
引言
企业 AI 团队长期面临着一个难题,那就是大多数检索增强生成(RAG)系统要么擅长结构化的数据查询,要么擅长文档检索,但当两者需要同时使用时就会无能为力。比如财务分析师提出“为什么欧洲业务表现不佳?”这类问题时,既需要 SQL 数据库中的结构化数据(营收、利润率、员工数量),也需要非结构化文档(市场报告、竞争分析、监管文件)。现有 RAG 系统往往会返回缺少监管上下文的营收数据,或给出缺乏量化校验的市场报告,最后仍需分析师手工补齐。当前 RAG 方法把这些模式当成彼此独立的问题,迫使工程师要么构建定制的编排层,要么接受不完整的答案。
本文将探讨如何通过分层多智能体编排解决这一“模态鸿沟(modality gap)”问题,并以 Protocol-H 作为参考实现来说明这些概念如何落地。文中讨论的模式,也就是带有自主纠错能力的 supervisor-worker 拓扑,建立在 LangGraph/LangChain 的 agentic 模式之上,类似 xAI 和 Databricks 等团队采用的方法。配套的开源代码展示了这些模式如何在 Docker/K8s 环境下实现企业级部署;读者也可在自己偏好的框架中复用同样的架构原则。
本文中的架构基于参考实现和面向生产环境的企业数据集实验。为了聚焦架构模式而非某个特定系统的具体实现,一部分部署细节做了泛化处理。
模态鸿沟问题:为什么传统 RAG 无能为力
传统 RAG 系统通常是线性的流水线:向量化用户问题、检索文档、交给 LLM、生成答案。它在文档中心型的问题上表现尚可,但在企业多模态数据环境中就无能为力了。
以客户流失分析为例:“哪些客户群体流失率最高?结合工单看常见原因是什么?”这个问题执行如下步骤:
结构化推理(SQL):连接客户、交易和流失表,计算群体的流失率。
语义推理(向量检索):检索与流失语义相关的支持工单。
跨模态汇总:将 SQL 结果与文档洞察进行关联,识别因果关系。
大多数 RAG 系统会尝试“一次性完成”:
查询 → 向量检索 + SQL 查询 → LLM → 答案
但是,结果往往是不完整甚至幻觉化的答案,原因包括:如果预先固定检索路径,开发者必须首先决定查询哪些 SQL 表、检索哪些文档,这常常会漏掉关键的数据;上下文窗口有限时,即使检索到了相关的结果,也可能无法在单次 LLM 推理中实现完整的汇总;初始 SQL 可能会找到高流失群体,却遗漏关键工单;缺乏重试机制(比如,迭代修正)时,系统会直接基于不完整的信息作答。尤其当结构化与非结构化信号冲突时,LLM 仍会给出“看起来很自信”的答案。
真实影响
在针对三家金融服务场景的内部评估中(Q4 2025,大约 1500 条多跳查询),约 30%的案例出现“静默失败”:即答案表面权威,但遗漏了超过 20%的相关数据点(比如,绩效分析中缺失监管上下文),且推理路径不透明,不利于审计。
这正是需要分层 Agentic 推理的原因。
分层 Agentic 解决方案:架构总览
Protocol-H 引入了受组织层级与人类问题求解方式启发的 supervisor-worker 拓扑结构:
就像管理者会先把专业分析分派给数据分析师(SQL)和研究员(文档)再汇总结论一样,supervisor 负责拆解问题,worker 负责执行各自模态的任务。
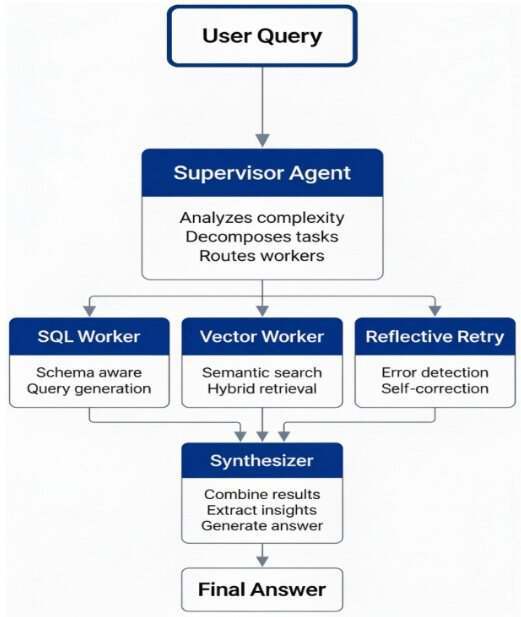
图 1:Protocol-H 架构。supervisor 将查询路由到专用 SQL/向量 worker,并借助 reflective retry 进行纠错,其设计灵感来自组织层级(来源:Protocol-H仓库)。
这里的核心在于基于编排进行专业化:每个 worker 专注自身的模态(SQL 或语义检索),supervisor 负责管理推理流并处理复杂的多跳(multi-hop)场景。
组件详解
Supervisor 智能体:元认知编排器
Supervisor 是系统的推理中枢。它不直接执行查询,而是扮演策略的指挥者。
核心职责:
查询分析:判断问题需要 SQL、语义检索,还是两者都需要。
任务分解:把复杂问题拆成原子步骤(例如“先找欧洲客户,再取其工单,再与流失数据关联”)。
Worker 路由:基于任务与当前状态决定下一步由哪个 worker 执行。
结果综合:将各 worker 输出整合成连贯的最终答案。
错误管理:检测失败并触发 reflective retry。
实现模式:
def supervisor_node(state: AgentState) -> Dict[str, Any]: """ Supervisor routes queries to appropriate workers. Returns structured decision with: - next_worker: "sql_agent", "vector_agent", or "FINISH" - reasoning: Explanation of routing choice - task_description: Specific instruction for worker """ # Analyze conversation history and current state supervisor_prompt = """ You are an enterprise data reasoning expert. Given this question and what you know so far, decide the next reasoning step. Current question: {current_question} Results collected so far: {results_so_far} Decide: Do we need SQL query results? Document search? Or can we synthesize a final answer? Respond with: next_worker, reasoning, task_description """ # Parse LLM response to structured decision object decision = llm.invoke(supervisor_prompt).parse() #returning structured decision return {"next_step": decision.next_worker, ...}SQL Worker:Schema 感知查询引擎
SQL Worker 专注于确定性、结构化推理。
关键特性:
Schema 自省
SQL worker 会通过数据库元数据 API(比如,INFORMATION_SCHEMA)自动发现表与列。关系识别会通过两种机制来实现:一是元数据中的显式外键约束(作为权威依据);二是在缺少外键时,基于列命名规范的 LLM 启发式推断(比如,跨表匹配 customer_id)。
为降低推断关系带来的正确性风险,系统使用了多层防护:首先,实现置信度评分,基于字符串相似度与命名约定强度打分;低置信度的推断(相似度<0.8)不会自动使用,而是要求显式确认。其次,由 supervisor 仲裁:推断关系以“带置信度的候选建议”而非硬约束形式提交,需要 supervisor 逐条批准后才可生成查询。再次,做运行时验证:使用推断 join 的查询会先以行数受限的形式执行;如果结果异常(比如,空结果、笛卡尔积或类型不匹配),会触发 reflective retry 并提醒 supervisor 重审 join 的有效性。最后是显式外键优先:一旦元数据存在显式外键,相关表将完全跳过启发式推断阶段。
查询校验
生成的 SQL 在执行前会先基于 schema 进行校验。
方言优化
为生成特定数据库方言的 SQL(比如,Snowflake、Redshift、BigQuery),系统会把目标方言与 schema 上下文注入 LLM 提示词,并在执行前进行语法校验。复杂的方言特性(如 Snowflake 的 QUALIFY、BigQuery 的 STRUCT)是该方法的已知限制。reflective retry 能处理失败,但无法保证首轮就完全正确。对于严重依赖方言或合规敏感场景(例如,要求精确 QUALIFY 语义的监管财报、对 STRUCT 校验严格的医疗数据),团队可优先采用 connector 级模板或查询构建器(SQLAlchemy、dbt 等),由 Protocol-H 编排已验证的查询片段,而非从零生成 SQL。
工作流:

图 2:工作流
安全机制:
在 SQL 注入防护方面,系统通过参数化查询 API(比如,cursor.execute(query, params))执行 SQL,而不是字符串拼接,确保用户输入不会被当作可执行 SQL。行级访问控制方面,worker 使用已认证用户的凭据和会话上下文访问数据库,把权限控制交给数据库原生 RBAC,而不是在应用层重复实现。为防止出现失控的查询,每次执行都带有可配置的超时时间(默认 30 秒);超时后会取消查询并通知 supervisor 缩小范围重试或返回部分结果。
为保护内存,会限制结果的大小。查询结果在进入 LLM 上下文前会按可配置行数/字节上限截断,避免超大负载耗尽内存或超过 token 限制。
Vector Worker:语义检索智能体
vector worker 负责面向文档的语义推理。
关键特性:
语义检索通过查询向量化、检索向量索引并返回相关文档来实现。
混合检索将 BM25 关键词匹配与稠密向量余弦相似度结合,并通过 RRF(Reciprocal Rank Fusion)融合排序结果。该方案在精确性(精确词命中,比如,表名或产品码)与召回(概念相关的内容)之间取得了平衡,优于单一的方法。
相关性过滤通过阈值抑制伪匹配。
摘要步骤用于提取检索文档中的关键信息。
关键挑战:
当不存在相关文档时会出现冷启动的问题,worker 不会臆造结果,而是向 supervisor 返回显式的 null 信号,触发回退到 SQL 形式或向用户发起澄清。对于语义过宽、可能产生多种冲突解释的查询,worker 会将其标记为歧义,并把 Top-N 结果及其相关性分数交给 supervisor 仲裁,而非盲目合并。如果时效性非常重要(时间感知),可在相关分数中加入时间衰减因子,使近期报告、文件或工单优先。本文报告的 EntQA 测试未启用该能力;基准结果基于无时间加权的标准向量检索。
Reflective Retry 机制:自主的错误恢复
这正是 Protocol-H 与标准智能体系统的根本差异。当 worker 遇到错误时,系统不会把错误“包装成答案”继续传播,而是会进入 reflective retry 模式。
错误流
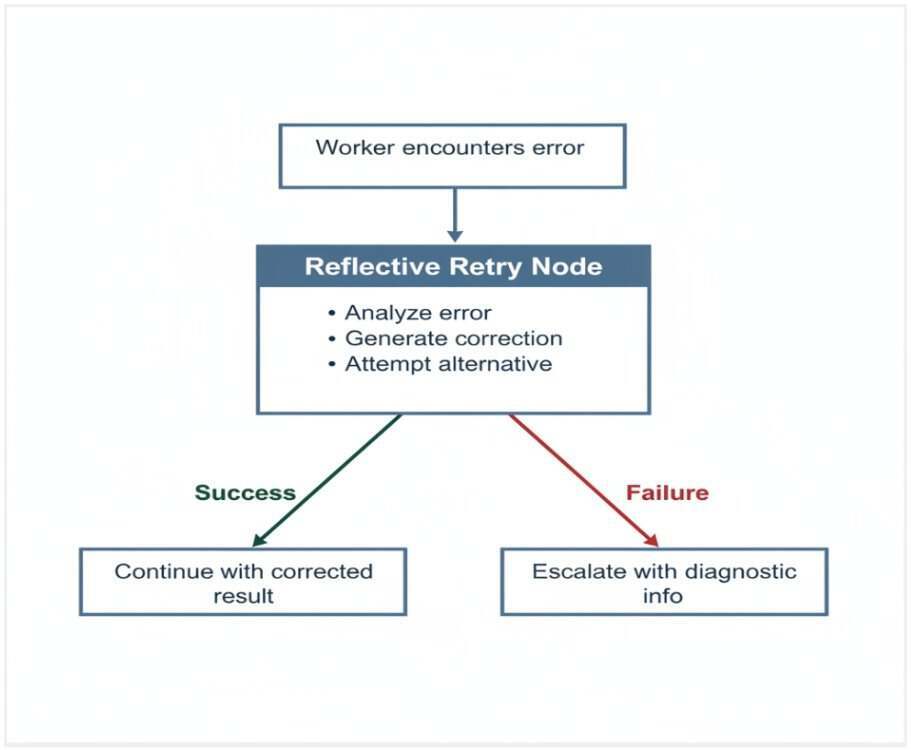
图 3:Reflective Retry 节点——Protocol-H 中的自主错误恢复流程
示例:SQL 语法错误恢复
from pydantic import BaseModelfrom typing import Optionalclass RetryCorrection(BaseModel): corrected_query: Optional[str] = None alternative_strategy: Optional[str] = Nonedef reflective_retry_node(state: AgentState) -> Dict[str, Any]: """ Autonomous error recovery mechanism. Returns: Dict containing corrected query or escalation signal. """ error_msg = state.error_message retry_prompt = f""" A query failed with this error: {error_msg} Original task: {state.current_task} Available schema: {schema_info} Analyze the error and suggest a corrected approach. Common issues: - Misspelled table/column names - Incorrect JOIN syntax - Missing WHERE clauses - Type mismatches Respond with: corrected_query or alternative_strategy """ # LLM returns a structured RetryCorrection object (Pydantic model) correction: RetryCorrection = llm.with_structured_output( RetryCorrection ).invoke(retry_prompt) # RetryCorrection has two optional fields: # - corrected_query: str → revised SQL to retry # - alternative_strategy: str → fallback if query can't be fixed return attempt_alternative_approach(correction)与标准 RAG 相比,这套机制使幻觉率下降约 60%(7.1%对 28.5%,见表 1)。但这并非 retry 机制单独的贡献,而是 Protocol-H 整体架构(supervisor-worker 拓扑、schema 感知查询生成和 reflective retry)协同作用的结果。通过这种集成设计,错误会在传播到最终答案生成前被捕获并修正。
理解 Protocol-H“为什么这样设计”只是第一步。上述 supervisor-worker 拓扑和 reflective retry 机制只有在确保同等健壮性的时候,才能实现其收益。接下来将展开介绍关键架构决策、状态管理、数据库抽象和 worker 的设计,说明如何把概念框架落成可用于生产环境的系统。
实现与集成:架构决策
使用 LangGraph 进行状态管理
Protocol-H 使用 LangGraph 的 StateGraph 进行确定性工作流编排:
class AgentState(TypedDict): messages: List[BaseMessage] # Conversation history next_step: Literal["supervisor", "sql_agent", "vector_agent", "FINISH"] final_answer: Optional[str] # Result when complete query_type: Optional[str] # "sql", "semantic", or "multi-modal" retry_count: int # Track retry attempts error_message: Optional[str] # Error context for debuggingStateGraph 保证的是图级别的确定性执行:在相同输入下,控制流图(访问哪些节点、按什么顺序访问)会保持一致(路由决策通过 temperature=0 约束)。确定性的部分包括:节点访问的顺序、状态迁移、重试触发逻辑,以及何时调用哪个 worker。非确定性的部分包括:worker 生成的具体文本(SQL、文档摘要、推理解释),这些内容即使输入相同也可能因 LLM 采样而产生变化。也就是说,编排逻辑与状态迁移可完全复现并可审计;worker 输出在结构上可复现,但不保证逐字一致性。
StateGraph 具备良好可审计性,可完整追踪决策与数据流;同时通过重试计数器与超时机制提升安全性,避免循环失控。
云中立的数据库适配器
通过 Adapter 模式,Protocol-H 对数据库差异做了抽象:
class BaseConnector(ABC): """Abstract interface for database connectors.""" @abstractmethod def get_schema(self) -> List[TableSchema]: """Get available tables and columns.""" pass @abstractmethod def execute_query(self, sql: str) -> QueryResult: """Execute SQL query safely.""" passclass SnowflakeConnector(BaseConnector): """Snowflake-specific implementation. Handles Snowflake dialect differences: - Identifiers are UPPERCASE by default - Uses LIMIT instead of TOP for row capping - Supports QUALIFY for window function filtering """ def get_schema(self) -> List[TableSchema]: # Snowflake stores metadata in INFORMATION_SCHEMA # Identifiers must be uppercased for reliable matching result = self.connection.execute(""" SELECT TABLE_NAME, COLUMN_NAME, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA = UPPER(:schema) """, {"schema": self.schema_name}) return [TableSchema.from_row(row) for row in result] def execute_query(self, sql: str) -> QueryResult: # Simplified illustration: production implementations should use # cursor-based fetch limits or dialect-specific query hints rather # than string wrapping, which can alter query semantics for # statements with ORDER BY, existing LIMIT clauses, or CTEs. # See SnowflakeConnector in the repository for production-grade # implementation using cursor.fetchmany(). safe_sql = f"SELECT * FROM ({sql}) LIMIT {self.max_rows}" return QueryResult(rows=self.connection.execute(safe_sql).fetchall()))class RedshiftConnector(BaseConnector): """Amazon Redshift implementation. # Dialect note: uses pg_catalog instead of INFORMATION_SCHEMA # and does not support QUALIFY — handled via subquery workaround """ def execute_query(self, sql: str) -> QueryResult: # Redshift dialect handling pass这种设计使团队可以在不修改编排逻辑的前提下替换数据库后端,这对异构基础设施企业非常重要。在实践中,各个 connector 会在内部处理方言差异(例如,Snowflake 的大写标识符、Redshift 的 pg_catalog 元数据、BigQuery 的嵌套 STRUCT 类型),从而让 supervisor 和 worker 始终面向统一的 QueryResult 接口。但它仍有一定的局限性:高度依赖方言的特性(比如,Snowflake 的 QUALIFY、BigQuery 的 ARRAY_AGG、Redshift 的 DISTKEY hint)通常需要 connector 级定制,无法实现自动抽象。团队在新数据库后端接入 Protocol-H 时,应先审计这些边界场景再假定可完全地移植。
专用 Worker 智能体
每个 worker 都运行自己的 ReAct 循环(推理与行动):
def sql_worker_node(state: AgentState) -> Dict[str, Any]: """SQL Worker runs ReAct: Thought → Action → Observation.""" # Step 1: Thought (structured reasoning) reasoning_prompt = f""" User asks: {state.current_question} Available tables: {schema} Respond with a structured reasoning object containing: - sql_query: the SQL to execute - explanation: reasoning for the query choice - confidence: self-assessed confidence score (0-1) """ reasoning: SQLReasoning = llm.with_structured_output(SQLReasoning).invoke(reasoning_prompt) # Step 2: Action (execute SQL) query_result = db.execute(reasoning.sql_query) # Step 3: Observation (process results) formatted_result = format_for_synthesis(query_result) return { "messages": [..., ToolMessage(content=formatted_result)], "next_step": "supervisor" }基准测试结果
本次评估比较了以下方法。
Protocol-H 在 EntQA 基准上进行评估。该基准包含 200 道企业问题,需要同时在 SQL 与文档数据上进行多跳推理。
Protocol-H:即本文描述的分层 supervisor-worker 架构,带有 reflective retry 功能。
同时,评估了扁平化的智能体,也就是,单个通用 LLM 智能体可以访问 SQL 和向量检索工具,但不具备分层编排和专用 worker。这代表了最常见的“把所有工具都交给 LLM”的方案。
最后评估的是标准 RAG,这是一个传统的“先检索后生成”流程(向量化查询→检索文档→交给 LLM→生成答案),不具备 agentic 推理和 SQL 能力。
性能对比
表 1:性能对比
“推理步数”指系统在生成最终答案前触发的独立工具调用次数(SQL 查询或向量检索)。数值越高,通常表示多跳推理更充分;数值越低,往往表示系统尝试了更少的轮次就尝试给出答案,在该基准中这会与更高的幻觉率密切相关。
基准方法论
EntQA 是 Protocol-H 团队内部构建的基准,用于评估异构企业数据上的多跳推理能力。它目前并不是公开的基准,但为了保证可复现性,评估脚本与匿名化问题集已放在Protocol-H仓库)中。
该数据集包含 200 道企业问题,分为三个复杂度层级。Tier 1(简单,n=60):单模态问题,一次 SQL 或一次向量检索即可解决;Tier 2(中等,n=80):需要一次 SQL 和一次向量检索并做基础汇总;Tier 3(复杂,n=60):需要跨两种模态进行 3 步及以上的多跳推理,并进行跨模态汇总(例如,“哪些客户分群流失率最高,他们的工单揭示了什么根本原因?”)。
本文中所有的准确率数据均针对 Tier 3 的问题,即最难、也最贴近企业真实需求的子集。
测试配置:
LLM:GPT-4o(三套系统统一使用,以隔离编排差异的影响)
Embedding 模型:text-embedding-3-large(OpenAI)
向量库:Pinecone(standard tier)
SQL 后端:Snowflake Enterprise
硬件:Docker 容器,4 vCPU / 16GB RAM
评估方式:由 GPT-4o 对照标准答案打分,并对 20%响应做人类抽检。局限:GPT-4o 既是三套系统的推理引擎又是评估器,可能引入循环偏差;基于人类抽检校验评估可靠性。
可复现性:完整评估脚本、提示词和标准答案已在仓库提供。说明:EntQA 所用的企业数据源没有公开,复现实验需使用具有类似 schema 复杂度的 SQL/向量数据集。
关键发现
准确率提升
与扁平化的智能体相比,分层路由在多跳准确率上相对提升了 34.6%(84.5% vs 62.8%);与标准 RAG 相比相对提升 87.0%(84.5% vs 45.2%)。换算为绝对值,分别提升 21.7 和 39.3 个百分点。
延迟方面的权衡
Protocol-H 的 p95 延迟为 2.1 秒,相比标准 RAG(0.8 秒)慢约 1.3 秒,相比扁平化的智能体(1.4 秒)慢约 0.7 秒,主要是由更高的推理步数(3.2 vs 1.0 vs 1.8)导致的。这是多跳推理的直接成本。作为参照,同步仪表盘查询通常可接受 2-3 秒的响应,因此 Protocol-H 对多数分析型负载仍在可接受的范围之内。
对于延迟敏感的场景(比如,面向客户的实时应用),建议采用基于 webhook 的异步模式。以 2.1 秒延迟换来 21.7%的准确率提升,在“决策质量优先于速度”的企业分析场景中这通常是更优的权衡。
健壮性
在高错误率查询(有意制造的 schema 不匹配)方面,Protocol-H 的正确恢复率为 89%,而扁平化的智能体仅为 12%。
生产环境的部署考量
安全与合规性
企业部署不仅要准确率,还要确保安全与可治理。Protocol-H 在这方面实现了:
确定性的控制流
StateGraph 保证执行路径可复现,这对合规审计至关重要。
Schema 感知
初始化时,每个 worker 都会读取数据库元数据(如 INFORMATION_SCHEMA),构建在已认证用户 RBAC 权限范围内可访问表/列的运行时映射。worker 只会针对可证实有权限的数据生成查询,从执行前就阻断未授权的访问。
策略控制
团队可在 schema_policy.yaml 中定义额外的业务规则(比如,exclude_tables: ['pii_raw']),在数据库权限之外再加一层数据边界控制,适用于多租户部署或监管分区场景。
错误诊断
系统会返回完整的上下文解释“为何会失败”,而不是直接给出幻觉化的答案。
限流
限流可防止智能体失控并保护基础设施。
结果校验
在结果返回给 supervisor 前,worker 输出会经过可配置的校验层,对如下情况进行检查:数值异常(如营收超阈值)、NULL 主导结果(如超过 80%为 NULL,提示 schema 不匹配)、按上下文不应为空却为空的结果集,以及预期类型与返回类型不一致。校验失败时会触发 Reflective Retry Node,而不是把可疑数据继续传递到最终答案。
部署模式
同步 API
def create_orchestrator( db_connector: BaseConnector, vector_store: VectorStoreClient, policy_path: str = "config/schema_policy.yaml", llm_model: str = "gpt-4o", max_retries: int = 3) -> ProtocolHOrchestrator: """ Initializes the Protocol-H orchestration layer: - Loads schema_policy.yaml for access control rules - Instantiates the database connector (e.g., SnowflakeConnector) - Initializes the vector store client (e.g., Pinecone) - Wires Supervisor, SQL Worker, and Vector Worker into the StateGraph """ ...def get_compiled_app(self) -> CompiledStateGraph: """ Compiles the StateGraph into an executable LangGraph app: - Validates node connections and edge definitions - Freezes the graph structure for deterministic execution - Returns a runnable object supporting .invoke() and .invoke_async() """ ...# --- Usage Example ---from protocol_h.connectors import SnowflakeConnectorfrom protocol_h.vector import PineconeClient# Initialize required connectorsdb = SnowflakeConnector( account="your_account", warehouse="your_warehouse", role="analyst_role")vector_store = PineconeClient(index_name="enterprise_docs")# Create orchestrator with required dependenciesorchestrator = create_orchestrator( db_connector=db, vector_store=vector_store)app = orchestrator.get_compiled_app()result = app.invoke({ "messages": [HumanMessage(content="What's our top customer segment by revenue?")], "next_step": "supervisor",})print(result["final_answer"])基于 Webhook 的异步方式
# For longer-running queries, use LangGraph's native async APIimport asyncioresult = await app.ainvoke({ "messages": [...], "next_step": "supervisor",})Docker 容器化
# Stage 1: Build --- install dependencies in isolated layerFROM python:3.11-slim AS builderWORKDIR /appCOPY requirements.txt.RUN pip install --no-cache-dir --user -r requirements.txt# Stage 2: Runtime --- lean final imageFROM python:3.11-slimWORKDIR /app# Install curl for health check (not included in slim images)RUN apt-get update && apt-get install -y --no-install-recommends curl \ && rm -rf /var/lib/apt/lists/*# Security best practice: run as non-root userRUN useradd --create-home appuserUSER appuser# Copy only installed packages and app code from builderCOPY --from=builder /root/.local /home/appuser/.localCOPY src/ /app/srcCOPY config/ /app/config# Pass secrets via environment (injected at runtime by orchestrator/K8s)ENV OPENAI_API_KEY=${OPENAI_API_KEY}ENV SNOWFLAKE_ACCOUNT=${SNOWFLAKE_ACCOUNT}# Health check: verify the app is responsive every 30sHEALTHCHECK --interval=30s --timeout=10s --retries=3 \ CMD curl -f http://localhost:8000/health || exit 1CMD ["python", "main.py"]常见的挑战与解决方案:Schema 漂移
企业数据库会持续演进,比如,列重命名、表废弃、引入新的业务逻辑。
Protocol-H 通过两种互补机制应对 schema 的漂移。第一是周期性的 schema 校验,应用运行时的轻量级后台线程会按照可配置的周期(默认 24 小时,或在出现“unknown column”错误时触发)重新抓取INFORMATION_SCHEMA元数据,并更新各 worker 内存中的 schema 映射。高可用部署中,也可改用 Kubernetes CronJob 或外部调度器实现,避免实例级轮询。
第二是基于替代建议的优雅错误处理。worker 在查询时遇到“unknown column”不会静默失败,而会触发恢复流程,也就是,先对当前 schema 做模糊匹配(例如,识别profit_margin已改名为net_margin),通过字符串相似度打分;如果命中高置信的候选者(>0.8),会把建议列名连同原始错误上下文(如“Column profit_margin not found - did you mean net_margin?”)提交给 supervisor。随后由 supervisor 决定按建议重试、请求澄清还是将问题升级给用户;如果没有命中候选者,则附带完整诊断信息通知 supervisor 改写查询或告知用户存在数据不匹配的问题。
这种做法避免了 schema 漂移变成“静默失败”。每一次漂移相关的错误都会产出可执行的信号,而不是幻觉化的答案。
复杂 Join 下的幻觉问题
当查询涉及 3 张及以上表的连接时,LLM 有时会生成错误的 join 条件。
reflective retry 机制可以通过捕获失败查询并建议替代 join 策略,或将查询拆分成更小的步骤来解决该问题。
多跳场景下的延迟
每增加一步推理都会引入增量延迟。在需要 3-5 步串行推理的多跳场景中,总查询延迟可能超过同步交互界面的容忍阈值。
解决方式包括,对常见子查询进行结果缓存,在步骤相互独立时进行并行执行。
Protocol-H 通过 LangGraph 的 Send API 支持该模式,同时保持确定性的图结构。这里的“确定性”指编排逻辑(哪些节点执行、执行顺序)可复现,而非必须串行执行。如果一个查询同时需要 SQL 聚合和向量检索且两者无依赖,supervisor 会并行分派给两个 worker,再在确定性的同步点汇合结果后做最终汇总。也就是说,控制流图仍完全可复现,只在 worker 层执行并行化。(见图 1 中的并行 worker 路径)。
还应缓存 schema 信息以避免重复自省:schema 元数据按可配置 TTL(默认 24 小时)缓存,并与 Schema Drift 章节中的校验周期保持一致,确保缓存与漂移检测同步。缓存失效与刷新节奏与后台 schema 校验一致,从而在性能(减少会话内重复INFORMATION_SCHEMA查询)与新鲜度(保证 worker 不使用超过 TTL 窗口的旧 schema)之间取得平衡。
成本管理
每次智能体调用都要触发 LLM,规模化后成本会明显累积。
为了控制成本,可以采用更快更便宜的模型做路由决策(比如,supervisor 使用 GPT-4o mini)。这是面向未来成本优化的通用架构建议。需要强调的是,本文基准结果(84.5%准确率、7.1%幻觉率)均来自统一使用 GPT-4o 的 supervisor 和 worker。我们尚未正式评估混合模型配置下的成本/准确率权衡;采用该模式的团队应先结合自身的准确率门槛完成验证,再进行规模化部署。另外,可以对相同查询缓存推理结果,并批处理相似查询以提升效率。
经验总结
专业化优于泛化
专用的 SQL 和 Vector worker 在各自模态上持续优于单一的通用智能体:SQL worker 擅长结构化推理,vector worker 擅长语义检索。这种专业化会在端到端上形成复利化的收益。
错误恢复至关重要
在内部测试中(n≈1500,覆盖三套金融服务部署,Q4 2025),对幻觉响应的错误分析显示:大约 60%并非源于 LLM 基础推理能力不足,而是来自未处理执行错误、SQL 失败、向量检索为空或 schema 不匹配,并被静默传播到最终答案阶段。这意味着恢复机制的价值极高:仅通过修复错误处理,就能覆盖大部分幻觉问题,而不必升级模型。
Schema 感知是关键
理解可用数据边界(schema 与访问控制)的 worker,比只处理原始数据的 worker 能做出更好的决策。
确定性带来信任
企业往往把“可复现执行”看得比“最大化准确率”更重要,因此确定性工作流编排是生产级智能体系统的关键设计要求。StateGraph 的图级确定性(相同输入下节点访问顺序与状态迁移一致)提供了这种可复现性。具体来说,Protocol-H 会为每次决策生成可追踪的审计日志:调用了哪些 worker、顺序如何、输入是什么。对于受 SOC 2、GDPR 或内部模型治理约束的企业团队,这种可复现能力是刚需,它能把答案追溯到具体数据来源和推理步骤,使合规审计相较非确定性系统更具可操作性。
多模态推理需要编排
没有单一的智能体能够同时在 SQL 与语义数据上都推理得足够好,分层委派是必需的。
未来展望
本文框架是当前企业级 agentic RAG 实践的一个阶段性切片。后续重点研究方向包括:
自适应路由
研究目标是学习“不同查询类型最有效的 worker 组合”。当前主要在探索两条互补的路径。第一是查询日志分析:挖掘历史执行轨迹,找出与高准确性、低重试相关的 supervisor 路由决策,再将这些模式反馈到未来路由(例如,“财务的阶段性问题通常先需要 SQL,再执行向量检索以补全上下文”)。第二是轻量 RL 优化:把 supervisor 路由决策建模为可优化的策略,以“答案准确率+幻觉率+查询延迟”的组合作为奖励信号,让系统在无需人工调参下逐步学习查询类型的特定路由。两者仍处于早期研究阶段;考虑到实现的复杂度,日志分析是更接近阶段性可落地的路径。
语义化缓存
缓存向量检索结果,减少重复 embedding 计算。
跨模态融合
探索更高级的 SQL 证据与语义证据融合方法。
可解释性
为多跳的推理路径生成人类可读的阐述形式,这可能是企业采用的最关键前沿领域。当前 Protocol-H 能输出完整的执行轨迹(调用了哪些 worker、顺序如何、输入输出是什么),但这仍是技术日志,不是业务可读的阐述形式。下一步是把轨迹转成自然语言推理摘要,例如:“为回答你关于欧洲业务表现不佳的问题,我先按地区查询营收与利润率数据(SQL),再检索欧盟最新监管文件和市场报告(向量检索),并发现德国利润率下滑与 2024 年 Q3 三份监管文档提到的新 VAT 合规成本相关”。这种透明度对分析师信任、合规性审计和模型治理都至关重要。欧盟 AI 法案对高风险 AI 系统要求保留系统运行日志(第 12 条),其中就包括决策的可追溯性。
结论
企业 RAG 中的“模态鸿沟”(结构化与非结构化数据协同)本质上不是单纯的技术能力不足,而是编排方面的挑战。Protocol-H 证明,具备自主错误恢复的分层多智能体系统可以达到企业级准确性、安全性和可审计性。
通过职责分离(supervisor 负责编排、worker 负责专长执行)并实现 reflective retry 机制,团队可以构建在异构企业数据上稳定推理的 agentic 系统,同时满足确定性与合规要求。
对构建企业级 agentic 系统的团队而言,核心架构原则很简单:先编排再委派,先专业化再泛化,先恢复再传播错误。带自主纠错的分层多智能体设计,能够在异构数据模态上实现可靠推理,弥合理论能力与生产可用之间的鸿沟。参考实现 Protocol-H 已经在实践中验证了这些原则,也为团队按自身基础设施和合规需求做二次落地提供了基础。
代码示例:本文所有代码片段均来自 Protocol-H 框架的原始 Python 实现。
参考资料:
GPT-4o (gpt-4o-2024-08-06) — 用于 Worker 推理
GPT-4o mini (gpt-4o-mini-2024-07-18) — 推荐用于 Supervisor 路由
text-embedding-3-large — 用于向量 embedding
Snowflake Connector for Python v3.x—Python Connector
注意:版本号对应基准测试时所用版本(Q4 2025)。
开源仓库可以参见此处。
原文链接:
Building Hierarchical Agentic RAG Systems: Multi-Modal Reasoning with Autonomous Error Recovery




