在上周的 IEEE/IFIP 可靠系统和网络(DSN)国际会议上,Google 的软件工程师 Tushar Chandra 做了一个关于 Sibyl 系统的主题演讲。Sibyl 是一个监督式机器学习系统,用来解决预测方面的问题,比如YouTube 的视频推荐。
Tushar 主题演讲的题目是“Sibyl:一个用于大规模监督式机器学习的系统”。作为一个靠广告盈利的搜索引擎公司,Google 每时每刻都在千方百计的努力理解用户的行为,从而投放更精准的广告。在不同的场景下,用户对于不同信息的反映是不同的,Sibyl 的目标就是要学习在这些场景下,什么样的信息能够得到最好的用户反映,然后用机器学习模型来计算展示什么样的内容和广告。
这里机器学习技术主要用在改善内容和用户的相关度,帮助网站主改善站点投放广告的强度,避免恶意广告以及改善广告主的回报率等等。而大规模则是指每天一亿次访问。这样量级访问的业务在 Google 这样的大公司里比比皆是,如其搜索,视频,邮件,手机系统,Google+ 等业务。在采用了机器学习技术以后(通常着力于改善算法的准确性),业绩提升有 10% 左右,基本是工业界的最佳实践。
在讲稿中,Tushar 给出了 Sibyl 的系统架构,如下图所示:
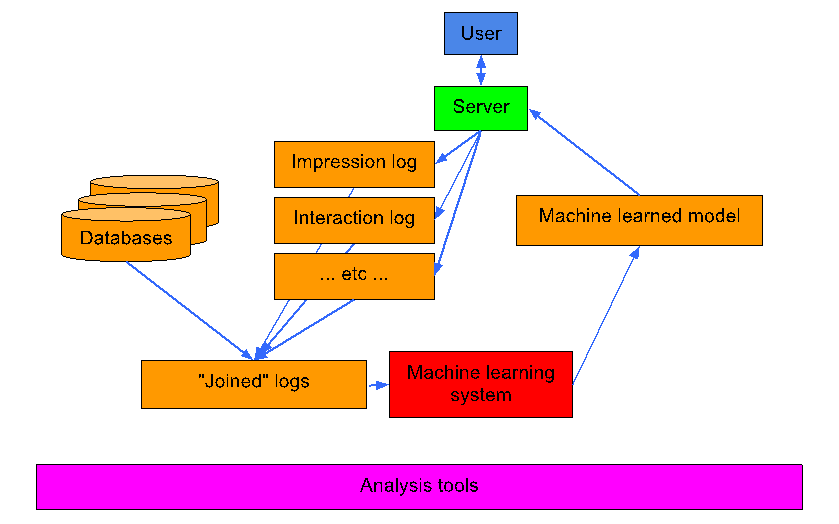
讲稿中还向听众报告了 Sibyl 系统的现状:用了很多理论上很扎实的机器学习算法,如著名的并行 Boosting 算法,还带有很多损失函数以及规范化方法,解决了很多互联网全网量级的问题,使用的资源请求在合理范围内。Sibyl 系统所采用的技术也是业界流行的:在可扩展问题上采用了 MapReduce 技术,在并行计算上采用了多核多线程技术,在海量数据存储上采用了 Google 文件系统(GFS),在数据压缩上采用了面向列的数据格式,在模型训练上充分使用内存(类似 Spark 的思想)。Tushar 还尤其给出了多个业务数据在系统中进行训练的过程和实例数字。
最后,Tushar 对大规模机器学习系统设计做了一些展望,如要有一个清晰的流水线,数据预处理、训练、使用等要隔离,开发可以分析 TB 量级数据的工具,以及加入非监督学习(深度学习之类)的算法模型。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




