2013 年 4 月的 QCon 北京会场上,阿里云计算产品总监倪浩带来了主题为《阿里云计算的实践》的分享。在分享中,倪浩介绍了阿里云的服务体系,技术路线的选择,着重介绍了弹性计算和存储技术的演进,并且在最后介绍了使用阿里云服务的一些最佳实践。
InfoQ 编辑从本次分享中获取到一些有意思的信息如下:
云计算对客户最大的价值是什么?
成本不是关键。事实上,使用云计算有时候反而要比较贵,但是盯着省钱不如盯着赚钱。灵活性(可快速变化)和简单性(易于操作)使得云计算能够更好的为客户交付更多的价值,这才是云计算最大的价值。
为什么阿里云(包括其他大型公共云平台)要选择自己从头开发整个底层软件,而没有在现成的 OpenStack、CloudStack、Eucalyptus、Hadoop、MongoDB 等开源软件的基础上构建?
对于阿里云这样规模的业务而言,如果采用各种开源技术拼凑起来的方案,会缺乏主线的控制力,而且拼凑的过程一点都不简单。同时,各种软件几乎不可能共享集群的资源。
阿里云存储在发展过程中遭遇过哪些坑?是如何解决的?
云存储系统的业务特点在于大量的随机 IO,擦写十分频繁。
阿里云的存储系统,到目前经历过三个阶段。
第一个阶段是最原始的:所有的 VM 访问基于 RAID 的共享存储。RAID 本身并不是为了这种大量随机读写的情景设计的,同时因为 RAID 的数据都在本地,一旦宕机是无法迁移的。
第二个阶段采用了异步同步的思路:VM 过来的运行时读写先进入本地存储,同时以扇区为单位,异步向 KVEngine 做同步,KVEngine 挂在(append)阿里的分布式文件存储系统(盘古)上。这样做的好处是可以取巧的利用(不支持随机读写的)飞天盘古的数据冗余,万一本地宕机可以通过 KVEngine 中的数据在另一台机器上恢复;但是,KVEngine 异步同步数据仍然有丢失的可能。
第三个阶段是:支持随机 IO 的分布式存储系统。跟之前的 append-only 不同,这是基于盘古实现的 Random Access File(RAF)。其实现的思路是:
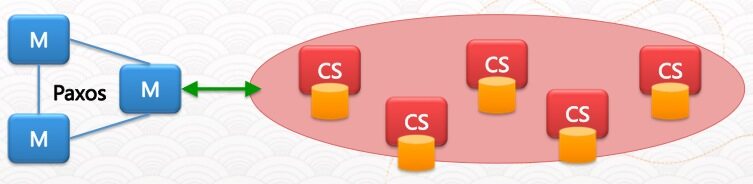
- Master-slave,Master 负责元数据管理,Slave(Chunk Server)负责读写
- 基于 Paxos 协议%E7%9A%84%E5%A4%9AMaster%E6%9E%B6%E6%9E%84">http://en.wikipedia.org/wiki/Paxos_(computer_science) 的多 Master 架构
- 分片(文件切成 chunk 存入 Chunk Server),冗余(每个 chunk 存三个副本)
整个方案最大的挑战在于:如何保持数据一致性。这是所有分布式存储系统面临的最大问题,从理论到实现都非常复杂。
阿里云的服务类型很多,如何选择才能效果最优?
优化云服务用例的根本原则在于:知道每个服务都被设计好做一件事情。
因此,每个服务都有自己的优势,也有自己的陷阱。
比如,阿里云目前提供了不同的存储服务:
- 开发存储服务 (OSS)
- 开放结构化数据服务 (OTS)
- 关系型数据库服务 (RDS)
未来还会提供 Cache/Queue/CDN 等。当然,云服务器(ECS)本身也带有存储。
- 使用 ECS 的存储当然可以,但如果你的读写很重,把压力转移到 OSS、OTS 或 RDS 上才是正途。
- OSS 相当于一个带宽不受限、空间不受限、并发不受限的在线存储
- OTS 适合不需要关系型操作的结构化数据
- RDS 具备优越的读写性能(FusionIO),但总数据量要小于 1TB
网络方面,负载均衡(SLB)提供 HTTP 和 TCP,分别在不同的层面,需要考虑好自己的业务适合在哪一层做。同时,按月购买的服务器的带宽限制是完全的上行带宽(从服务器流出的带宽),下行带宽(流入服务器的带宽)是千兆规格,相当于没有限制。
InfoQ 编辑就一些读者感兴趣的问题跟倪浩进行了询问,他的回答如下:
InfoQ:阿里云部分基于 XEN,那么在 XEN 被 Citrix 收购后,如果社区活跃度下降,后续更新乏力,那么将来如何解决已经采用 XEN 运行的虚拟服务器这个问题?
倪浩:阿里云目前是基于 XEN,也在对 KVM 进行研究。未来如果 XEN 比 KVM 确实距离太大,一定会有方案能够帮助用户在线迁移。
InfoQ:如果阿里云改造后采用了公网地址沉降的办法,即运行虚拟服务器宿主机直接连接到互联网上的话,针对很多中小企业用户对如何设置防火墙以及应保护哪些端口还不是熟悉的情况以及黑客的扫描性攻击状况,如何应对?
倪浩:阿里云是公网下沉,建设大二层网络;同时提供了云盾来帮助用户抵御公网上的各种攻击,包括端口安全检测、密码破解防御等服务,同时云盾还将提供 Web 防火墙,让用户通过 Web 来配置安全策略包括端口及 IP 限制等。
InfoQ:阿里云如何解决镜像迁出的问题,即用户创建了云服务器后,如果用户长成中大企业有可能希望将云服务器移到企业内部 IT 系统上运行,阿里云的镜像格式可以允许用户随意在企业内部的 Linux 或 Windows 宿主机上运行吗?
倪浩:暂时阿里云的镜像还未能支持用户自己下载,未来会容许用户选择导出的格式(如 VHD 等)。
InfoQ:阿里云存储采用 KVEngine 大概是什么时候?采用 RAF 大概又是在什么时候?对用户来说,在 2013 年感受到的 I/O 相比之前几年,能有多大的提升?
倪浩:RAF 是大概一年半之前(2012 年初)上线的。它的主要优势是数据的高可靠性做的很好,但会损失一定的性能。
InfoQ:对于 RAF 的数据一致性实现,能否简单的介绍一下其理论?有哪些参考资料可以推荐么?
倪浩:RAF 的一致性较为复杂,简单的说,是通过 client 与 chunk server、master 通过协同对 chunk 版本的进行管理,其中,client 是协作者(因为对虚拟机来说只有一个 client 会去操作文件),而 master 是最终的版本持久化、版本决策者。
InfoQ:您在 RAF 的实现思路中提到几个需要注意的问题,如流控、复制风暴等,这是怎样的情况,能简单说明一下么?
倪浩:复制风暴是这样的:假设集群有 1000 台机器,在负载较高的情况下,其中有 1 台机器宕机了(每天都会发生),它上面的数据为了高可靠(虽然只是 N 份拷贝中的一份,但少了这台,拷贝数就变为 N-1,可靠性降低),需要被复制到其他 M 台机器上。而这 M 台机器中可能有些机器已经负载很高了,如果不做流控,那么这些机器页可能会被拖死,这样 1000 台机器的集群可能就有 5 台机器宕机。而这 5 台的机器数据又要被复制到其他机器上。如此恶性循环,可能会把整个集群拖死,这就是复制风暴。
InfoQ:阿里云是否会允许第三方合作伙伴在平台上提供类似云盾、云监控的业务?
倪浩:阿里云未来是容许用户在阿里的平台上提供云盾和云监控的业务,模式是会是和云市场合作。




