
统一实时分析与可观测性
如果你已经在使用 ClickHouse 进行实时分析,那么你并不孤单。ClickHouse 已迅速成为企业进行外部或内部分析的首选数据库,支撑着一些最大规模的用户侧分析负载(https://clickhouse.com/user-stories?useCase=1)。传统数据仓库已难以满足现代应用对高并发和低延迟查询的要求,因此越来越多的公司选择了 ClickHouse。
值得注意的是,使 ClickHouse 成为强大分析平台的诸多特性——如高速扫描、高压缩比、对超大数据量和高基数工作负载的出色处理能力——同样也让它非常适用于日志、链路追踪和指标管理。再加上它的开源许可、良好的互操作性、对 OpenTelemetry 的原生支持,以及可用于存储宽事件的能力,这一切共同构成了一个可靠的可观测性基础架构。
关于“可观测性与分析不应各自为营”的理念,并不只是我们的观点。正如 Sierra 的 Arup Malakar 在其近期博客中所言(https://clickhouse.com/blog/sierra-observability-analytics):
“如果我们不再将可观测性和分析视为两个孤立领域,而是当作由像 ClickHouse 这样强大的计算引擎驱动的统一数据问题,那将非常理想。归根到底,它们本质上都是数据,我们需要的只是一种高效访问这些数据的方式。”
—— Arup Malakar,Sierra
随着我们近期发布了 ClickStack(https://clickhouse.com/blog/announcing-clickstack-in-clickhouse-cloud),统一实时分析与可观测性比以往任何时候都更为简单。你只需使用 ClickStack SDK,或任意一个 OpenTelemetry SDK,对你的应用进行埋点,即可立即开始将应用数据与错误、性能指标和问题进行统一关联分析,一切尽在同一平台之中。
本文将通过一个实际示例进行展示:我们将对 ClickPy 进行埋点,这是一个基于 ClickHouse 的应用,包含超过 1.8 万亿行数据,每周处理超过 150 万次查询,借此展示统一分析与可观测性的整个流程有多么便捷。
ClickPy
ClickPy 是我们运营多年的一个项目,允许用户探索 PyPI 上的下载情况。PyPI 是 Python 生态系统的核心包仓库,每天的下载量接近 20 亿次,是一个极具价值的元数据来源,可以揭示开发者最常使用的库。
随着时间推移,ClickPy 的数据集已经大幅扩展。经过数年上线运行,其主表现已累计近 1.8 万亿行数据,涵盖自 2016 年以来的大规模真实 Python 包下载记录。尽管数据规模庞大,查询依旧能保持在亚秒级响应,充分体现出 ClickHouse 在应对高并发、高吞吐量场景下的卓越能力。
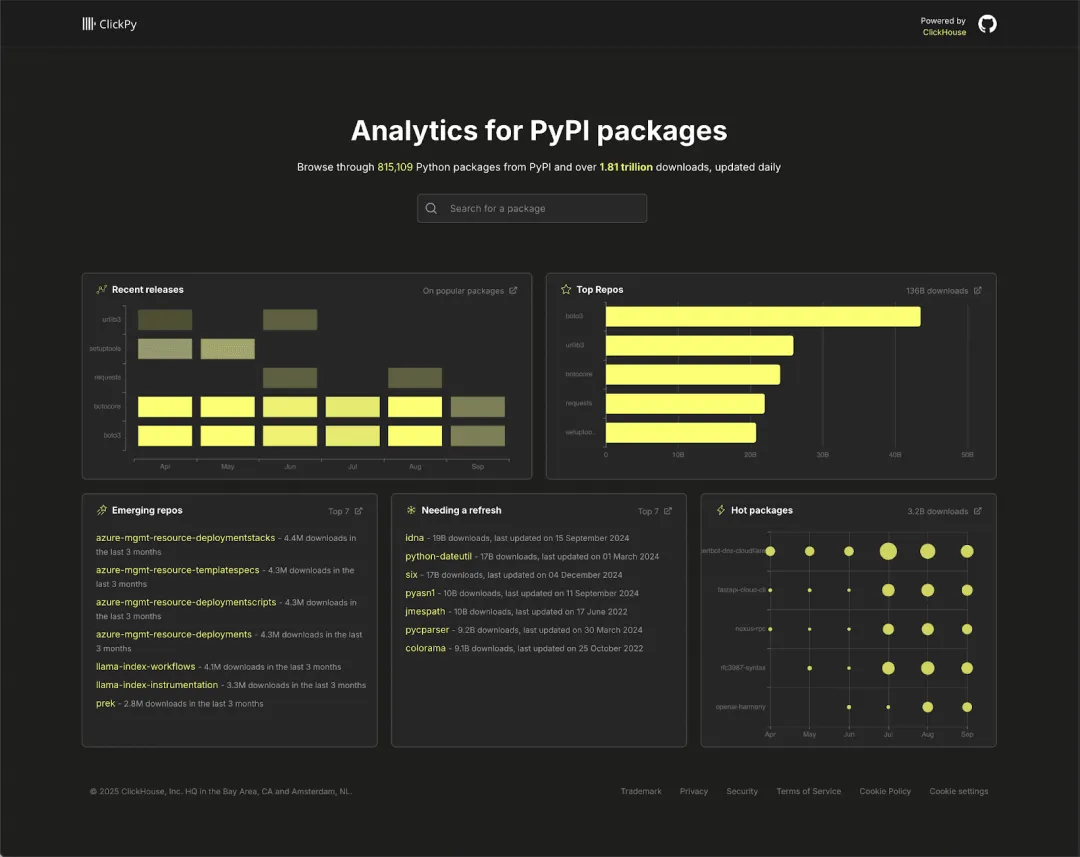
如果你想深入了解 ClickPy 的工作机制,我们推荐阅读去年我们在数据量突破 1 万亿行时发布的技术博客(https://clickhouse.com/blog/clickpy-one-trillion-rows)。
该应用采用简单的技术架构,前端基于 React 与 Next.js,页面数量不多,图表使用 Apache ECharts 实现,查询通过官方 ClickHouse 客户端由 Node.js 服务端提供支持。整体采用 SSR(服务器端渲染)和 CSR(客户端渲染)混合模式:初次加载时,服务端从 ClickHouse 获取数据并作为 props 传递给前端,实现快速响应;图表则由客户端渲染,确保良好的交互性与响应速度。借助物化视图和智能表选择机制,即使在万亿级数据规模下,应用依然能实现快速加载、流畅图表响应和实时探索体验。架构简单使得埋点实施更为便捷,同时应用内部也包含足够多的组件,可以暴露真实问题,是非常理想的性能测试样本。我们希望借此评估是否还存在性能优化空间,或是否存在某些包属性会导致仪表盘加载变慢的情况。
用 OTel 和 ClickStack 进行埋点
ClickStack 将三大核心组件集成于一体:数据库使用 ClickHouse,界面展示采用 HyperDX,数据采集基于 OpenTelemetry。整套架构极为简洁,无需频繁在多个工具之间切换,即可搭建完整的可观测性体系。
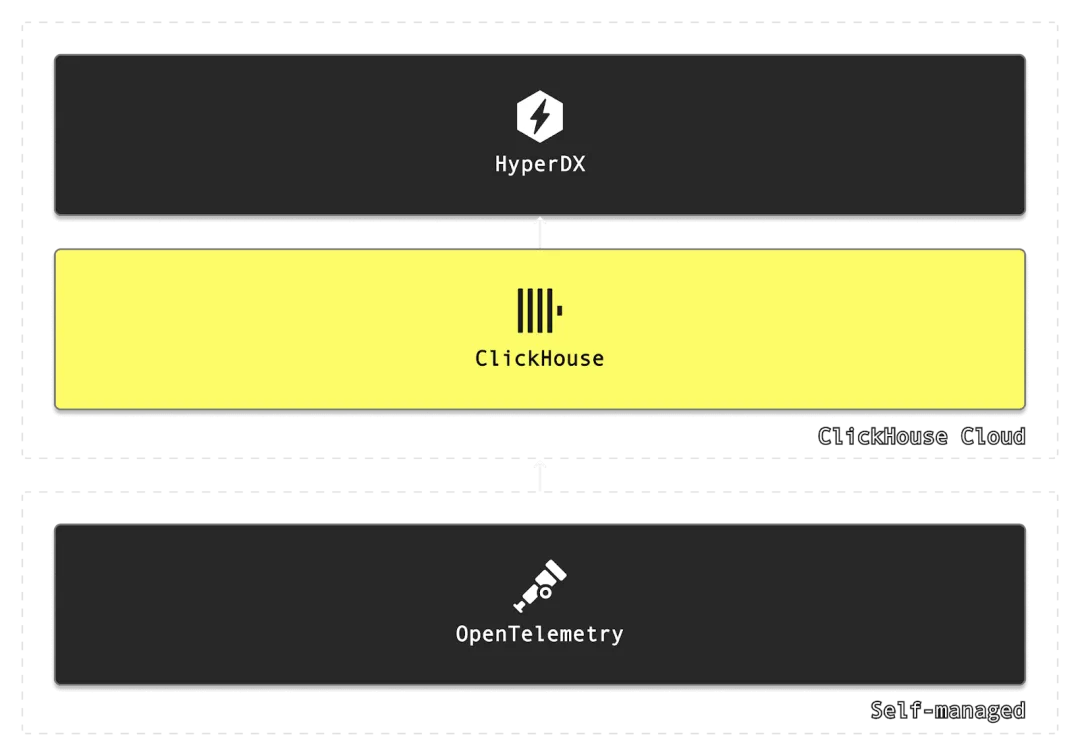
在 ClickPy 项目中,我们主要关注从应用中收集用户会话和追踪信息。用户会话能帮助我们重现浏览器端的真实操作过程,而链路追踪则可以从应用的两个层面收集:一是我们部署在 Vercel 上的 Node.js 服务端代码,二是运行在浏览器中的 React 前端。
关于埋点方式,我们有几种选择:可以直接使用原生的 OpenTelemetry SDK,但 ClickStack 也提供了自家 SDK,能显著提升开发体验。例如,ClickStack 的 Node.js SDK 内置异常捕获功能,并预设了合理的默认配置,使开发者只需几行代码就能快速完成集成。而在前端,ClickStack 的 JavaScript SDK 则可以方便地在浏览器中采集链路追踪信息,并将其与后端数据进行关联;同时还能捕获用户会话,从而实现用户体验的可视化与重放。
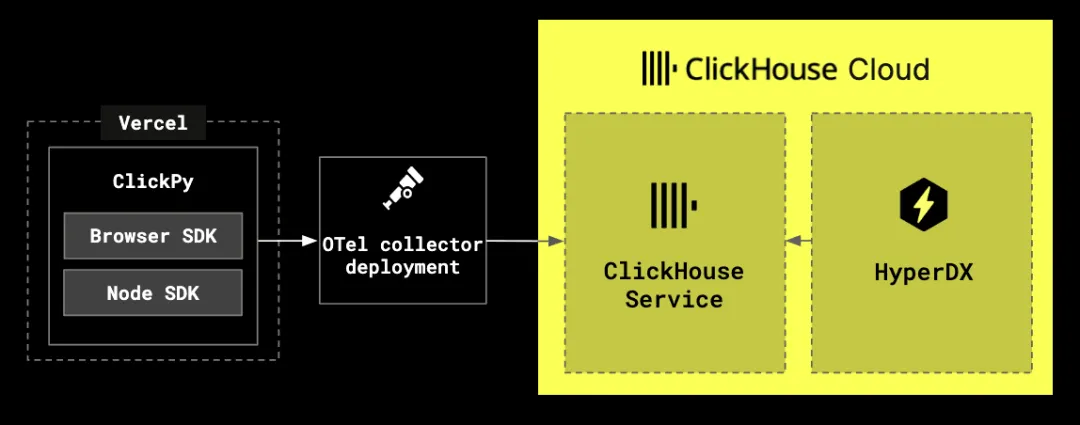
部署 ClickStack
在本地部署 ClickStack 的最快方式是使用一体化镜像,该镜像集成了 ClickHouse、HyperDX 以及 OTel 收集器端点。
docker run -p 8080:8080 -p 4317:4317 -p 4318:4318 docker.hyperdx.io/hyperdx/hyperdx-all-in-one默认情况下,HyperDX 会在本地的 8080 端口对外提供服务。你可以直接访问 http://localhost 打开 UI 页面并创建一个用户,所有数据源也会自动完成初始化。
ClickHouse Cloud
对于使用 ClickHouse Cloud 的用户,目前 HyperDX 正处于私测阶段(https://clickhouse.com/cloud/clickstack-private-preview),如有需求可申请启用。一旦启用,HyperDX 可被用于任意服务,用户无需手动创建账号,认证过程将自动完成。
目前,ClickHouse Cloud 尚未提供原生的数据摄取端点,因此需要用户在本地运行一个 OTel 收集器来接收并转发数据。你可以参考以下命令快速完成部署。
curl -O https://raw.githubusercontent.com/ClickHouse/clickhouse-docs/refs/heads/main/docs/use-cases/observability/clickstack/deployment/_snippets/otel-cloud-config.yaml# modify to your cloud endpointexport CLICKHOUSE_ENDPOINT=export CLICKHOUSE_PASSWORD=# optionally modify export CLICKHOUSE_DATABASE=default# osxdocker run --rm -it \ -p 4317:4317 -p 4318:4318 \ -e CLICKHOUSE_ENDPOINT=${CLICKHOUSE_ENDPOINT} \ -e CLICKHOUSE_USER=default \ -e CLICKHOUSE_PASSWORD=${CLICKHOUSE_PASSWORD} \ -e CLICKHOUSE_DATABASE=${CLICKHOUSE_DATABASE} \ --user 0:0 \ -v "$(pwd)/otel-cloud-config.yaml":/etc/otel/config.yaml \ -v /var/log:/var/log:ro \ -v /private/var/log:/private/var/log:ro \ otel/opentelemetry-collector-contrib:latest \ --config /etc/otel/config.yaml 部署完成后,返回 HyperDX 界面,创建 Trace 和 Session 类型的数据源即可。
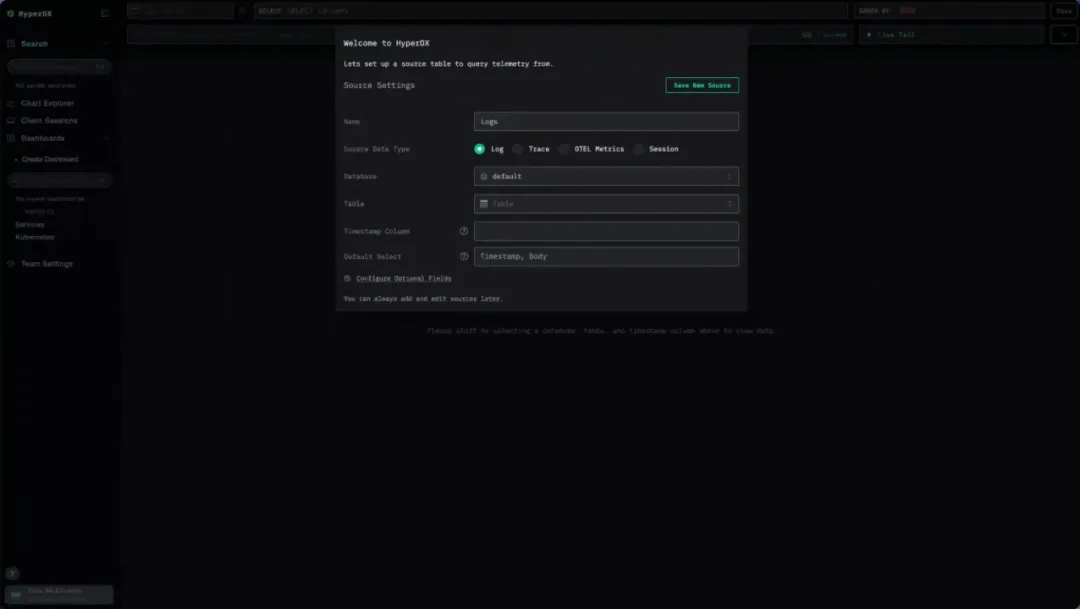
浏览器端埋点指南
我们的 Next.js 应用由客户端和服务端组成。针对浏览器端埋点,我们选择使用 ClickStack 提供的 Browser SDK。虽然你也可以使用标准的 OpenTelemetry SDK(其与 ClickStack 完全兼容),但 ClickStack 的 JavaScript SDK 提供了一个显著优势:支持用户会话重放,同时还内置了控制台日志捕获与 HTTP 请求网络监控等功能,这些特性只需启用一个标志位即可生效。
埋点过程非常简洁,仅需几行代码。首先,安装 SDK 软件包:
npm install @hyperdx/browser随后,我们需要在应用启动时一定会执行的地方初始化 SDK。在 ClickPy 中,我们在 layout.js 中添加了一个 Cookie 同意横幅,它是应用加载的第一个组件,非常适合作为 SDK 初始化的入口。
import HyperDX from '@hyperdx/browser';HyperDX.init({ url: process.env.NEXT_PUBLIC_OTEL_EXPORTER_OTLP_ENDPOINT || 'http://localhost:4318', apiKey: process.env.NEXT_PUBLIC_HYPERDX_API_KEY || '', service: 'clickpy-frontend', tracePropagationTargets: [ /localhost:\d+/i, new RegExp(process.env.NEXT_PUBLIC_DOMAIN || 'localhost', 'i') ], consoleCapture: true, advancedNetworkCapture: true,});注意事项汇总:
服务名称 —— 浏览器生成的 span 会被标记为 clickpy-frontend,方便与服务器端生成的 span 进行区分。
OTLP 端点 —— 默认将 trace 数据发送到本地的 OpenTelemetry 收集器(localhost)。若部署于如 Vercel 等平台,则需通过环境变量 NEXT_PUBLIC_OTEL_EXPORTER_OTLP_ENDPOINT 进行配置。
API 密钥 —— 若使用本地收集器且未启用认证机制,可无需配置 API 密钥。但若 ClickPy 部署在公网上并使用远程收集器,则必须通过环境变量 NEXT_PUBLIC_HYPERDX_API_KEY 提供密钥以完成认证。
控制台与网络请求捕获 —— 启用 consoleCapture 和 advancedNetworkCapture 后,SDK 将自动记录控制台输出及网络请求详情(包括请求头、响应头及消息体)(https://clickhouse.com/docs/use-cases/observability/clickstack/sdks/browser)。
链路追踪传播 —— 此项为实现端到端分布式追踪的关键机制。通过设置 tracePropagationTargets,可确保浏览器发起的请求中携带 traceparent 头部,从而将前端与后端的 span 串联成一个完整 trace,实现前后端协同的链路分析。
在 OpenTelemetry 中,span 表示一个带有时间上下文的操作单元,例如 HTTP 请求或数据库查询,而 trace 是由多个 span 组成的集合,用于呈现一次完整请求或工作流在不同服务之间的传递路径。借助链路追踪传播机制,ClickPy 中前端用户行为(如筛选某个包)和服务端处理流程(如对 ClickHouse 的查询)将统一纳入一个 trace 视图中,便于从整体角度分析性能瓶颈与系统行为。
完成以上配置后,ClickPy 的每一次页面加载、用户操作与浏览器网络请求都将被自动采集,并注入 ClickStack,可与服务端 trace 及日志统一关联分析。
NodeJS 服务端埋点指南
服务端埋点可选方案包括:原生 Node.js 的 OpenTelemetry SDK、Vercel 针对 Next.js 的 SDK、以及 ClickStack 提供的 Node.js SDK(兼容 OpenTelemetry 且内置默认配置)。考虑到 ClickPy 部署在 Vercel 平台,推荐后两者。
本示例采用 ClickStack SDK,其具备内置的 HTTP 请求与响应捕获能力,特别适合 ClickPy 场景:服务端组件通过 HTTP 向 ClickHouse 发出查询请求,SQL 语句通常包含在请求体中,因此完整捕获请求内容尤为关键。
首先需安装相关依赖包:
npm add @hyperdx/node-opentelemetry由于项目使用的是较旧版本的 NextJS(版本 14),还需显式启用埋点 hook。只需在配置文件 next.config.js 中开启相应标志即可。
注:若使用 NextJS 15 或更高版本,可跳过此步骤。
/** @type {import('next').NextConfig} */const nextConfig = { experimental: { instrumentationHook: true, },};module.exports = nextConfig;启用后,在项目根目录(或 /src 目录)创建 instrumentation.js 文件,定义 register 函数用于初始化 SDK,NextJS 会在服务器启动时自动调用。
// instrumentation.jsexport async function register() { if (process.env.NEXT_RUNTIME === 'nodejs') { const { initSDK } = await import('@hyperdx/node-opentelemetry'); initSDK({ service: 'clickpy', // Auto-instruments Next.js + HTTP and captures headers/bodies advancedNetworkCapture: true, // You can add more instrumentations here if you need them later: }); }}通过设置 service 参数,确保所有服务端 span 被标注为 clickpy,便于识别其来源。同时启用 advancedNetworkCapture 后,系统将捕获所有 HTTP 请求与响应的完整内容,包括发送至 ClickHouse 的 SQL 查询,从而实现更细粒度的性能监控。
SDK 其余配置均通过环境变量进行管理。通常需要设置以下四项关键变量,可通过 shell 或 .env.local 文件定义:
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4318HYPERDX_API_KEY=38a8701c-3d72-49f8-8d96-aedaf77d0d55OTEL_INSTRUMENTATION_HTTP_CAPTURE_HEADERS_CLIENT_REQUEST=accept-encoding,host,traceparent,user-agentOTEL_INSTRUMENTATION_HTTP_CAPTURE_HEADERS_SERVER_REQUEST=accept-encoding,host,traceparent,user-agentOTLP 端点地址
API 密钥(可选)
需捕获的请求头字段(用于客户端与服务端)
排除敏感信息,如 Authorization 等
此外,还支持其他可选配置,如对请求或响应体的脱敏处理、限制响应头记录等,以满足不同的安全与合规需求。
扩展埋点功能
虽然 SDK 默认提供了丰富的埋点功能,但在某些场景下,我们仍希望捕获更细粒度的信息。以 ClickPy 为例,我们希望将每条查询与仪表盘中的具体可视化组件建立关联。每个组件具有独立的名称和参数,我们希望将这些上下文信息一并记录。同时,我们还希望捕捉每次 ClickHouse 查询的完整耗时、返回行数及查询配置项。
实现这一目标的最佳方式是在发起查询时手动创建自定义 span,并在查询完成后结束该 span。由于 ClickPy 所有查询都统一通过一个通用查询函数处理,因此集成逻辑也相对简单。
async function query(query_name, query, query_params) { const results = await clickhouse.query({ query: query, query_params: query_params, format: 'JSONEachRow', clickhouse_settings: getQueryCustomSettings(query_name) }) let query_link = `${process.env.NEXT_PUBLIC_QUERY_LINK_HOST || process.env.CLICKHOUSE_HOST}?query=${base64Encode(query)}` if (query_params != undefined) { const prefixedParams = Object.fromEntries( Object.entries(query_params) .filter(([, value]) => value !== undefined) .map(([key, value]) => [`param_${key}`, Array.isArray(value) ? `['${value.join("','")}']` : value]) ); query_link = `${query_link}&tab=results&${Object.entries(prefixedParams).map(([name, value]) => `${encodeURIComponent(name)}=${encodeURIComponent(value)}`).join('&')}` } return Promise.all([Promise.resolve(query_link), results.json()]);}具体做法是在查询函数开始时,调用当前 OpenTelemetry trace 的 startSpan 方法,并在 ClickHouse 查询完成、函数返回前通过 end() 结束该 span。在此过程中,我们将查询响应时间等指标作为 span 属性记录下来。相关代码关键部分如下所示(完整代码请参见原函数(https://github.com/ClickHouse/clickpy/blob/9f4b4bfd6fd9447f5988671904f50a1cf71e231b/src/utils/clickhouse.js#L766-L826)):
xport async function query(query_name, query, query_params) { const span = tracer.startSpan(query_name, { attributes: { 'db.system': 'clickhouse', // Add a short/obfuscated statement if you want. Full SQL can be large/PII. // 'db.statement': truncate(query), 'db.parameters': truncate(safeJson(query_params ?? {})), // ← your params }, }); try { const start = performance.now(); // run the query inside the span's context const results = await context.with(trace.setSpan(context.active(), span), () => clickhouse.query({ query, query_params, format: 'JSONEachRow', clickhouse_settings: getQueryCustomSettings(query_name), }) ); const data = await results.json(); // materialize rows to count const end = performance.now(); // annotate outcome if (span.isRecording()) { span.setAttribute('db.response_time_ms', Math.round(end - start)); span.setAttribute('db.rows_returned', Array.isArray(data) ? data.length : 0); // attach useful customs span.setAttribute('clickhouse.settings', truncate(safeJson(getQueryCustomSettings(query_name)))); } span.setStatus({ code: SpanStatusCode.UNSET }); span.end(); return Promise.all([Promise.resolve(query_link), Promise.resolve(data)]); } catch (err) { if (span.isRecording()) { span.recordException(err); span.setStatus({ code: SpanStatusCode.ERROR, message: err?.message }); } span.end(); throw err; }}通过这一方式,每次 ClickHouse 查询除默认捕获的 ClickHouse.query span(用于记录 HTTP 请求与负载)外,还将新增一个自定义 span,与之并列,从而增强对关键查询过程的可观察性。
数据分析
完成埋点后,ClickPy 应用即可开始采集并分析可观测性数据。应用部署在 Vercel 上,公开地址为 clickpy.clickhouse.com。部署时需配置前述环境变量以启用相关功能。
为接收遥测数据,我们部署了基于 SSL 的 OpenTelemetry Collector 端点。ClickPy 公网实例产生的数据将写入 sql.clickhouse.com 上的演示集群,数据库名称为 otel_clickpy,用户可通过 SQL 直接查询。同时,这些数据也可以在公开的 HyperDX 实例(play-clickstack.clickhouse.com)中可视化查看。trace 信息记录于数据源 ClickPy Traces 中,会话重放信息保存在 ClickPy Sessions 中。
例如,当用户访问 ClickPy,进入某个包页面并应用时间筛选条件时,对应的用户会话将出现在 HyperDX 实例中。用户可以重放该会话,查看交互过程的每个细节,并进一步分析对应生成的 trace 与 span。该过程既可提供用户行为的全局视角,也能呈现每一步操作的性能细节,对于调试、优化及理解实际使用情况均具重要意义。
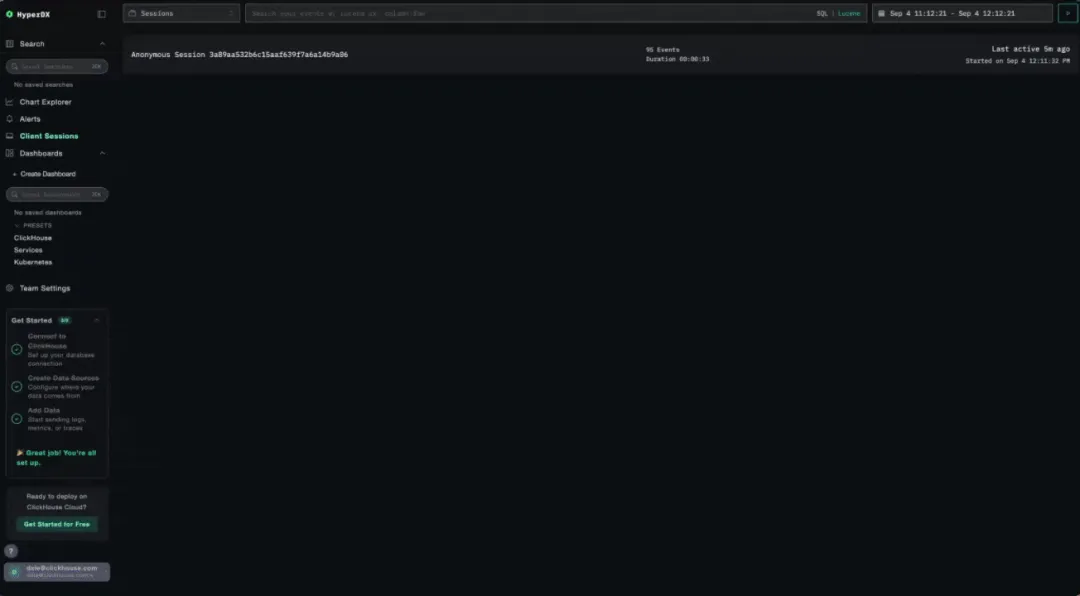
得益于自定义 span 的接入,我们可以深入查看每条 ClickHouse 查询所对应的可视化组件及其具体 SQL 内容,建立明确的可视化与查询映射关系。
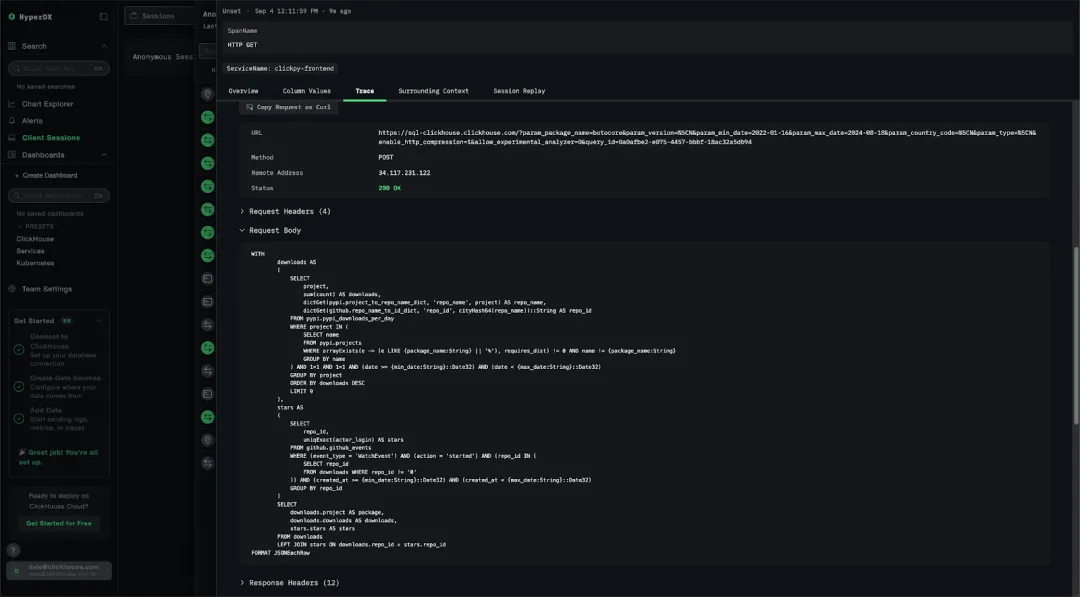
除了针对单个用户的调试分析,我们还可以从更高层次审视整体数据,挖掘潜在模式并找出性能优化点。
ClickStack 的显著优势之一是其灵活性:既支持写时建模(借助 ClickHouse 的 JSON 类型),也支持读时建模。后者意味着即使数据在写入时未定义清晰结构,我们仍可以在查询时利用 ClickHouse 提供的字符串处理函数,从原始文本中解析所需字段。这种按需建模能力特别适合动态或非结构化日志场景。
以包页面访问为例,用户每次进入页面时都会触发一个名为 documentLoad 的 span,其中 location.href 属性记录了页面 URL。通过过滤 span 名称为 documentLoad,并使用 ClickHouse SQL 函数如 splitByChar 提取 URL 中的包名字段,即可分析每位用户访问的具体包,实现基于访问行为的洞察分析。这一过程在查询时构建结构,相当于实现了动态 schema。
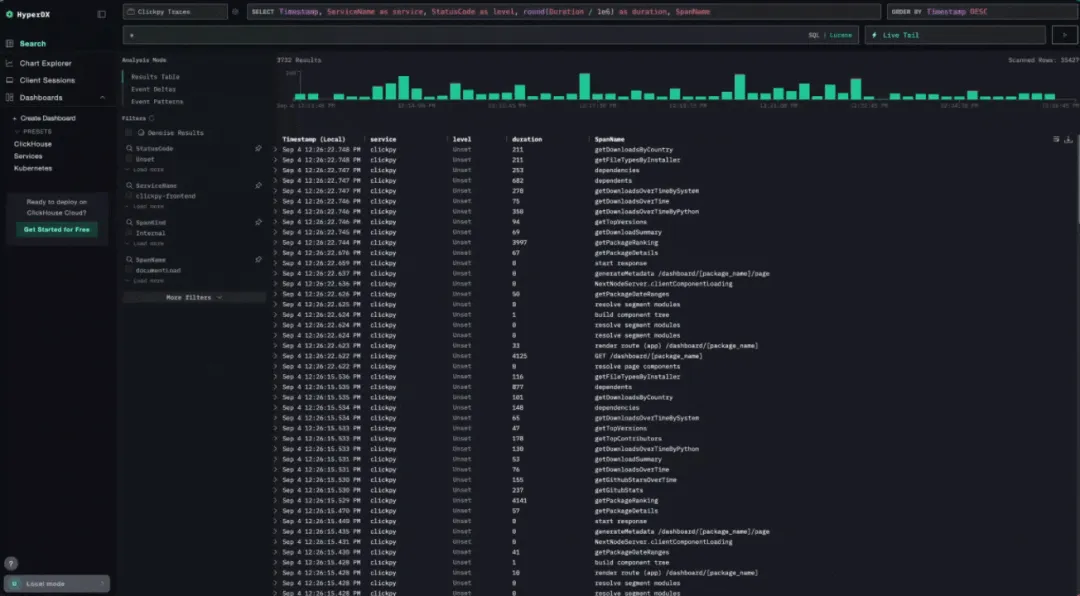
扩展可观测性分析:关联查询与可视化组件
通过为每条 ClickHouse 查询的 span 打上其对应可视化组件的名称标签,我们能够轻松追踪不同组件随时间的性能变化。字段 db.response_time_ms 可用于衡量各类可视化组件的查询开销。下图展示了该指标的时间序列变化,按 SpanName(即组件名称)进行分组统计。
图中可以明显看出,getPackageRanking 查询的开销最高,平均响应时间超过 4 秒。该组件用于展示某个包在下载总量方面的相对排名。
早期我们在用户体验中就注意到该查询存在性能瓶颈。虽然此组件采用异步加载,但通过可视化对比,明确展示出其性能远低于页面内其他组件,从而促使我们对其进行专项优化。
进一步分析不同时间段内各组件的性能表现,也发现了一些严重的延迟波动。这些可视化组件大多来自 ClickPy 首页(clickpy.clickhouse.com),页面中会展示“新兴包”和“热门包”。虽然这些性能波动基本与整体访问量一致,但也引发我们对异常延迟的进一步调查。
由于 ClickHouse Cloud 承载了多个公共演示项目,整体查询负载波动较大,故问题诊断难度也相应提高。此外,用户还可在 sql.clickhouse.com 上对公共数据集执行任意 SQL 查询。这种深度可观测性为我们启动多个性能优化工作提供了数据基础。
可视化之外:将可观测性数据与应用数据关联
除了使用 HyperDX,我们还可以借助其他工具,通过 SQL 对可观测性数据进行更深入的分析。这种方式体现出将可观测性数据视为“普通数据问题”的强大灵活性。
以下示例基于 ClickHouse Cloud 的可视化能力,当然也可通过 Grafana 或 Superset 实现。
一个基础示例:ClickPy 中用户最常访问哪些 Python 包?
我们从 location.href 字段中提取包名,并基于 rum.sessionId 字段统计过去 12 小时内的独立访客数量。
SELECT splitByChar('/', SpanAttributes['location.href'])[-1] as Package, count() as visits, uniq(ResourceAttributes['rum.sessionId']) as sessionsFROM otel_clickpy.otel_traces WHERE Package !=''GROUP BY Package ORDER BY visits DESC LIMIT 20该类简单分析几乎所有可观测性平台均可支持。但若希望进一步将应用行为与底层性能关联分析,传统工具可能力有不逮。
举例而言,我们希望探究:访问更受欢迎的包是否会导致 ClickPy 性能下降?从直觉上看,下载量越大,ClickHouse 中的记录行数越多,查询可能更慢。然而,系统已通过增量物化视图(incremental materialized views)对查询进行了优化:在写入时就完成聚合计算,并借助后台合并,维持每个项目的行数稳定。
增量物化视图会将 SELECT 查询的结果在插入阶段写入目标表。每次有新数据写入时,定义的 SQL 查询立即执行,计算结果直接存储到目标表。这样,查询阶段无需重复计算,响应速度更快。后台合并机制还能周期性地对相同 GROUP BY 键的聚合结果进行合并,确保准确性与效率并存。详细原理可参考官方文档(https://clickhouse.com/docs/materialized-view/incremental-materialized-view)。
要验证“热门包是否加载更慢”的问题,我们需要将可观测性数据与应用数据进行关联分析。
第一步是从应用数据中获取每个包的总下载量信息,可通过物化视图 pypi.pypi_downloads_per_day 实现:
SELECT project, sum(count) AS totalFROM pypi.pypi_downloads_per_dayGROUP BY project在 ClickPy 中衡量包级性能
为了分析包级别的性能表现,我们使用 ClickHouse 中的 db.response_time_ms 字段,即每个查询的平均响应时间。包名信息存储于 span 的属性中,格式为 JSON 字符串。借助 ClickHouse 的读时建模能力,可通过 JSONExtractString 函数提取出具体的包名。
SELECT JSONExtractString(SpanAttributes['db.parameters'], 'package_name') AS project, avg(toUInt64OrZero(SpanAttributes['db.response_time_ms'])) AS avg_performanceFROM otel_clickpy.otel_tracesWHERE JSONExtractString(SpanAttributes['db.parameters'], 'package_name') != '' AND toUInt64OrZero(SpanAttributes['db.response_time_ms']) > 0GROUP BY projectORDER BY avg_performance DESC随后,我们使用 INNER JOIN 将查询响应时间与包下载量的数据进行合并。在 ClickHouse Cloud 中构建散点图,以下载量为横轴、平均响应时间为纵轴,观察包的流行程度与页面或查询延迟之间是否存在相关性。如果系统设计合理,该趋势应较为平坦,而非呈现线性上升。
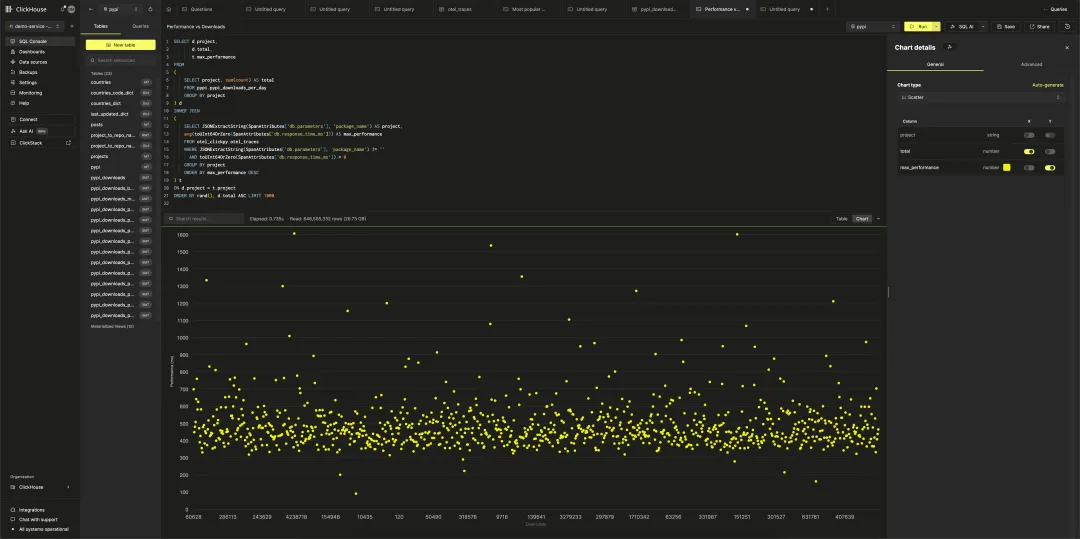
从可视化结果来看,除部分值得进一步研究的异常值外,整体趋势较为平稳,这表明对于数据量更大的热门包,系统查询性能并未明显下降,表现符合预期。
进一步分析中,我们还使用 ClickHouse 的内置统计函数 corr 来计算相关性。该函数用于评估两个数值列之间的皮尔逊相关系数,值为 1 表示完全正相关,-1 表示完全负相关,0 表示不具相关性。
我们在查询中引入该函数,评估包下载量(总计)与两个性能指标之间的相关关系:ClickHouse 查询的平均响应时间与最大响应时间。
SELECT corr(total, max_performance), corr(total, avg_performance)FROM( SELECT d.project, d.total, t.max_performance, t.avg_performance FROM ( SELECT project, sum(count) AS total FROM pypi.pypi_downloads_per_day GROUP BY project ORDER BY total DESC LIMIT 1000 ) AS d INNER JOIN ( SELECT JSONExtractString(SpanAttributes['db.parameters'], 'package_name') AS project, max(toUInt64OrZero(SpanAttributes['db.response_time_ms'])) AS max_performance, avg(toUInt64OrZero(SpanAttributes['db.response_time_ms'])) AS avg_performance, quantile(0.9)(toUInt64OrZero(SpanAttributes['db.response_time_ms'])) AS p90_performance FROM otel_clickpy.otel_traces WHERE (JSONExtractString(SpanAttributes['db.parameters'], 'package_name') != '') AND (toUInt64OrZero(SpanAttributes['db.response_time_ms']) > 0) GROUP BY project ORDER BY max_performance DESC ) AS t ON d.project = t.project ORDER BY rand(), d.total ASC LIMIT 1000)分析结果表明,两者之间仅存在较弱的相关性。
结语
使用 OpenTelemetry 和 ClickStack 对应用进行埋点非常简便,仅需少量代码即可实现,但带来的效果却是深层次的性能与行为分析能力。通过 trace 和会话重放数据流入 ClickHouse,能够快速识别慢查询、定位异常,并实时了解终端用户的真实使用体验。
更关键的是,ClickStack 提供的能力远超传统可观测性工具:由于分析数据与可观测性数据共存于同一个 ClickHouse 引擎中,使得应用层指标(如包下载量)可以与系统性能指标(如查询延迟)直接关联。这种统一的数据视图使可观测性问题真正转化为一个数据建模与分析问题——而 ClickStack 正是为此类需求量身打造的解决方案。
本文主要聚焦于 trace 分析,日志系统尚未涉及。在后续内容中,我们还将介绍如何在 ClickStack 中采集并关联日志,与 trace 数据结合使用,在调试与系统分析中发挥同等强大的作用。
/END/

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出 &图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com。






