的小单元,其中有些单元可以用做测试。一个集群通常来说限制在一个数据中心大楼里,集群中的所有机器都是通过高性能的网络进行连接的。一个网站可以包含多个大楼和集群。
- Job —— 是一种在单元的边界之内进行执行的活动。这些 job 可以附加一些需求信息,例如 CPU、OS、公开的 IP 等等。Job 之间可以互相通信,用户或监控 job 也可以通过 RPC 方式向某个 job 发送命令。
- Task —— 一个 job 可以一个或多个任务组成,这些任务在同一个可执行进行中运行。这些任务通常是直接在硬件上运行的,而不是在虚拟环境中运行,以避免虚拟化的成本。任务的程序是静态链接的,以避免在运行时进行动态链接。
- 分配额(alloc) —— 专门为一个或多个任务所保留的机器资源集。分配额能够与运行于其上的任务一起被转移到一个不同的机器上。一个分配额集表示为某个 job 保留的资源,并且分布在多台机器上。
- Borglet —— 一个运行在每台机器上的代理。
- Borgmaster —— 一个控制器进程,它在单元的级别上运行,并保存着所有 Borglet 上的状态数据。Borgmaster 将 job 发送到某个队列中以执行。Borgmaster 和它的数据将会进行五次复制,数据将被持久化在一个 Paxos 存储系统中。所有的 Borgmaster 中有一个领导者。
- 调度器 —— 对队列进行监控,并根据每个机器的可用资源情况对 job 进行调度。
Borg 系统的使用者将向系统提交包含了一个或多个任务的 job,这些任务将共享同样的二进制代码,并在一个单元中进行执行,每个 Borg 单元由多台机器组成。在这些单元中,Borg 会组合两种类型的活动:一种是例如 Gmail、GDocs、BigTable 之类的长期运行服务,这些服务的响应延迟很短,最多几百毫秒。另一种是批量处理的 job,它们无须对请求进行即时响应,运行的时间也可能会很长,甚至是几天。第一种类型的 job 被称为 prod job(即生产 job),它们相对于批量 job 来说优先级更高,后者被认为非生产环境中的 job。生产 job 能够获得一个单元的 CPU 资源中的 70%,并且占用所有 CPU 数量的大约 60%,它们还能够分配到 55% 的内存,并占用其中的大约 85%。按照 Google 的研究员 John Wilkes 所说:在单元中混合不同类型的 job,目的在于尽可能地优化资源的使用情况,能够节约 Google 在整个数据中心上的成本 。
根据论文中所写的内容,某些单元的任务量是每分钟接受 1 万个新的任务,而一个 Borgmaster 能够使用 10 到 14 个 CPU 内核,以及 50GB 的内存。一个 borgmaster 能够实现 99.99% 的可用性,但即使某个 borgmaster 或 borglet 出现停机状况,任务也能够继续运行。有 50% 的机器会运行 9 个或 9 个以上的任务,而某些机器能够在 4500 个线程中运行 25 个任务。任务的启动延迟平均时间是 25 秒,其中的 20 秒用于安装包。这些等待时间中的大部分都与磁盘访问有关。
这套系统的主要安全机制是 Linux chroot jail 以及 ssh,通过 borglet 进行任务调试的工作。对于运行在 GAE 或 GCE 中的外部软件,Google 将使用托管的虚拟机,作为一个 Borg 任务在某个 KVM 进程中运行。
Google 还有一个名为 Omega 的集群管理器,这里简单地描述一下 Omega:
Omega 支持多个并行的、特定的“垂直任务”,其中每一个垂直任务基本类似于一个 Borgmaster,只是缺少了持久化存储与连接分片的功能。Omega 的调度器使用了优化的并发控制,对于储存在某个中央持久化储存系统中的单元状态的理想情况与观察到的情况进行操控,这个调度器通过一个独立的连接组件与 Borglet 进行双向同步。设计 Omega 架构的目的是为了支持多种不同的工作任务,每一种都有自己的应用程序特定 RPC 接口,状态机,以及调度策略(比方说,长时间运行服务器、来自于不同框架的批量 job,例如集群储存系统之类的基础设施服务,以及 Google 云平台上的虚拟机)。另一方面,Borg 提供了一种“适合所有情况”的 RPC 接口、状态机机制以及调度器的策略,它们的规模与复杂度随着时间的推移都在不断地增长,其原因是它需要支持多种不同的工作任务。目前来说它的伸缩性还没有遇到什么问题。
Google 在过去十年间在生产环境上所学到的某些经验与教训已经应用在 Kubernetes 的设计上:对属于同一服务的 job 的操控能力、一台机器多个 IP 地址、使用某种简化的 job 配置机制、使用 pods(其作用与分配额相同)、负载均衡、深度反思为用户提供调试数据的方式。参加了 Borg 项目的许多工程师目前也参与了 Kubernetes 这个项目的研发。




