上月发布的 Java EE 7 平台包含了批处理编程模型的规范,它很大程度上由 VMware 的 Spring Batch 项目派生而来。上月 Spring Batch 也被广泛提及,因为它发布了一个值得关注的释放版本,这个版本带来了更为简洁的配置和最新的数据访问方式。
Java 平台上的批处理应用程序,也就是 JSR-352,为应用开发人员提供了一个开发健壮批处理系统的模型。这个编程模型的核心是借鉴于 Spring Batch 的开发模式,也就是它创造的 Reader-Processor-Writer 模式,在这个模式中鼓励开发人员遵循面向数据块的处理标准。
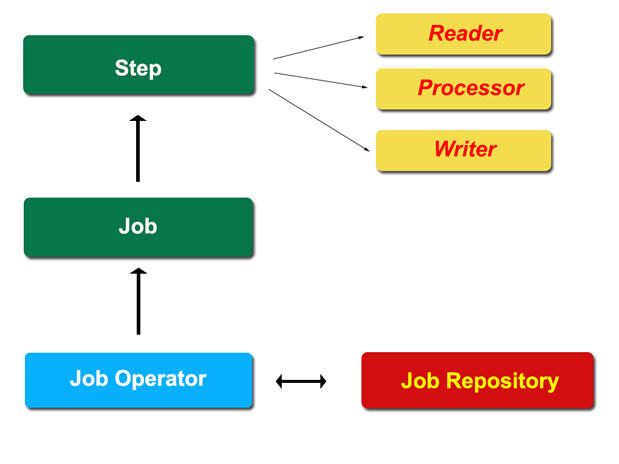
_Reader-Processor-Writer_ 模式可拆分为三个工作流程步骤,要求开发人员去遵循:
- ItemReader_ 类被设计用来消费要处理数据的一个 _ 数据块(通常是一条记录);
- ItemProcessor,业务和领域逻辑会基于 _ 数据块 _ 对其进行处理;
- 最后,记录将会在处理后委托给 _ItemWriter_,然后进行聚集。
按照 JSR 规范,Job_ 要通过 XML 文档进行描述并且包含了处理流程中的 _Steps。每个 _Step_ 负责描述每个 _ 数据块 _ 将要进行怎样的处理以及提交要基于什么样的间隔进行注册。对于流程中某个更为复杂的 _Step_ 处理需求可以通过 JSR-352 的 _batchlet_ 来进行处理。JSR-352 中的 _batchlet_ 对应于 Spring Batch 的 _tasklet_,它提供了处理一个 _Step_ 的策略。
JSR-352 也借用了 Spring Batch 的模式来访问和控制任务。任务要通过 _JobOperator_ 来触发,而任务的结果要通过 _JobRepository_ 进行访问。在 Spring Batch 中,_JobRepository_ 的名字是相同的,而 JobOperator_ 被称之为 _JobLauncher。
与 Spring Batch 定义任务的方式稍有差别,Java EE7 的应用开发人员需要将任务的 XML 文档放到工程的 META-INF/batch-jobs 目录之中。在 Spring Batch 中,开发人员可以将它们的任务配置放在 Spring 应用上下文的任何地方,只要在容器中能够访问到就可以。
Java EE 7 容器的任务 XML 要定义具体的 _Reader_、_Processor_ 以及 _Writer_ 类,除此之外,还有缓冲区的大小、提交的间隔以及检查点策略。检查点策略用于描述提交是如何进行处理的。默认值是“item”,但是开发人员也可以选择将“time”作为提交策略。在前一种场景中,提交间隔描述的是处理过的记录数,而后者描述的是秒数。
<job id="myJob" xmlns="http://batch.jsr352/jsl">
<step id="myStep" >
<chunk
reader="MyItemReader"
writer="MyItemWriter"
processor="MyItemProcessor"
buffer-size="5"
checkpoint-policy="item"
commit-interval="10" />
</step>
</job>
Spring Batch 的任务描述与 Java EE7 基本上是相同的,需要说明的是步骤的定义要包含在 _tasklet_ 指令之中。chunk 配置中的 reader、process 以及 writer 属性引用了应用上下文中已有的 Bean。在 2.2.0 版本中,chunk 配置中的 commit-interval 描述了在进行一次提交之前必须要处理的记录数。
<job id="myJob">
<step name="myStep">
<tasklet>
<chunk
reader="myItemReader"
processor="myItemProcessor"
writer="myItemWriter"
commit-interval="2" />
</tasklet>
</step>
</job>
<bean id="myItemReader" class="...MyItemReader" />
<bean id="myItemProcessor" class="...MyItemProcessor" />
<bean id="myItemWriter" class="...MyItemWriter" />
尽管目前的目标是要与 JSR-352 兼容,但是 Spring Batch 超出规范的一点在于,它为开发人员提供了一种与 Spring 生态系统中其他组件进行无缝集成的方式。在批处理的场景下,Spring Data 可以直接作为 _Reader-Processor-Writer_ 模式中的 _Reader_,从而允许开发人员从 Spring Data Repository 之中查询数据块。同样是在上月发布的 Spring Batch 2.2.0 版本中,为使用 Spring Data 的 MongoDB 和 Neo4j 数据存储,提供了改进后的接口。
除了简化 Reader 接口,最新的 Spring Batch 释放版本为 Spring Java 配置提供了扩展支持,从而可以简化批处理特性。为了启用这个简化的配置,开发人员需要为带有 @Configuration 注解的类再添加 @EnableBatchProcessing 注解。通过这种方式,像 JobRepository 和 JobLauncher 这样的批处理特性就能够直接进行装配,而无需额外的配置。
@Configuration
@EnableBatchProcessing
public class AppConfig {
@Autowired
private JobBuilderFactory jobs;
@Bean
public Job job() {
return jobs.get("myJob").start(step1()).next(step2()).build();
}
@Bean
protected Step step1() {
...
}
@Bean
protected Step step2() {
...
}
}
Spring Batch 2.2.0 除了增强数据获取和配置以外,这个最新的释放版本也将对 Spring 框架的版本依赖升级到了 3.1.2。要使用最新版本 Spring Batch 的 Spring 开发人员在开发批处理应用的时候,需要满足这个最小版本要求。




