据Gigaom 消息透露,Hortonworks 已将Apache Kafka 加入其Hadoop 软件平台的技术预览版中。尽管Kafka 相对于Spark 在流行度方面稍有逊色,但是它也能够被广泛运用于一些大型互联网公司的应用架构中。同时,它还提供了大数据的云存储、处理和分析等服务,能够应对多种来源和多格式的大数据。Kafka 最初是由LinkedIn 设计的一个高吞吐量、分布式、基于发布订阅模式的消息系统,并可用于将Web 应用消息快速传递到合适的数据服务中。Kafka 集成其他数据服务架构如下图所示:
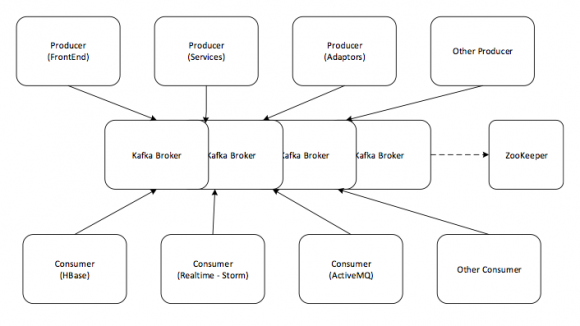
在整合Kafka 之前,Hortonworks 就考虑到了Hadoop 的批处理设计以及广大用户的需求。 于是,Hortonworks 就在其Hadoop 软件平台中集成了Apache Storm 实时计算系统和Spark 并行处理框架,可以看出Hortonworks 在发展大数据技术的同时,正在向快数据技术发展,以迎合那些需要拥有自己大数据基础架构、工程导向的公司,包括已经拥有先进的数据架构的企业,以及新一批的Web 创业公司,甚至包括一些传统企业。
增加对Kafka 的支持看上去似乎是不起眼的举措,Hortonworks 却能籍此与竞争对手(如Cloudera 和MapR 等)形成差异化的优势。尽管Cloudera 和MapR 在自己的产品中也整合了不少开源工具,但它们的收入主要依赖专有软件的授权费用;而Hortonworks 的业务策略是通过推广百分百开源的产品,获取更多用户,并在用户开始大规模部署时收取服务费用。故Hortonworks 看上去对那些需要Storm、Kafka、Spark、Hadoop 等开源技术的客户来说更有吸引力。
另外,据Hortonworks CTO Eric Baldeschwieler 透露,Spark 在不久的将来会取代Hadoop 中的MapReduce,成为大数据生态圈内编写和分享算法的标准平台。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




